限流算法
固定时间窗口算法
将时间分成固定的窗口,将请求按照时间顺序放入对应时间窗口中,如果该时间窗口内的请求数量超出了限制,则拒绝该请求。
算法举例
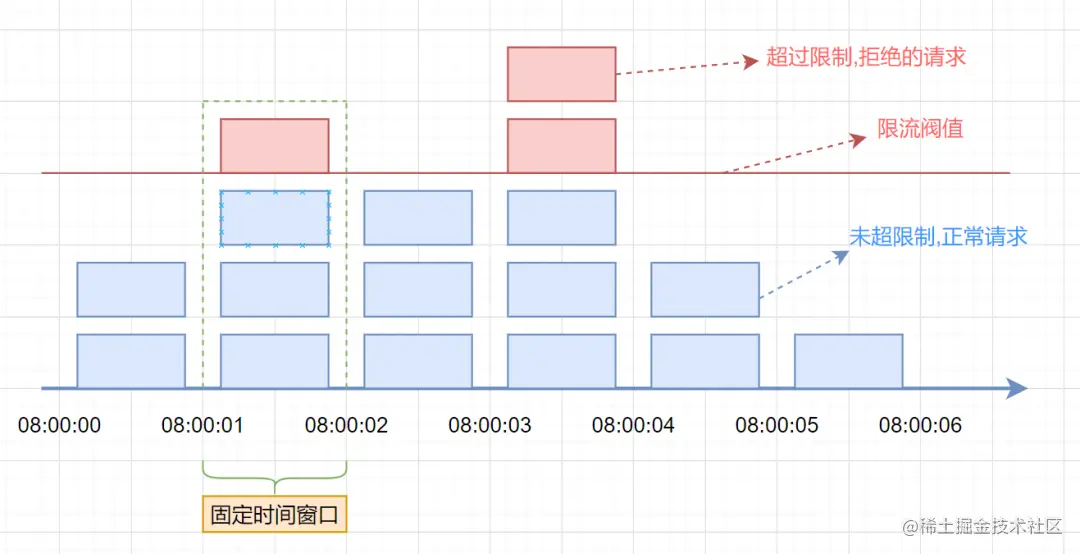
假设单位时间(固定时间窗口)是1秒,限流阀值为3。在单位时间1秒内,每来一个请求,计数器就加1,如果计数器累加的次数超过限流阀值3,后续的请求全部拒绝。等到1s结束后,计数器清0,重新开始计数。如下图:
算法优缺点
优点:简单
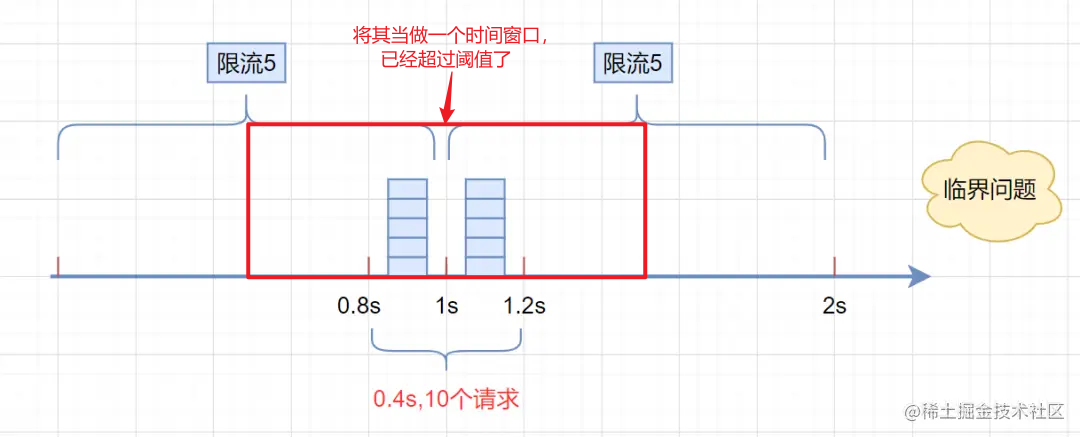
缺点:存在明显的临界问题,在两个时间窗口的边界,可能出现两倍阈值请求,如果可以接受,那么这个算法是较优选择。
实现思路
也可通过redis实现,userId,用户IP等作为key,value统计次数,设置过期时间作为时间窗口
- 如果redis不存在
- 添加键值对,value置为1,设置一定的过期时间(时间窗口)
- 如果redis存在
- 如果次数到达阈值,返回请求失败;如果次数未到达阈值,value+1,继续执行
public static Integer counter = 0; //统计请求数
public static long lastAcquireTime = 0L;
public static final Long windowUnit = 1000L ; //假设固定时间窗口是1000ms
public static final Integer threshold = 10; // 窗口阀值是10
public synchronized boolean fixedWindowsTryAcquire() {
long currentTime = System.currentTimeMillis(); //获取系统当前时间
if (currentTime - lastAcquireTime > windowUnit) { //检查是否在时间窗口内
counter = 0; // 计数器清0
lastAcquireTime = currentTime; //开启新的时间窗口
}
if (counter < threshold) { // 小于阀值
counter++; //计数统计器加1
return true;
}
return false;
}滑动时间窗口算法
它将单位时间周期分为n个小周期,分别记录每个小周期内接口的访问次数,并且根据时间滑动删除过期的小周期。它可以解决固定窗口临界值的问题。
算法举例
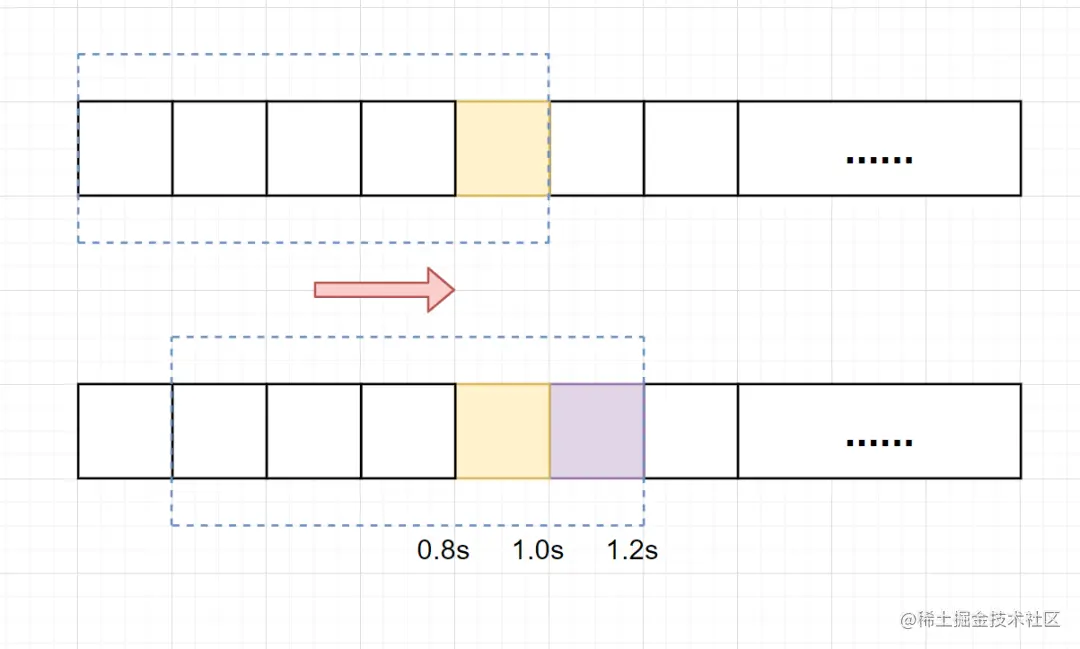
假设单位时间还是1s,滑动窗口算法把它划分为5个小周期,也就是滑动窗口(单位时间)被划分为5个小格子。每格表示0.2s。每过0.2s,时间窗口就会往右滑动一格。然后呢,每个小周期,都有自己独立的计数器,如果请求是0.83s到达的,0.8~1.0s对应的计数器就会加1。
