基础知识
、java命名规范
(1)cddd类名、接口名等:每个单词的首字母都大写,形式:XxxYyyZzz, 例如:HelloWorld,String,System等
(2)变量、方法名等:从第二个单词开始首字母大写,其余字母小写,形式:xxxYyyZzz, 例如:age,name,bookName,main
(3)包名等:每一个单词都小写,单词之间使用点.分割,形式:xxx.yyy.zzz,公司域名倒置 + 具体的功能模块名 例如:java.lang
(4)常量名等:每一个单词都大写,单词之间使用下划线_分割,形式:XXX_YYY_ZZZ,
例如:MAX_VALUE,PI
(5)如果class不是public的,那么xx.java源文件名可以和类名不一样
如果class是public的,那么xx.java源文件名必须和类名一样
文档注释
java中共有三种注释,除去兼容c的两种:// 和 /**/ 。还有独特的文档注释,javadoc工具可以基于文档注释生成API文档。
文档注释
/**
注释内容
*/idea中创建Javadoc文档:工具【tools】- 生成javadoc文档,导出时编码错误,可以在
other command行【命令行实参】添加-encoding utf-8 -charset utf-8//使用utf-8编码
区域设置:zh_CN
3、常量
整数常量值,加L或l表示long类型,不加默认int(超过int范围的必须加)
小数常量值,加F或f表示float类型,不加默认double类型(超过float范围加)。
float,float a=1.5;//编译错误,因为1.5默认类型为double
float a=1.5f;//编译正确
float a=(float)1.5;//编译正确进制
//注意:进制下的数必须是存在的,如0b15是错误的,二进制不存在15。
(1)十进制:正常表示
System.out.println(10);
(2)二进制:0b或0B开头
System.out.println(0B10);//将二进制的10转化为10进制输出
(3)八进制:0开头
System.out.println(010);//将八进制的10转化为10进制输出
(4)十六进制:0x或0X开头
System.out.println(0X10);//将十六进制的10转化为10进制输出制表位


制表符\t,表示从下一个制表位开始xxx
默认情况下,一个制表符在命令行控制台占8位。一个汉字在控制台占2位,一个英文字母在控制台占1位,一个英文输入法下的标点符号在控制台占1位。
默认情况下,一个制表位在IDEA控制台占4位。一个汉字在控制台占2位,一个英文字母在控制台占1位,一个英文输入法下的标点符号在控制台占1位。
如果当前制表位已经有内容了,会跳到下一个制表位。如果内容已经占满制表位,那么\t就会跳过下一个制表位,到下下个。数据类型转换
自动(隐式)转换:
byte->char/short->int->long->float->double
1、混合运算,向大的转换
2、当byte,short,char数据类型进行算术运算时,会转换为int类型计算,所以要用int类型接受。
eg byte a=5,b=6; byte c=a+b;//报错,因为隐式转换为了int类型
int c=a+b;
或 byte b3 = (byte)(b1 + b2);强制(显示)类型转换
小类型可以赋值给大类型(会自动类型提升),但是大类型不可以赋值给小类型(但是可以强制类型转换)
eg byte a=5,b=6; byte c=(byte)(a+b);//强制转换为byte,但是可能会溢出
float精度:小数点后7-8位【十进制的科学计数法表示下,即转换为x.xxxx*10^yy】
double精度:小数点后15-16位运算符
算数运算符
/:若是整数,除数不能为0,若是小数,除数为零结果是Infinity(无穷大)
%:若是整数,模数不能为0,若是小数,模数为零结果是NaN(Not a number非数字)【java中小数可以进行模运算】
- a = q*d + r , 即-10 = (-3) * 3 + (-1) ——负余数
逻辑运算符
单逻辑运算符与双逻辑运算符的区别为:单逻辑运算符无短路操作,双逻辑有,
| - | 逻辑运算符 | 符号解释 | 符号特点 | | ---- | ------------ | ------------------------------------ | |
&| 与,且 | 有false则false| ||| 或 | 有true则true| |^| 异或 | 相同为false,不同为true| |!| 非 | 非false则true,非true则false| |&&| 双与,短路与 | 左边为false,则右边就不看 | || || 双或,短路或 | 左边为true,则右边就不看 |位移运算符
| - | << | 左移运算符(补零) | | --------------- | ----------------------------------- | |
>>| 右移运算符(补最高位) | |>>>| 无符号右移运算符(永远补零) | | & 位与 | 有0则0 | | | 位或 | 有1则1 | | ^ 位异或 | 相同则0,不同则1,所以相同数异或为0 | | ~ 位非运算符 | 0变1,1变0 |赋值运算符
- +=、-=、*=等等复合运算符进行时,会自动进行强制类型转换
byte a=5,b=6; byte c=a+b;//报错,因为隐式转换为了int类型
byte a=5,b=6; byte c+=(a+b);//通过,使用类似于+=的运算符,会进行强制类型转换,得到的结果是byte类型。条件判断
java中循环、if等条件判断处的值只能是Boolean类型,而不能是其他类型,这点和C不一样
while(1)/*错误,int类型*/
while(true)/*正确*/数组
一维数组
- 定义
- int[] arr=new int[26] 或 int arr[]=new int[15]
- 初始化
- int[] arr = {1,2,3,4,5}
- 数据类型[] 数组名 = new 数据类型[]{元素1,元素2,元素3,...};
- 状态
- 未初始化的数组默认值:int:0、double:0.0、String:null、char:编码为0的字符
- 长度
- 一维数组:arr.length
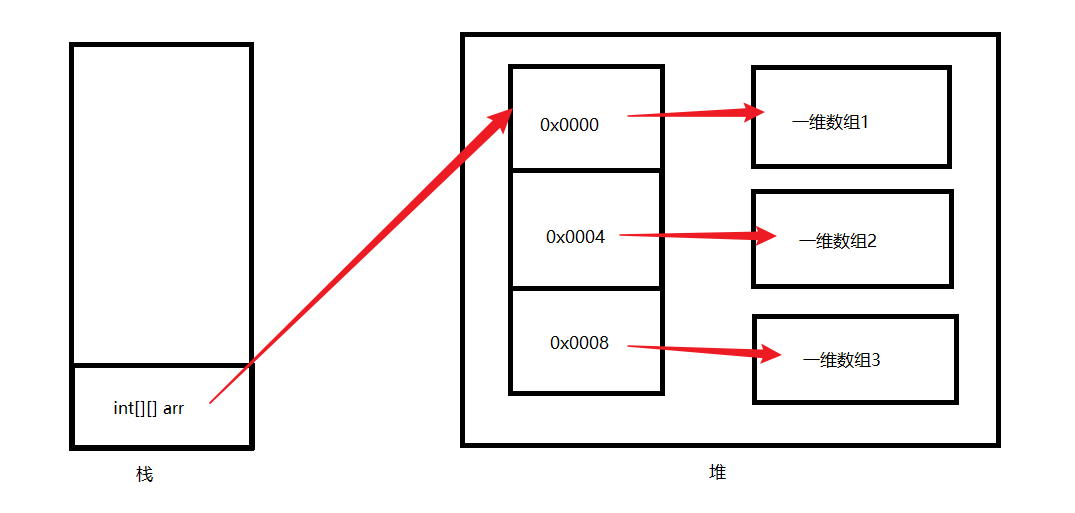
二维数组
- 定义
- int[][] arr=new int[110][110] 或 new int[110][] , arr[i]=new int[x]
- 初始化
- int[][] arr= {{1},{2,3},{4,5}}
- 长度
- 行数:arr.length
- 每行元素个数:arr[i].length
Junit
- 使用:@Test标识
- (1)所在类必须是public的类,而且只能有唯一的无参构造方法。
- (2)@Test标记的方法必须是public, void ,()的方法,非静态的
- (3)注意类名不要Test一致
单例模式
设计模式: 根据经验总结出来的代码的套路,代码的模板。
单例设计模式: 指某个类的对象在整个应用程序中只有唯一的一个。例如:手机系统中 时钟
单例模式实现步骤:
- 构造器私有化
- 类内部提前创建好该类唯一对象
具体形式:
- 饿汉式:无论你是否要用到这个类的对象,在类初始化的时候,就直接创建了它对象
//饿汉式
//静态方法直接获取
class One{
public static final One INSTANCE = new One();
private One(){
}
}
//枚举获取
enum Two{
INSTANCE
}
//方法返回获取
class Three{
private static Three instance = new Three();
private Three(){
}
public static Three getInstance(){
return instance;
}
}- 懒汉式:需要这个对象的时候,再创建这个对象
class Five{
private Five(){//构造器私有化
}
private static class Inner{//内部类,只有当调用getInstance才会初始化(Inner类的第一次使用)
static Five instance = new Five();
}
public static Five getInstance(){//在第一次出现该类的时候就会初始化
return Inner.instance;
}
}
class Four{
private static Four instance;//不着急创建的对象
private Four(){
};
public static synchronized Four getInstance(){//防止线程安全
if(instance == null) {//假设某一个线程在执行完这条判断语句的时候让出CPU(判断条件未变),另一个线程又进入,就会new两个对象
instance = new Four();
}
return instance;
}
}12、正则表达
使用字符创的matches方式进行匹配
public static void main(String[] args) {
String s1=new String();
Scanner input=new Scanner(System.in);
while(true){
s1=input.nextLine();
//必须有大写字母,小写字母,数字组成,6-12位
if(s1.matches("^(?=.*[A-Z])(?=.*[a-z])(?=.*[0-9])[A-Za-z0-9]{6,12}$")){
System.out.println("成功进入");
break;
}else{
System.out.println("密码设置不符合规定");
}
}5
input.close();
}(1)字符类
[abc]:a、b 或 c(简单类)
[^abc]:任何字符,除了 a、b 或 c(否定)
[a-zA-Z]:a 到 z 或 A 到 Z,两头的字母包括在内(范围)
(2)预定义字符类
.:任何字符(与行结束符可能匹配也可能不匹配)
\d:数字:[0-9]
\D:非数字: [^0-9]
\s:空白字符:[ \t\n\x0B\f\r]
\S:非空白字符:[^\s]
\w:单词字符:[a-zA-Z_0-9]
\W:非单词字符:[^\w]
(3)POSIX 字符类(仅 US-ASCII)
\p{Lower} 小写字母字符:[a-z]
\p{Upper} 大写字母字符:[A-Z]
\p{ASCII} 所有 ASCII:[\x00-\x7F]
\p{Alpha} 字母字符:[\p{Lower}\p{Upper}]
\p{Digit} 十进制数字:[0-9]
\p{Alnum} 字母数字字符:[\p{Alpha}\p{Digit}]
\p{Punct} 标点符号:!"#$%&'()*+,-./:;<=>?@[]^_`{|}~
\p{Blank} 空格或制表符:[ \t]
(4)边界匹配器
^:行的开头
$:行的结尾
(5)Greedy 数量词
X?:X,一次或一次也没有
X*:X,零次或多次
X+:X,一次或多次
X{n}:X,恰好 n 次
X{n,}:X,至少 n 次
X{n,m}:X,至少 n 次,但是不超过 m 次
(6)Logical 运算符
XY:X 后跟 Y
X|Y:X 或 Y
(X):X,作为捕获组
(7)特殊构造(非捕获)
(?:X) X,作为非捕获组
(?=X) X,通过零宽度的正 lookahead
(?!X) X,通过零宽度的负 lookahead
(?<=X) X,通过零宽度的正 lookbehind
(?<!X) X,通过零宽度的负 lookbehind
(?>X) X,作为独立的非捕获组
常见的正则表达式示例
验证用户名和密码,要求第一个字必须为字母,一共6~16位字母数字下划线组成:(^[a-zA-Z]\w{5,15}$)
验证电话号码:xxx/xxxx-xxxxxxx/xxxxxxxx:(^(\d{3,4}-)\d{7,8}$)
验证手机号码:( ^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$ )
验证身份证号: (^\d{15}
)|(^\d{17}(\d|X|x)$) 验证Email地址:(^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*$)
只能输入由数字和26个英文字母组成的字符串:(^[A-Za-z0-9]+$)
整数或者小数:(^[0-9]+(.[0-9]+){0,1}$)
中文字符的正则表达式:([\u4e00-\u9fa5])
金额校验(非零开头的最多带两位小数的数字):(^([1-9][0-9]*)+(.[0-9]{1,2})?$)
IPV4地址:(((\d{1,2})|(1\d{1,2})|(2[0-4]\d)|(25[0-5]))\.){3}((\d{1,2})|(1\d{1,2})|(2[0-4]\d)|(25[0-5]))
密码要求:必须有大写字母,小写字母,数字组成,6位:^(?=.[A-Z])(?=.[a-z])(?=.*[0-9])[A-Za-z0-9]{6,10}$
13、输入输出
- 输出
System.out.println(输出内容);//输出且换行
System.out.print(输出内容);//输出不换行
System.out.printf(输出内容);//和c中的一样,boolean类型的占位符:\b- 输入
Scanner input = new Scanner(System.in);
int num = input.nextInt();//接收键盘输入,不同类型使用不同方法,如input.nextDouble()
String str = input.next();//没有nextstring,使用next或者nextLine
input.close();//关闭流
next()//类似scanf,不能读取空格,遇到空格等空白符或回车,就认为输入结束
nextline()//类似gets,可以读取空格,遇到回车换行,才认为输入结束面向对象
面向对象与面向过程
- 面向过程:
- 以步骤为核心
- 代码的结构以函数为单位,程序是有一个一个的函数组成的。
- 数据是在函数内和函数外,函数内是局部数据,函数外是全局数据。
- 函数外的数据是所有函数共用的。
- 函数内的数据是这个函数独立的。
- 面向对象:
- 以类和对象为核心
- 代码的结构以类为单位。程序是由一个一个的类组成的。
- 数据是在类里面的。数据分为在类中方法(函数)外,类中方法(函数)内。
- 数据在类中方法外称为 成员变量/成员数据。 要么属于某个类共享,要么是每一个对象独立的。
- 数据在类中方法内称为 局部变量/局部数据。 局部变量无法共享,每一个方法独立。
类
类的概述
- 定义: 类是对一类事物的描述,一组相关属性和行为的集合,是抽象的。即类是对象的模板。
- 使用: 【修饰符】 class 类名{代码}
成员变量
- 定义: 类中方法外
- 分类
- 静态成员变量【static修饰】:属于类
- 实例变量【无static修饰】:属于类实例化出的对象,存在堆中,而方法的临时变量存在栈中
- 实例成员变量实例化
- 概念:对象初始化,就是给对象的“实例变量”初始化,在new对象的时候进行实例初始化。