算法优缺点
优点:
- 精度高(通过调整时间窗口的大小来实现不同的限流效果)
- 可扩展性强(可以非常容易地与其他限流算法结合使用)
缺点:
- 突发流量无法处理(无法应对短时间内的大量请求,但是一旦到达限流后,请求都会直接暴力被拒绝。),需要合理调整时间窗口大小。
实现思路
使用redis的Zset代替Treemap同样可以实现限流,逻辑和下方一样
/**
* 单位时间划分的小周期(单位时间是1分钟,10s一个小格子窗口,一共6个格子)
*/
private int SUB_CYCLE = 10;
/**
* 每分钟限流请求数
*/
private int thresholdPerMin = 100;
/**
* 计数器, k-为当前窗口的开始时间值秒,value为当前窗口的计数
*/
private final TreeMap<Long, Integer> counters = new TreeMap<>();
/**
* 滑动窗口时间算法实现
*/
public synchronized boolean slidingWindowsTryAcquire() {
//获取当前时间对应小周期窗口开始时间
// LocalDateTime.now().toEpochSecond(ZoneOffset.UTC) :将当前时间转化为秒数,设:1696167296设
// /SUB_CYCLE:因为计算会舍去小数,所以得到了当前处于第几个时间窗口,结果为:1696167296/10=169616729
// * SUB_CYCL:乘以每一个窗口的长度,得到当前时间窗口的开始时间,169616729 * 10 = 1696167290
long currentWindowTime = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC) / SUB_CYCLE * SUB_CYCLE;
//当前窗口总请求数
int currentWindowNum = countCurrentWindow(currentWindowTime);
//超过阀值限流
if (currentWindowNum >= thresholdPerMin) {
return false;
}
//计数器+1
counters.get(currentWindowTime)++;
return true;
}
/**
* 统计当前窗口的请求数
*/
private synchronized int countCurrentWindow(long currentWindowTime) {
//计算窗口开始位置
// 60 / SUB_CYCLE:计算一个单位时间(1分钟)内包含多少个小周期窗口。设SUB_CYCLE,结果是 6。
// 60 / SUB_CYCLE - 1:计算当前时间窗口之前的所有小周期窗口的数量。结果是 5,因为当前时间窗口没有被计算进入。