- 步骤:我们new对象时调用构造器,本质上是执行它对应的<init>方法,每一个构造器都会有自己对应的<init>方法,由编译器编写,它由这些代码组成
- A:super()或super(实参列表) ==> 不仅仅代表父类的构造器,而且代表父类构造器对应的<init>方法
- B:当前类的实例变量声明后的显式赋值表达式语句和非静态代码块按照编写的顺序依次组装
- 显示赋值:private int a=5;
- C:构造器剩下的代码(除了super()或super(实参列表))
成员方法
定义: 类中,方法内部变量叫做局部变量或临时变量
注意:
- 方法
没有被调用的时候,都在方法区中的字节码文件(.class)中存储。 - 方法
被调用的时候,需要进入到栈内存中运行。方法每调用一次就会在栈中有一个入栈动作,即给当前方法开辟一块独立的内存区域,用于存储当前方法的局部变量的值。 - 当方法执行结束后,会释放该内存,称为
出栈,如果方法有返回值,就会把结果返回调用处,如果没有返回值,就直接结束,回到调用处继续执行下一条指令。
- 方法
分类:
- 静态成员方法【static修饰】:属于类
- 非静态成员方法【无static修饰】:属于类实例化出的对象
方法调用的入栈和出栈
可变参数列表
- 形式:数据类型... 参数名
- 注意:每一个方法,最多只有一个可变参数,且该参数必须是方法的最后一个参数。
- 使用:在声明可变参数的方法中,把它当数组中即可(0~n个元素)
- 引申:通过命令行给main方法的形参传递的实参称为命令行参数,即给public static void main(String[] args)中的args赋值,类似可变参数列表,所以也可以写作:public static void main(String... args)
//拼接传进的一个或多个str
public String Strcat (char ch,String...str) {
if(str==null||str.length==0)
return null;
String tmp="";//如果没有初始化为这样,则不可进行相加操作
for(int i=0;i<str.length;i++){
tmp+=str[i];//直接将可变参数当做数组使用
if(i< str.length-1)
tmp+=ch;
}
return tmp;
}方法重载(Overload)
概念:一个类中,方法名相同,形参列表不同的两个或多个方法【与返回值类型无关】,称为方法的重载。
调用原则:
- 先找最匹配的:实参的个数和类型与形参的个数和类型一样的。
- 再找能够兼容的:
- 形参个数相同,且形参的类型可以兼容实参的类型(自动类型提升,如int可提升为double)
- 形参类型相同,且形参的个数可以兼容实参的个数(可变参数)
注意没有最匹配方法,而兼容方法有多个时会报错。
public int Add(double... arr)
{
……
}
public int Add(double a,double...arr)
{
……
}
Add(5,6.7);//报错,因为出现多个可以兼容的方法虚方法
- 凡是可以被子类重写的方法,都叫做虚方法。
- 调用原则:
- 编译时:看父类,需要可以找到该方法
- 运行时:看子类。如果子类重写了,那么一定执行重写的方法,反之还是执行父类中找到的这个方法。
构造器
定义: new关键字后面出现的是构造器,在new对象的同时,给对象“实例变量”赋值。
方式:【修饰符】 类名() {}
特点 :
- 如果一个类没有编写构造器,那么编译器将会自动添加默认的无参构造。且权限修饰符默认和class类前面的权限修饰符一致。
- 如果手动编写了任意一种构造器,那么编译器就不会再自动添加默认的无参构造。此时需要无参构造,那么必须手动编写。
调用: 都必须在构造器的首行,且必须保证构造器之间不能出现“递归”调用。且super和this不能出现在在同一个构造器中出现
- 调用本类:
- this():调用本类的无参构造
- this(实参列表):调用本类的其他有参构造
- 调用父类:
- super():调用父类无参构造
- super(实参列表):调用父类的有参构造
- 调用的特点:
- 父类的构造器不会继承到子类中
- 子类在继承父类时,编译器默认会在子类的每一个构造器首行,加一句代码super(),若在该行中调用了this或者其他super,则不会执行该代码。
- 因为子类会继承父类所有的成员变量,那么在new子类对象时,必须为这些继承成员变量“初始化”,而为这些成员变量初始化,最合适的就是通过父类的构造器。
- 调用本类:
代码块
定义: 由大括号扩起的一段代码
分类:
静态代码块【static修饰】:属于类
非静态代码块【无static修饰】:属于类实例化出的对象
非静态代码块:{}
- 作用:给“实例变量”初始化的,把多个构造器中的代码抽取出来,减少代码冗余。
- 执行特点:
- 1、当new对象时,自动执行,不new对象不会执行。
- 2、无论它写在哪里,都是比构造器先执行。
静态代码块:static{}
- 作用:给静态变量初始化
- 注意:
- 1、类初始化的过程时在调用一个<clinit>()方法,由编译器自动生成的。即将静态类成员变量的显式赋值语句和静态代码块中的语句按顺序组装到clinit中。
- (2)在第一次使用类时对类进行初始化时执行,优于类方法调用、对象创建,且每一个类只会执行一次。如果父类没有初始化,那么会先初始化父类。
内部类
定义: 声明在另一个类里面的类叫做内部类。
形式:
- 静态内部类: 类内方法外,static修饰
【修饰符】 class 外部类{
【修饰符】 static class 静态内部类{
}
}特点:
- 它有字节码文件,命名为:外部类名$静态内部类全名称
- 和正常类一样,允许有父类,父接口,有相同的修饰符。
- 使用依赖外部类,但不依赖外部类的对象。
使用:
- 静态内部类
javapublic class SupClass implements Cloneable{ static class InnerClass{ static int a=5; int b=6; } }- 在外部类外使用
java使用的静态成员:外部类名.静态内部类名.静态成员 System.out.println(SupClass.InnerClass.a); 使用非静态成员:需要创建对象,外部类名.静态内部类名 变量 = new 外部类名.静态内部类名(【实参】)。 静态内部类对象.非静态成员 SupClass.InnerClass innerClass = new SupClass.InnerClass(); System.out.println(innerClass.b);- 在外部类内使用:
java使用静态内部类的静态成员:静态内部类名.静态成员 System.out.println(InnerClass.a); 使用静态内部类的非静态成员:需创建对象, 静态内部类名 变量 = new 静态内部类名(【实参】); 静态内部类对象.非静态成员 InnerClass innerClass=new InnerClass(); System.out.println(innerClass.b);注意:
静态内部类不可以使用外部类的非静态的成员。
- 非静态内部类,在拥有外部类对象之前是不可能创建其对象的。
- 静态内部类,创建其对象并不依赖于外部类对象的创建。
所以在创建静态内部类时,外部类对象不一定存在。而外部类的静态成员在类加载时,就于静态区域分配内存了,所以即便没有创建对象也可以访问;而非静态成员在创建对象才会开辟空间。如果静态类内部存在外部类的非静态成员,会导致没有创建的成员被调用静态内部类中定义了和外部类重名的静态属性:优先访问静态内部类中定义的,如果要访问外部类的静态变量,需要加“外部类名.
非静态内部类: 类内方法外,无static修饰
java【修饰符】 class 内部类{ 【修饰符】 class 非静态内部类{ } }特点:
它有字节码文件,命名为外部类名$非静态内部类全名称
和其他类唯一的区别是,不允许有自己的静态成员。
使用非静态内部类时,需要外部类及其对象,而静态成员在类加载时初始化,此时并不存在外部类对象,所以该静态成员是无法访问的,所以Java不允许有非静态内部类的静态成员。使用依赖外部类,也依赖其对象
使用:
在外部类的外面:
java先创建外部类对象,在通过外部类对象new内部类对象 SupClass supClass = new SupClass(); SupClass.InnerClass innerClass = supClass.new InnerClass();在外部类的里面
java直接new内部类对象 public void supTest(){ InnerClass innerClass = new InnerClass(); System.out.println(innerClass.a); }
注意: 当非静态内部类中定义了和外部类重名的非静态属性时:如果要访问外部类的非静态变量,需要加“外部类名.this."
局部内部类: 类内方法内,有名
java有名字的局部内部类 【修饰符】 class 外部类{ 【修饰符】 返回值类型 方法名(【形参列表】){ 【修饰符】 class 局部内部类{ } } }特点:
有自己的字节码文件,外部类名$编号局部内部类名,编号作用是为了避免字节码文件重名问题
修饰符只能使用:abstract和final,不能有静态成员,其余和普通类一致
只能在方法内部使用,静态成员无意义
使用:
作用域:当前方法声明之后的位置
可以使用当前方法的局部变量,但是要求这个局部变量必须是final修饰的的。JDK1.8之前,必须手动加final,JDK1.8之后会在局部内部类中使用会自动加final. <a href="#final-local-variable">为什么使用final修饰?</a>
原因:内部类对象的生命周期会超过局部变量的生命周期。 局部变量的生命周期:当该方法被调用时,该方法中的局部变量在栈中被创建,当方法调用结束时,退栈,这些局部变量全部死亡。 内部类对象生命周期与其它类一样:自创建一个匿名内部类对象,系统为该对象分配内存,直到没有引用变量指向分配给该对象的内存,它才会死亡(被JVM垃圾回收)。 所以完全可能出现的一种情况是:成员方法已调用结束,局部变量已死亡,但匿名内部类的对象仍然活着。如果匿名内部类的对象访问了同一个方法中的局部变量,就要求只要匿名内部类对象还活着,那么栈中的那些它要所访问的局部变量就不能“死亡”。
匿名内部类: 类内方法内,无名
【修饰符】 class 外部类{ 【修饰符】 返回值类型 方法名(【形参列表】){ new 父类/父接口(){ }; } }- 语法格式:
java//等价于 new class 匿名子类 extends 父类{} new 父类(形参列表){ //super()默认添加 …… } //等价于 new class 匿名子类 extends Object implements 父接口{} new 父接口(){ //super()默认添加,父类是Object类 类的成员列表 }注意:
- 匿名内部类不能有静态成员,没有类名,即使有静态成员也无法访问
- 构造器无法手动编写,只能由编译器自动产生。【构造器名字必须和类名一致,而匿名局部类无名字】
用法:
(1)匿名内部类的匿名对象.方法
new Object(){
void method(){
System.out.println("匿名内部类的自定义方法method");
}
}.method();
(2)通过父类或父接口的变量 接收 匿名子类/匿名实现类的对象,然后多态调用
Base b = new Base(){
@Override
public void method() {
System.out.println("匿名内部类重写父类的抽象方法method");
}
@Override
public void fun() {
System.out.println("匿名内部类重写父类的抽象方法fun");
}
};
b.method();
b.fun();
(3)把匿名内部类的匿名对象直接作为另一个方法调用的实参
test(new Base() {
@Override
public void method() {
System.out.println("另一个Base类的匿名子类重写method");
}
@Override
public void fun() {
System.out.println("另一个Base类的匿名子类重写method");
}
});
public static void test(Base b){
System.out.println("AnonymousInnerUse.test");
b.method();
}对象
对象是一类事物的实例,是具体的,即对象是类的实体。
注意
- 直接打印对象名和数组名都是显示“类型@对象的hashCode值",所以说类、数组都是引用数据类型,引用数据类型的变量中存储的是对象的地址,或者说指向堆中对象的首地址。
- 不定义对象的句柄(标识符),而直接调用这个对象的方法。这样的对象叫做匿名对象。
- 如:new Person().shout();
类与对象关系
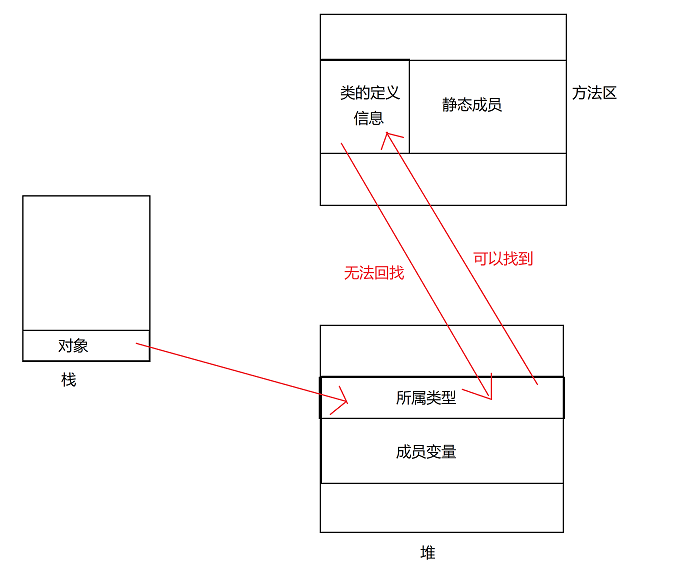
Java对象保存在内存中时,由以下三部分组成:
对象头
- Mark Word:记录了和当前对象有关的GC、锁等信息。
- 指向类的指针:每一个对象需要记录它是由哪个类创建出来的,而Java对象的类数据保存在方法区,指向类的指针就是记录创建该对象的类数据在方法区的首地址。对象类型检查和转换、反射、调用方法以及后期绑定(或运行时绑定,即在运行时根据对象的实际类型(而不是引用类型)来决定调用哪个方法的机制。)都需要对象的类信息
- 数组长度(只有数组对象才有)
实例数据
- 即实例变量的值
对齐填充
- 因为JVM要求Java对象占的内存大小应该是8bit的倍数,如果不满足该大小,则需要补齐至8bit的倍数,没有特别的功能。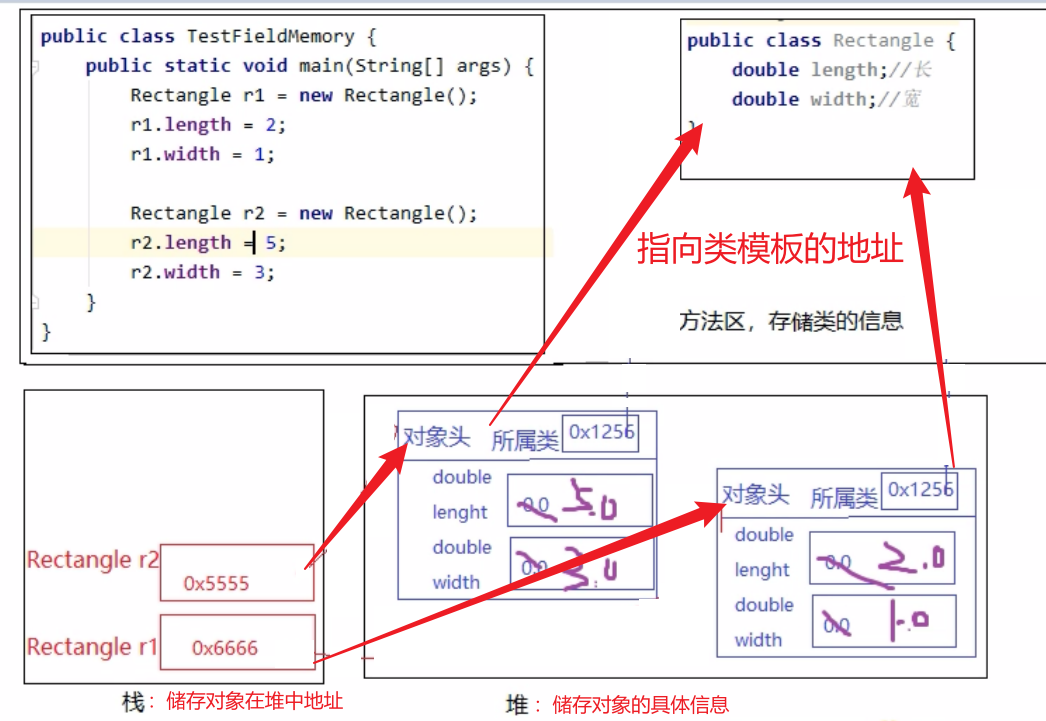
封装
权限修饰符种类:
- public、protected、缺省,private。