// SUB_CYCLE * (60 / SUB_CYCLE - 1):计算当前时间窗口之前的所有小周期窗口的总时间长度。结果是 50 秒。
// currentWindowTime - SUB_CYCLE * (60 / SUB_CYCLE - 1):计算滑动窗口的起始时间。设currentWindowTime 是 1696167290结果是 1696167240。
long startTime = currentWindowTime - SUB_CYCLE* (60s/SUB_CYCLE-1);
int count = 0;
//遍历存储的计数器
Iterator<Map.Entry<Long, Integer>> iterator = counters.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Long, Integer> entry = iterator.next();
// 删除无效过期的子窗口计数器
if (entry.getKey() < startTime) {
iterator.remove();
} else {
//累加当前窗口的所有计数器之和
count =count + entry.getValue();
}
}
return count;
}
漏斗算法
算法举例
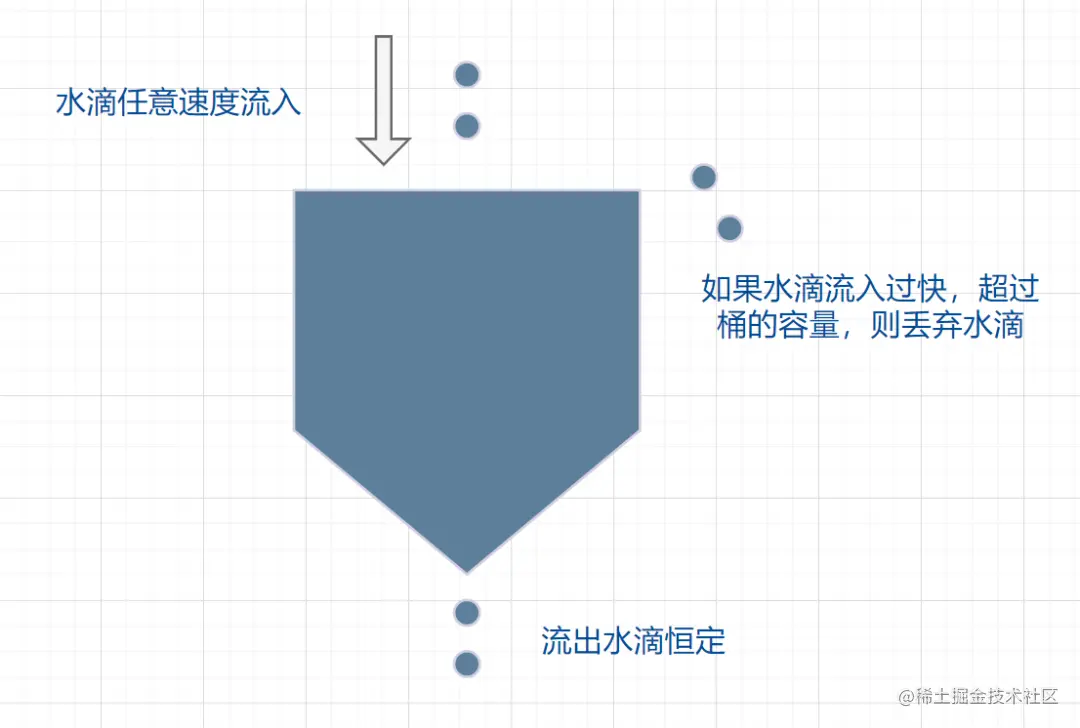
- 流入的水滴,可以看作是访问系统的请求,流入速率是不确定的。
- 桶的容量一般表示系统所能处理的请求数。
- 如果桶的容量满了,就达到限流的阀值,就会丢弃水滴(拒绝请求)
- 流出的水滴,是恒定过滤的,对应服务按照固定的速率处理请求。
算法优缺点
优点
- 可以平滑限制请求的处理速度,避免瞬间请求过多导致系统崩溃或者雪崩。
- 可以通过调整桶的大小和漏出速率来满足不同的限流需求,可以灵活地适应不同的场景。
缺点
- 需要对请求进行缓存,会增加服务器的内存消耗。
- 不允许突发流量,只能稳定流量输出
实现思路
类似于消息队列,我们可以使用redis中的list来实现
- 当请求到达时,如果list不存在,则创建list,并将请求放入。
- 如果list存在,若未超过桶的限制,则放入,若超过则丢弃
- 消费者以恒定的速度从桶中消费请求
/**
* LeakyBucket 类表示一个漏桶,
* 包含了桶的容量和漏桶出水速率等参数,
* 以及当前桶中的水量和上次漏水时间戳等状态。
*/
public class LeakyBucket {
private final long capacity; // 桶的容量
private final long rate; // 漏桶出水速率
private long water; // 当前桶中的水量
private long lastLeakTimestamp; // 上次漏水时间戳
public LeakyBucket(long capacity, long rate) {
this.capacity = capacity;
this.rate = rate;
this.water = 0;
this.lastLeakTimestamp = System.currentTimeMillis();
}
/**
* tryConsume() 方法用于尝试向桶中放入一定量的水,如果桶中还有足够的空间,则返回 true,否则返回 false。
* @param waterRequested
* @return
*/
public synchronized boolean tryConsume(long waterRequested) {
leak();
if (water + waterRequested <= capacity) {
water += waterRequested;
return true;
} else {
return false;
}
}
/**
* 。leak() 方法用于漏水,根据当前时间和上次漏水时间戳计算出应该漏出的水量,然后更新桶中的水量和漏水时间戳等状态。
*/
private void leak() {
long now = System.currentTimeMillis();
long elapsedTime = now - lastLeakTimestamp;
long leakedWater = elapsedTime * rate / 1000;
if (leakedWater > 0) {
water = Math.max(0, water - leakedWater);
lastLeakTimestamp = now;
}
}
}令牌桶算法
算法举例
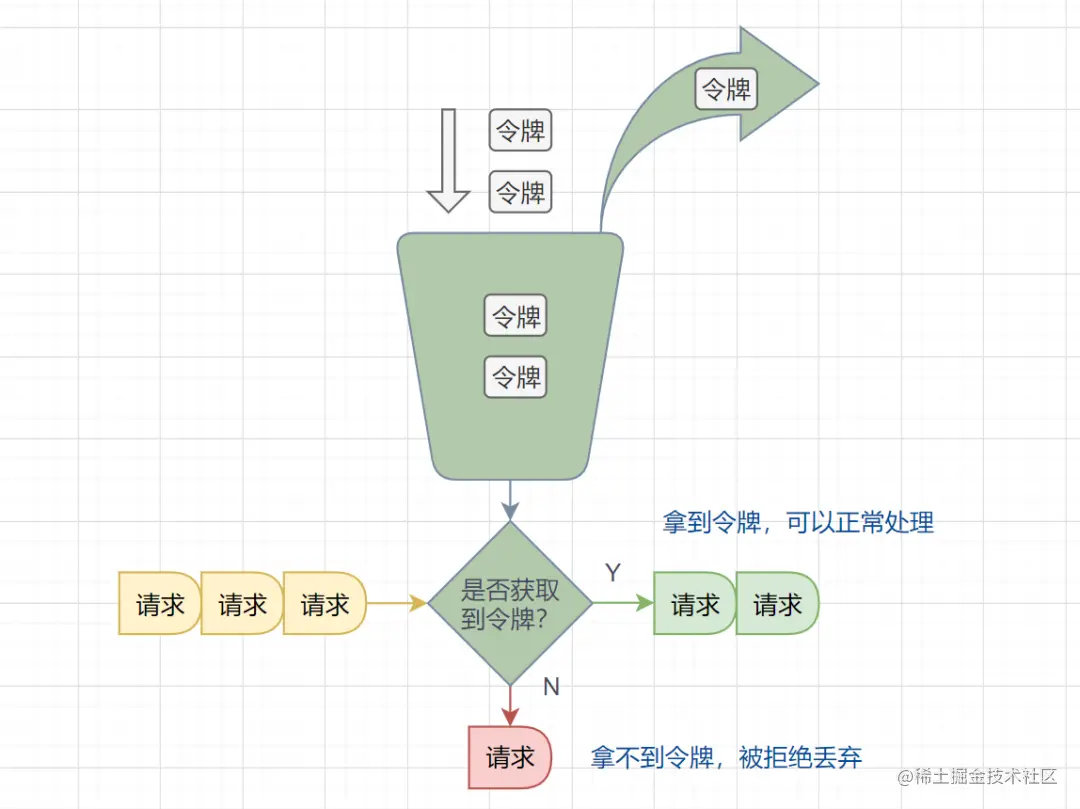
维护一个固定容量的令牌桶,每秒钟会向令牌桶中放入一定数量的令牌。当有请求到来时,如果令牌桶中有足够的令牌,则请求被允许通过并从令牌桶中消耗一个令牌,否则请求被拒绝。
算法优缺点
优点:
- 弹性好:允许一定程度的突发流量,这是和漏斗算法的主要区别
缺点:
- 对短时请求难以处理:在短时间内有大量请求到来时,可能会导致令牌桶中的令牌被快速消耗完,从而限流。这种情况下,可以考虑使用漏桶算法。
实现思路
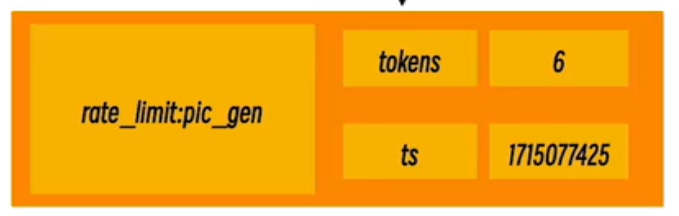
在redis中通过创建如下结构可以同样可以实现
/**
* TokenBucket 类表示一个令牌桶
*/
public class TokenBucket {
private final int capacity; // 令牌桶容量
private final int rate; // 令牌生成速率,单位:令牌/秒
private int tokens; // 当前令牌数量