可见性范围
- 类:
- public修饰:同模块下,可以跨包使用。
- 缺省:仅包内使用
- 方法:
本类 本包的其他类 其他包的子类中 同模块其他包的非子类 private √ × × × 缺省 √ √ × × protected √ √ √ × public √ √ √ √- 成员变量
本类 本包的其他类 其他包的子类中 同模块其他包的非子类 private √ × × × 缺省 √ √ × × protected √ √ √ × public √ √ √ √ 实际应用中,习惯上先声明成员变量为private,防止对象数据被随意修改未非法值。而通过提供get,set方法来解决外部使用的需要。- 类:
全部修饰符
| - | | 外部类 | 成员变量 | 代码块 | 构造器 | 方法 | 局部变量 | 内部类 | | :-------: | :---: | :----: | :------: | :----: | :----: | :---: | :------: | | public | √ | √ | × | √ | √ | × | √ | | protected | × | √ | × | √ | √ | × | √ | | 缺省 | √ | √ | × | √ | √ | × | √ | | private | × | √ | × | √ | √ | × | √ | | static | × | √ | √ | × | √ | × | √ | | final | √ | √ | × | × | √ | √ | √ | | abstract | √ | × | × | × | √ | × | √ | | native | × | × | × | × | √ | × | × |
abstract和final不能一起修饰方法和类:因为abstract要求一定要类一定要被继承、方法要被重写,final要求类不能被继承、方法不能被重写。
abstract和static不能一起修饰方法:static方法不能被重写,且abstract方法只有方法体,若static修饰可以直接用类名调用。
abstract和native不能一起修饰方法:native没有方法体,去底层找c、c++的方法;abstract没有方法体,去子类找方法。
abstract和private不能一起修饰方法:private方法不能被重写
继承
概念: 重复使用已有的类的代码(复用),扩展已有类的代码(扩展)。
- 子类:SubClass,又称为派生类
- 父类:SuperClass,又称为基类、超类
语法格式: 修饰符 class 子类名 extends 父类名
特点:
1、创建子类信息时,会先创建父类的信息,然后再裹上子类的新增的内容。
2、子类的内容中包括继承自父类的非private实例变量和方法【包括静态的】,会为其开辟空间。但是不包括构造方法
3、父类中的private修饰的属性是不能被子类继承的,需要注意的是这里不能被子类继承并非指的是不能被子类使用,父类private属性是会存在于子类对象中的,即存储在该子类对象的堆内存中,注意这里并不会产生父类对象。倘若父类中提供了public或者protected修饰的方法来访问该属性,比如set,get方法,这样在子类中是可以通过方法来使用该private属性的。
- 注意:虽然子类继承了父类的所有实例变量和实例方法。但是因为权限修饰符的原因,某些成员在子类中不能直接使用

3、子类对象调用方法时,编译器会先在子类模板中看该类是否有这个方法,如果没找到,会看它的父类甚至父类的父类是否声明了这个方法,遵循从下往上找的顺序,找到了就停止,没有找到就会报编译错误。
4、Java中只支持单继承,但支持多层继承,即只有一个父类,但父类还可以有父类。
5、Object类是所有类的父类
父类方法重写
@Override:用于注释该方式是子类重写父类的方法,不是子类自己扩展的方法。可以让编译器帮你检查是否满足重写的要求。
当在子类重写方法的方法体中,想要继续执行父类被重写方法的方法体时,可以通过“super.父类被重写方法名(参数)"
重写方法名、形参列表:必须相同。返回值类型:若为基本数据类型和void,必须相同;若为引用数据类型:子类重写的方法的返回类型可以是父类方法返回类型或其的子类型
子类方法的行为必须与父类方法的行为兼容,避免多态引用时,无法使用父类方法的返回值类型接受子类的返回值类型子类重写父类的方法时,重写的方法不能有比父类被重写的方法更严格的访问级别。例如,如果父类的方法是公有的,那么子类重写的方法也必须是公有的。
方法在父类中可见,子类中不可见。避免多态引用时通过父类调用子类的方法导致权限不足。子类重写的方法不能比父类被重写的方法抛出更宽泛的异常。
一个方法声明它可能会抛出某种异常时,调用这个方法的代码就需要准备处理这种异常。这是方法的一部分契约:它告诉调用者“我可能会抛出这种异常,你需要准备处理它”。 如果子类重写的方法比父类被重写的方法抛出更宽泛的异常,那么使用父类引用调用这个方法的代码可能会遇到它没有准备处理的异常。这会破坏方法的契约,因为方法实际上抛出了它没有声明的异常。私有的方法不能被重写。构造方法无法被重写,因为构造方法无法被继承。静态的方法不存在重写
多态
概念: 父类接受子类,调用方法时会调用子类的实现,而不是父类的实现。(多态返回值写的是父类,本质类型是子类的类型)
- 编译时,这个变量是“父类”的类型。它可以,也只能调用父类中声明的方法,所以子类中扩展的方法无法调用。
- 运行时,这个变量是“子类”的类型。所以它会执行子类重写的方法体,如果没有重写这个方法,还是执行父类中实现的方法体。
- 总结: 编译看左,运行看右。编译的时候看等号左边的类型,运行的时候看等号右边的类型。
注意: 因为子类的属性是大于等于父类的,使用父类接受子类。在编译时仅能调用父类的方法,而这些方法子类均有,是安全的。反之使用子类接受父类,在编译时可以调用子类有,父类没有的方法,在运行时就会报错。
成员变量与成员方法与多态:
- 成员变量无多态,只看编译时类型
- 成员方法有多态,只看运行时类型
成员变量无多态,只看编译时类型
成员方法有多态,只看运行时类型
//注意:r1和(Son)r1本质是一个对象,(Son)r1可以调用父类的成员变量,是因为r1继承了其所有实例变量和方法。
public class Test {
public static void main(String[] args) {
Father r1=new Son();