private long lastRefillTimestamp; // 上次令牌生成时间戳
/**
* 构造函数中传入令牌桶的容量和令牌生成速率。
* @param capacity
* @param rate
*/
public TokenBucket(int capacity, int rate) {
this.capacity = capacity;
this.rate = rate;
this.tokens = capacity;
this.lastRefillTimestamp = System.currentTimeMillis();
}
/**
* allowRequest() 方法表示一个请求是否允许通过,该方法使用 synchronized 关键字进行同步,以保证线程安全。
* @return
*/
public synchronized boolean allowRequest() {
refill();
if (tokens > 0) {
tokens--;
return true;
} else {
return false;
}
}
/**
* refill() 方法用于生成令牌,其中计算令牌数量的逻辑是按照令牌生成速率每秒钟生成一定数量的令牌,
* tokens 变量表示当前令牌数量,
* lastRefillTimestamp 变量表示上次令牌生成的时间戳。
*/
private void refill() {
long now = System.currentTimeMillis();
if (now > lastRefillTimestamp) {
int generatedTokens = (int) ((now - lastRefillTimestamp) / 1000 * rate);
tokens = Math.min(tokens + generatedTokens, capacity);
if(generatedTokens!=0)
lastRefillTimestamp = now;
}
}
}CAP与BASE理论
CAP
概述
对于分布式系统而言,分区容错性,一致性,可用性最多可以满足其二,不存在CAP。
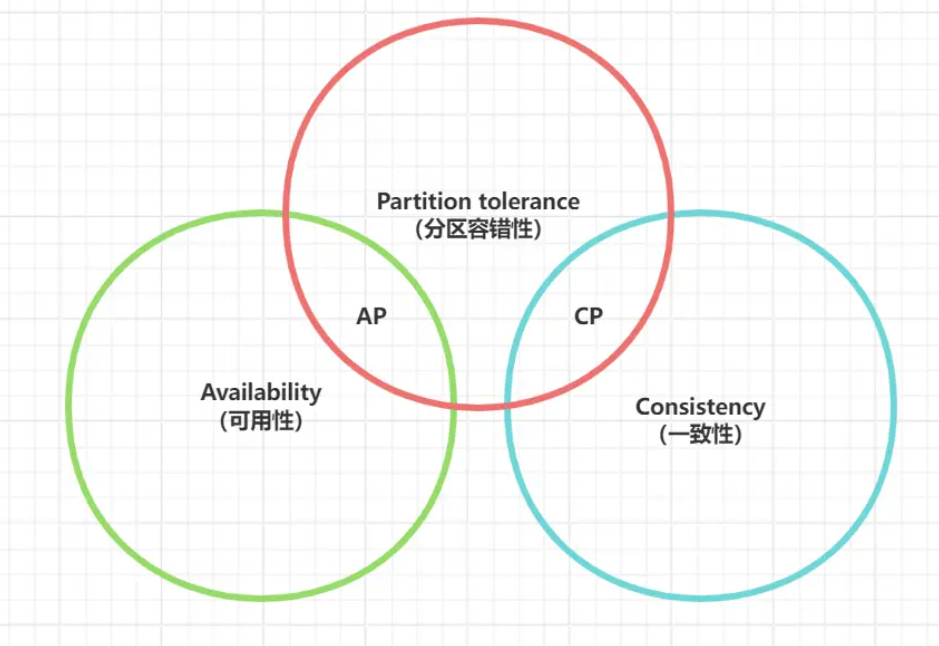
C (一致性)
在分布式系统中,所有节点数据在同一时刻执行相同的查询返回相同的值,如果某一个节点被修改,查询其他节点也要返回修改后的值。
A (可用性)
无论系统内部发生什么,系统提供的服务必须一直处于可用的状态,每次只要收到用户的请求,服务器就必须给出回应。在合理的时间内返回合理的响应(不是错误和超时的响应)
P (网络分区容错性)
网络节点之间无法通信的情况下,节点被隔离,产生了网络分区, 仍然保持一定可用性 。因为新节点加入和老节点离开,都可以视为系统内部的网络分区,
CAP里的分区容错性,本质就是分布式系统对节点动态加入和离开的处理能力!