//成员变量没有多态的概念,变量的寻找只看编译时类型,没有编译时类型和运行时类型不一致这个说法。
System.out.println(r1.a);//输出1,因为编译时r1是Father类型
System.out.println(((Son)r1).a);//输出2,向下转换为Son类型
//成员方法有多态的概念,编译时看父类,运行时看子类。如果子类重写了,一定是执行子类重写的方法体。
r1.father();//输出Son,因为运行时r1是son类型
}
}
class Father{
int a=1;
public void father(){
System.out.println("father");
}
}
class Son extends Father{
int a=2;
@Override
public void father() {
System.out.println("Son");
}
}多态类型转换:
向上转型:自动类型转换,当把子类对象赋值给父类的变量时,在“编译时”会自动类型提升为父类的类型。
向下转型:子类自动类型转换为父类,如果需要调用子类“扩展”的方法时,通过强制类型转换完成。这样才能通过编译。
Person p1 = new Man();
Man m = (Man)p1;//相等,可以转
Person p3 = new ChineseMan();
Man m2 = (Man)p3;//ChineseMan<Man- instanceof:作用是判断某个变量/对象的运行时类型是否可以转换为后面的类型。
if(变量/对象 instanceof 类型)关键字

- 50个关键字其中const和goto是保留字,java中无法直接使用,存在是为了兼容c。
- true,false,null不是关键字,它们是字面常量。
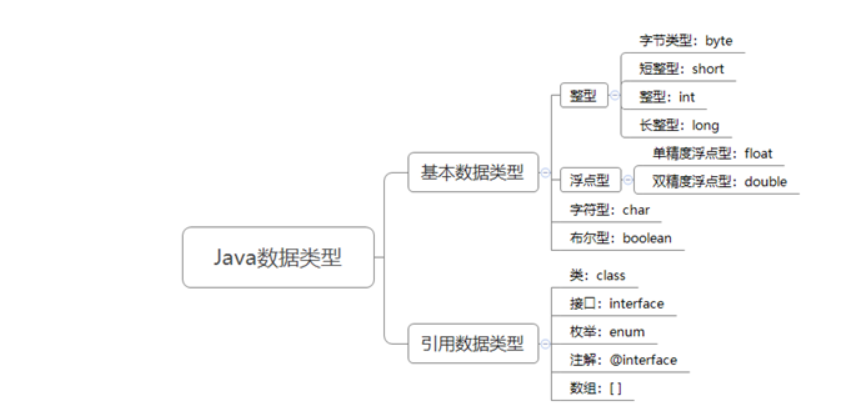
数据类型关键字
- byte: 1字节
- float:科学记数法表示数字后的小数点后6~7位 ,double:科学记数法表示数字后的小数点后15~16位。【不要使用浮点数进行
比较】 - 定义long类型的变量,赋值时需要以"
l"或"L"作为后缀。定义float类型的变量,赋值时需要以"f"或"F"作为后缀。 - char:2字节,所以char类型数据可以直接接受一个汉字
java中八种基本类型调用时传值,其余类型均为引用类型,调用时传址。
final
修饰类: 表示该类不能被继承。如:String,Math,System类都是
- 这些类要用final修饰是为了不能继承,因为子类继承就意味着,可以扩展和重写它里面的方法,而这些类太重要了,它是Java程序的基石,核心中的核心,不希望被更改。
修饰方法: 表示这个方法不能被子类重写,但是可以被继承。
修饰变量: 表示这个变量的值不能被修改。<a name="final-local-variable"> </a>
在 Java 中,
final关键字修饰的局部变量的生命周期与普通局部变量一样,都是在其所在的方法或代码块执行完毕后结束。也就是说,当方法或代码块执行完毕,final局部变量就会从栈内存中被清除。然而,如果
final局部变量被匿名内部类访问,那么这个局部变量的生命周期就会被延长。在这种情况下,匿名内部类实际上访问的是局部变量的一个副本,这个副本会被存储在匿名内部类的对象中,因此它的生命周期会与匿名内部类的对象一样长。同时final修饰的局部变量无法修改,确保其线程安全。如果某个变量是final修饰的,都必须手动初始化【显式赋值、构造器。代码块等等】,不能用默认值。
final int a;
{
a=5;
}基本类型,是值不能被改变
引用类型,是地址值不能被改变,对象中的属性可以改变
switch
switch(表达式)的结果类型只能是:byte、short、char、int、String、枚举等
double和float无法精确比较,用其作为结果类型无意义,使用Boolean只有两种结果,同样无意义case后接常量,如case 'Monday',不能是变量
如果case的后面不写break,将出现穿透现象
import java.util.Scanner;
public class test {
public static void main(String[] args) {
Scanner input=new Scanner(System.in);
String tmp=input.next();
switch(tmp){
case "Monday":
case "Sunday":
System.out.println("1");
break;
case "Saturday":
System.out.println("2");
break;
}
}
}package&import
作用:实现代码分层,降低耦合度(即关联度),限制类的使用(加public)
package 包名:声明包
一个.java文件只能有一句package语句,而且必须在代码首行
使用类的全名称:包.类名 如:com.atguigu.other(包名).Teacher(类名)可以使用包内类
使用命令行运行需要添加额外参数:
javac -d . Test01.java
import导包:
- import 包.类名;【只使用该包一个类】
- import 包.; 【使用该包多个类,这里代表的是省略的类名。】
- java.lang包下所有类不需要手动导入,系统自动导入,Object类,String类都在这个包里面,即使用这个包下的类时不用添加import。
instanceof:
作用是判断某个变量/对象的运行时类型是否可以转换为后面的类型。
if(变量/对象 instanceof 类型)this
- 概念: 表示当前对象
- 注意:
- 因为this表示的是当前对象,所以必须要有对象才可以使用。所以静态方法、静态代码块等处无法使用this。
- 调用new出来的对象调用子类构造器时,再通过super()调用父类构造器时,父类构造器中的this是子类中的this。
- 使用:
- this.成员变量、this.成员方法:先找子类,在找父类,this可以省略
- this()或this(实参列表):出现在构造器的首行,表示调用本类的其他构造器。
super
- 概念:代表的是当前子类对象中的储存的父类数据,不代表父类对象,调用时不会实例化父类对象,而是子类中本身就包含了父类