组合选择
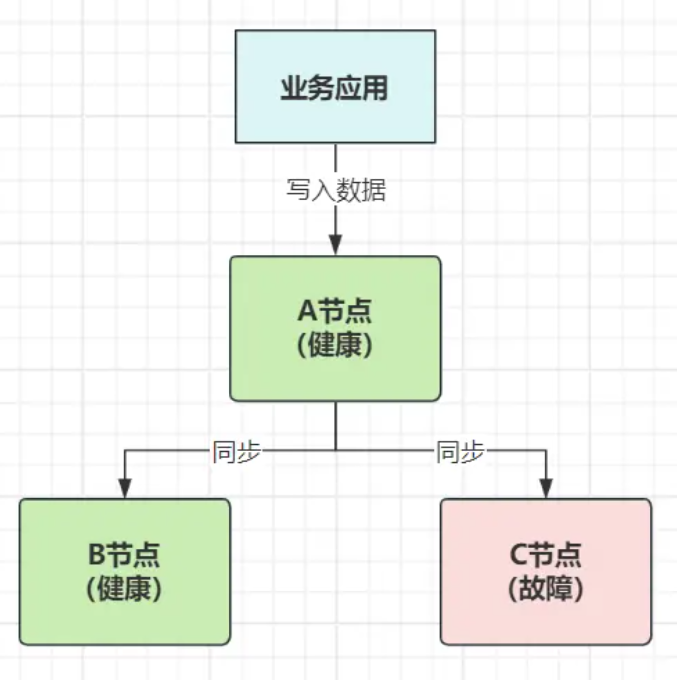
网络无法 100% 可靠,所以P是必须的,则需要在C和A之间进行取舍,下方系统由A、B、C三个节点组成,其中由于C节点故障导致分区问题出现。
- ①放弃可用性:等待所有节点的数据都达到一致状态,保证任意节点返回的数据都相同,可这时系统必然无法及时响应;
- ②放弃一致性:给客户端返回已经写入进
A、B的新数据,但后续C节点恢复,请求去到C时,会出现读取到的数据不一致;
业务系统本身只有逻辑处理,没有数据存储,自然不存在所谓的数据一致性。真正需要实践CAP理论的分布式系统,主要是带存储性质的分布式系统,如Redis、MQ、数据库、注册中心……
- 如果更关注性能,可以选择
AP类型的组件,毕竟AP舍弃了数据一致性,只需等数据写入主节点,就可以向客户端返回写入成功。如果数据刚写进主节点,还没来得及同步给从机,主节点就宕机了,此时切换上来的新主,就会丢失这部分数据。 - 如果更关注数据安全性,则可选用
CP类型的组件,CP放弃了可用性,优先保证数据一致性,当数据写进主节点后,往往需要等到从节点也写入完成,最后才能给客户端返回写入成功,因为从机未写入成功,请求则需要一直阻塞等待。如果当主节点宕机时,无论是哪台从机成为新主,都能保证拥有最完整的数据,不会存在数据丢失现象。 - 分布式系统不可能选择CA,因为一个节点出现问题,整个系统将无法使用。说白了,就是一个整体的应用,只能被称为“部署在多个节点上的单体系统”。
- 通过传统的数据库,搭建多库架构(主从、多主)时,选择同步复制,说明更关注数据一致性(CP);选择异步复制,则代表更关注响应速度(AP)
- 使用分布式锁时,在
Redis、Zookeeper都为主从集群模式的情况下,如果选择Redis来实现分布式锁,代表更关注响应速度(AP);如果选用ZK来实现,则代表更关注一致性(CP)
BASE理论
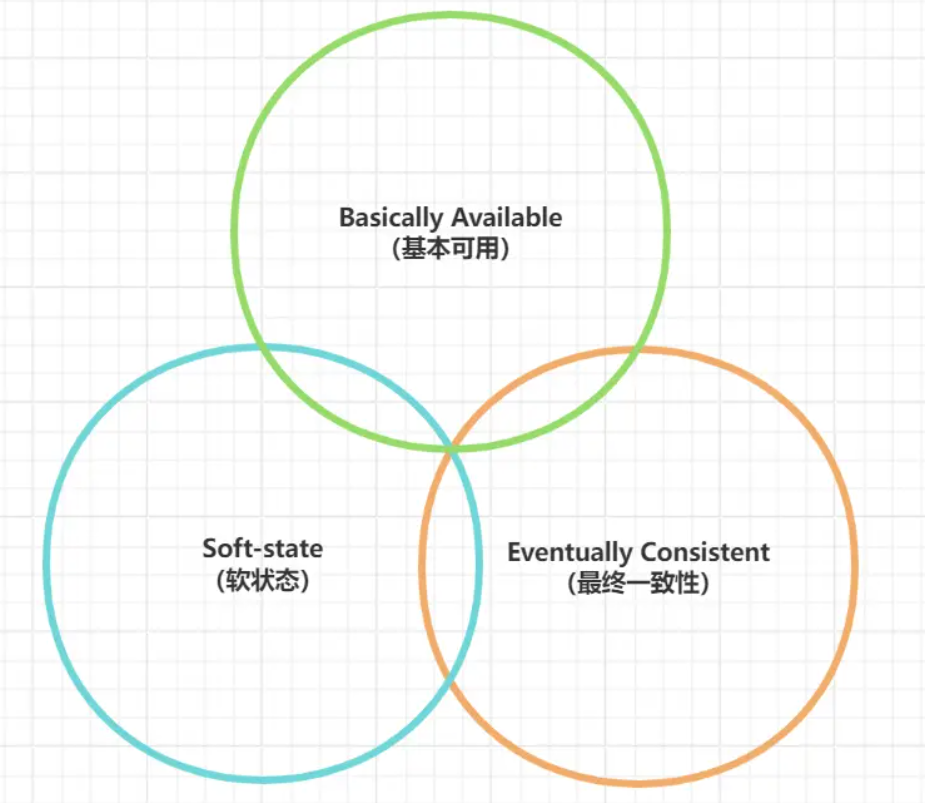
基本可用
当系统出现故障或意外情况时,允许放弃掉部分可用性,保证核心功能可用,或能响应外部请求(返回自定义的错误提示也可以)即可,如熔断限流,服务降级
软状态
是指允许系统存在中间状态,并且该中间状态不会影响系统整体的可用性。这就好比传统关系型数据库里的事务机制。
成功:数据成功保存到数据库,当出现读取请求时,能正常读到写入(或更新)后的值;
失败:数据未保存到数据库,当出现读取请求时,只能看到之前的值,或看不到值;
中间态:数据写入成功,事务暂未提交,这个中间态的存在不会影响数据库整体的可用性。
最终一致性
最终一致性和软状态绑定的,软状态允许系统内存在中间态,但这个中间态只能短暂存在,在一定时间后,肯定会变成终态
雪花算法
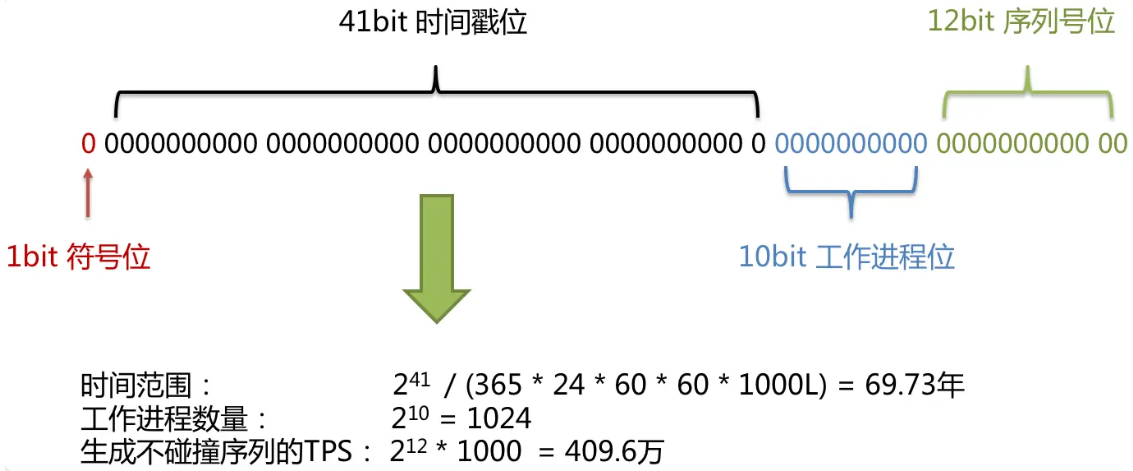
- 符号位(
1bit):永远为零,表示生成的分布式ID为正数。 - 时间戳位(
2~42bit):会将当前系统的时间戳插入到这段位置,41bit大概可以储存69.73年的时间戳,而雪花算法的时间纪元是从2016.11.01日开始的 - 工作进程位(
43~53bit):在集群环境下,每个进程唯一的工作ID。 - 序列号位(
54~64bit):该序列是用来在同一个毫秒内生成不同的序列号,可以生成4096个不同的ID值,当系统每毫秒的并发ID需求超出4096,留到下个毫秒时间戳时再生成ID。
Raft 算法
算法演示:http://thesecretlivesofdata.com/raft/
算法角色
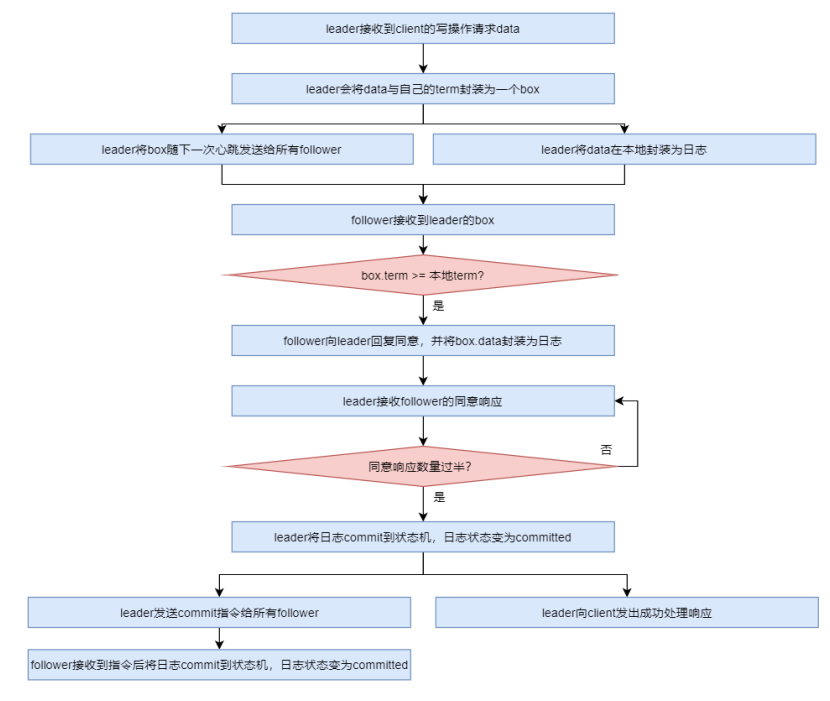
Leader:唯一负责处理客户端写请求的节点;也可以处理客户端读请求;同时负责日志复制工作
Candidate:Leader 选举的候选人,其可能会成为 Leader。是一个选举中的过程角色
Follower:可以处理客户端读请求;负责同步来自于 Leader 的日志;当接收到其它 Cadidate 的投票请求后可以进行投票;当发现 Leader 挂了,其会转变为 Candidate 发起 Leader 选举
leader 选举
- 若 follower 在心跳超时范围内没有接收到来自于 leader 的心跳,则认为 leader 挂了。此时其首先会使其本地 term 增一。由 follower 转变为 candidate ,此时若接收到了其它 candidate 的投票请求,则会将选票投给这个 candidate。若之前尚未投票,则向自己投一票,然后向其它节点发出投票请求,然后等待响应。
- follower 在接收到投票请求后,其会根据以下情况来判断是否投票:发来投票请求的 candidate 的 term 不能小于自己的 term,且其选票还没有投出去,若接收到多个 candidate 的请求,我将采取 first-come-first-served 方式投票。
- 当一个 Candidate 发出投票请求后会等待其它节点的响应结果。
- 收到过半选票,成为新的 leader。然后会将消息广播给所有其它节点,将会同步数据,以告诉大家我是新的 Leader 了。
- 接收到别的 candidate 发来的新 leader 通知,比较了新 leader 的 term 并不比自己的 term 小,则自己转变为 follower
- 经过一段时间后,没有收到过半选票,也没有收到新 leader 通知,则重新发出选举