- 当父类是抽象类,子类不是抽象类时,子类调用构造函数时也会调用父类构造函数,就创建了子类和父类两个实例。但是,抽象类是不能实例化的,矛盾。
- 所以super的本质就是访问子类对象中包含的父类信息

- 使用:
- super.成员变量:表示访问父类中声明的成员变量,该变量继承在子类中,所以父类并无实例对象。
- super.成员方法:调用父类方法,若是没有重写,可以直接调用。
- super()或super(实参列表):调用父类构造器,初始化从父类中继承过来的子类成员变量。
native
- 方法的修饰符
- 权限修饰符:public ,protected, 缺省,private
- 其他修饰符:native
- 作用:表示它是本地方法,调用的是C语言编写的本地系统的方法,即它的方法体在C中。用它修饰的方法,在.java中看不到这个方法的方法体 。
- 【权限修饰符】 native 返回值类型 方法名(【形参列表】);
static
静态变量
- 静态变量的默认值和实例变量一样
- 静态变量属于类,是所有对象共享的,存储在“方法区”。其get/set方法也是静态的。
- 静态方法中不能直接访问实例方法和实例变量,后面两者是跟对象有关的。
- 静态变量可以通过“类名.静态变量”也可以通过“对象.静态变量”使用。
- 静态方法中不能使用this,this指向当前对象,static又跟对象无关,因此static和this是互斥的。
静态方法
静态方法可以通过:“对象.静态方法” 或 “类名.静态方法”
静态方法不允许被子类重写(加入@Override注解会报错),但是可以被子类继承。
javaAnimal myAnimal = new Dog(); myAnimal.speak(); // 调用的是Animal类的speak方法,而不是Dog类的speak方法 这就是为什么静态方法不能被重写的原因。如果静态方法可以被重写,那么在上面的例子中,你可能会期望调用的是 Dog 类的 speak 方法,但实际上调用的是 Animal 类的 speak 方法,这会导致混淆和错误。静态方法不是“虚”方法。没有多态现象,只看变量的编译时类型。
静态导入
- 在System类中,out是静态变量,因此我们可以将其进行静态导入,在编码的时候可以直接使用out了。
import static java.lang.System.out;//静态导入
public class StaticImport {
public static void main(String[] args) {
out.println("我想学习java");
}
}enum
定义:枚举是指一种特殊的类,即这个类的对象在声明类的时候就提前创建好了,后期就不能创建新对象了。、
实现:
- 一、构造器私有化,通过成员变量存储new好的对象,并将其声明为static,根据需求添加final、public等。
public class DayDemo {
public static final int MONDAY =1;
public static final int TUESDAY=2;
………………
}- 二、使用enum(JDK1.5之后)
【修饰符】 enum 枚举类名{
常量对象名列表1,
列表2,
……
列表n;//如果常量对象列表后面没有其他代码,那么常量对象列表后面的;可以省略。
}enum特点:
- enum的构造器都只能是private,不写也默认是。
- enum不能用extends继承别的类。因为它默认继承了java.lang.Enum类
- enum支持switch,switch条件进行结合使用时,无需使用enum对象引用。
javaenum Color {GREEN,RED,BLUE} public class Test{ public static void printName(Color color){ switch (color){ case BLUE: //无需使用Color进行引用 System.out.println("蓝色"); break; case RED: System.out.println("红色"); break; case GREEN: System.out.println("绿色"); break; } } }enum声明的枚举类型常量对象列表必须在枚举类中的首行。
enum("数值"):初始化必须有对应的构造函数和属性,无参构造器可以省略。
javaJANUARY("一月")等价于:public static final Month month=new Month("一月"); JANUARY:对应枚举名 ("一月"):构造函数需要的值 public enum Month{ JANUARY("一月"),FEBRUARY("二月"),MARCH("三月"),APRIL("四月"),MAY("五月"), JUNE("六月"),JULY("七月"), AUGUST("八月"),SEPTEMBER("九月"), OCTOBER ("十月"),NOVEMBER("十一月"),DECEMBER("十二月"); final private String description;//对应属性 private Month(String description) {//对应构造函数 this.description = description; public int length(boolean leapYear) { switch(this.ordinal()+1) {//1 3 5 7 8 10 12 4 6 9 11 case 4: case 6: case 9: case 11: return 30; case 2: return leapYear?29:28; default: return 31; } }
Enum方法
String name():返回枚举常量对象名称
- java
enum Color1 {GREEN,RED,BLUE} Color.Block.name();
int ordinal():返回常量对象的下标
String toString():Enum父类又重写了Object类的toString,返回的也是常量对象的名称,当然,子类还可以重写。
static 枚举类型[] values():返回枚举类型的所有常量对象
static 枚举类型 valueOf(String name)//返回对应枚举类型的下标
- java
Color.valueOf()
abstract
定义: 包含抽象方法的类,必须定义为抽象类。