- 在很多时候,当 Leader 真的挂了,Follower 几乎同时会感知到,所以它们几乎同时会变 为 candidate 发起新的选举。此时就可能会出现较多 candidate 票数相同的情况,即无法选举出 Leader。 为了防止这种情况的发生,Raft 算法其采用了会为这些 Follower 随机分配一个选举发起时间 election timeout。只有到达了 election timeout 时间的 Follower 才能转变为 candidate, 否则等待。那么 election timeout 较小的 Follower 则会转变为 candidate 然后先发起选举,一 般情况下其会优先获取到过半选票成为新的 leader。
脑裂现象
Raft 集群存在脑裂问题。在多机房部署中,由于网络连接问题,很容易形成多个分区,很容易产生脑裂,从而导致数据不一致。 由于三机房部署的容灾能力最强,所以生产环境下,三机房部署是最为常见的,以其为示例:
情况一
当A与B之间的网络连接断裂后,B 机房中的主机是感知不到 Leader 的存在的,所以 B 机房中的主机会发起新一轮的 Leader 选举。由于 B 机房与 C 机房是相连的,虽然 C 机房中的 Follower 能够感 知到 A 机房中的 Leader,但由于其接收到了更大 term 的投票请求,所以 C 机房的 Follower 也就放弃了 A 机房中的 Leader,参与了新 Leader 的选举。
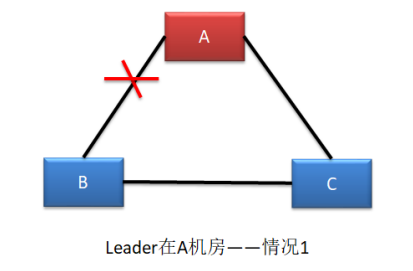
- 若新 Leader 出现在 B 机房,A 机房是感知不到新 Leader 的诞生的,其不会自动下课, 所以会形成脑裂。但由于 A 机房 Leader 处理的写操作请求无法获取到过半响应,所以无法完成写操作,此时可以读,但若BC写入了新数据,则可能出现数据不一致的现象,可以将其下课。但 B 机房 Leader 的写操作处理是可以获取到过半响应的,所以可以完成写操作。故,A 机房与 B、C 机房中出现脑裂,且形成了数据的不一致。
- 若新 Leader 出现在 C 机房,A 机房中的 Leader 则会自动下课,所以不会形成脑裂。
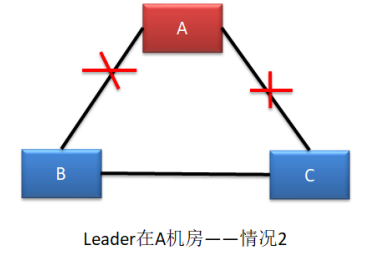
情况二
节点B和节点C中将会产生新的Lead,A中将无法写入新的数据。
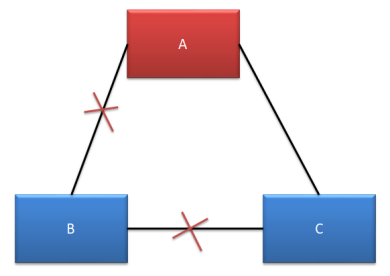
情况三
A、C 可以正常对外提供服务,但 B 无法选举出新的 Leader。由于 B 中的主机全部变为 了选举状态,所以无法提供任何服务,没有形成脑裂。
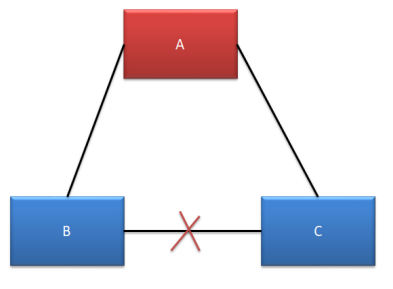
情况四
A、B、C 均可以对外提供服务,不受影响。
情况五
A 机房无法处理写操作请求,但可以对外提供读服务。 B、C 机房由于失去了 Leader,均会发起选举,但由于均无法获取过半支持,所以均无 法选举出新的 Leader。