- 抽象方法:使用abstract修饰,仅有定义而无实现。
使用:
【权限修饰符】 abstract class 类名{ 【其他修饰符】 abstract 返回值类型 方法名(【形参列表】);{ } }
特点:
- 抽象类不能创建对象,只能与子类对象构成“多态”引用。
- 子类要继承抽象类时,如果子类不是抽象类,那么子类就必须重写抽象父类的所有抽象方法。
- 有抽象方法的类必须是抽象类,但抽象类也可以没有抽象方法,可以有非抽象方法。
- 抽象类有构造器,成员变量
Implement
定义: Java中接口,是一种数据类型,和类是平级的数据类型,代表一种行为操作的标准
[修饰符] interface 接口名{ }
作用:
接口为了规范,抽象为了复用
解决类的单继承限制问题
普通类像亲爹 ,他有啥都是你的。 抽象类像叔伯,可能有一部分会给你,还能指导你做事的方法。 接口像干爹,可以给你指引方法,但是做成啥样得你自己努力实现。 如果你需要创建一个对象的模板,这个模板包含一些实现和状态,那么你应该使用抽象类。如果你需要定义一组方法,这些方法可以被多个无关的类实现,那么你应该使用接口。
接口成员:
接口中成员变量只能为公共的静态常量,即public static final【定义成员变量时,编译器会自动加上,可以省略】
接口的主要目的是定义行为,而不是状态。 在Java中,一个类可以实现多个接口。如果接口允许非常量成员变量,那么当一个类实现多个接口时,可能会出现命名冲突。公共的抽象方法(public abstract可以省略)
公共的静态方法(public static,其中public可以省略)
公共的默认方法(public default,其中public可以省略)
私有的方法(private,不能省略)
接口中是没有构造器等其他成员。
发展历程:
- JDK1.8之前,接口中只允许有公共的抽象方法。
- 因为接口的目的是规范,所以他必须可见【public】,接口内不需要具体实现【abstract】
- JDK1.8之后,接口允许声明公共的静态方法 原来很多接口,针对它的工具类性质【即具有可重用性】的静态方法,都是单独用另一个类实现的。随着类数的越来越多,导致维护的难度越来越大。JDK1.8接口允许声明公共的静态方法,减少类。
- JDK1.8之后,接口允许声明公共的默认方法 API(接口)需要升级。早期如果定义了一个接口,它包含 1个抽象方法。现在JDK版本升级了,想要给这个接口增加一个方法,若只能增加抽象方法。就会导致它的所有实现类,都需要重写这个新的抽象方法。为了避免这种情况,允许接口中出现默认方法。默认方法是有方法体,你可以写具体的实现,也可以是一个空{}。实现类如果想要实现这个新的默认方法,可以选择重写,不想支持,就不重写。
- JDK1.9之后,接口中允许出现私有方法。 因为自从JDK1.8运行在接口中出现默认方法和静态方法这种有方法体的形式之后,接口中出现了很多重复代码。很多方法实现有公共部分,所以允许通过私有方法来减少重复代码【因为方法中包含的是重复代码,不具备功能性,所以私有不让外界调用】
- JDK1.8之前,接口中只允许有公共的抽象方法。
接口特点:
接口无法创建对象,但可以与实现类多态引用。
接口的静态方法不能被实现类继承,也不能被实现类重写。(静态方法是类的)
接口支持多实现
如果一个类同时继承父类又实现接口,要把继承写在前,实现写在后。 【修饰符】 class 实现类名 extends 父类 implements 父接口们{ }接口与接口之间也可以继承,而且是多继承。
实现类实现接口时,必须实现接口的所有抽象方法。如果实现类没有实现接口的抽象方法,那么实现类就要声明为抽象类。
子接口重写默认方法时,default关键字可以保留。子类重写默认方法时,default关键字不可以保留。(接口需要default,类不需要)
接口冲突:
情况一:实现多个接口时,不同接口有相同的默认方法
前提:Girl类实现了Friend,BoyFriend两个接口,二者有相同的默认方法date
①保留其中一个接口的实现,放弃其他的:接口.super.方法();
javapublic class Girl implements Friend,BoyFriend{ @Override public void date() { //保留Friend的date默认方法 Friend.super.date(); //保留BoyFriend的date默认方法 BoyFriend.super.date(); } }②全部放弃,自己重写
javapublic class Girl implements Friend,BoyFriend{ @Override public void date() { System.out.println("学Java"); } }公共的抽象方法相同,即两个相同的标准,实现类中直接实现即可;公共的静态方法是属于接口的;私有方法实现类无法访问。所以只有默认方法会发生冲突
情况二:父类的非静态方法和接口的默认方法相同
若是静态方法重名会报错:Error:(3, 8) java: SupClass中的test()无法实现Interface中的test(),覆盖的方法为 static
①默认亲爹(父类)优先
②自己保留一个
父接口名.super.默认方法名//重写父接口 super.父类的方法//重写父类③完全重写
情况三:成员变量冲突
super.x//父类 Teacher.x//用父接口的
Volatile
- 在并发编程中,多个线程可能同时访问同一个变量。如果这个变量不是Volatile类型的,那么一个线程对它的修改可能不会立即被其他线程看到,因为其他线程可能还在使用它们自己的缓存拷贝。这就会导致线程间的数据不一致。
- Volatile关键字可以解决这个问题。当一个变量被定义为Volatile类型时,任何对它的修改都会立即刷新到主内存中,而不是等到线程结束或者锁被释放。同时,当其他线程需要访问这个变量时,它们会从主内存中读取最新的值。这样就保证了线程间数据的一致性。
strictfp
strictfp:表示要求严格遵循FP模式,可以修饰类、接口、方法。如果strictfp修饰在类上面,它作用的就是整个类,也就是说该类中所有的计算都要遵循该关键字的精度计算。如果作用在接口上,那么接口中的所有方法都遵守strictfp的精确计算,如果只是修饰在某个方法上,意思就是只有该方法做精确的计算。
transient
transient:表示瞬时的,临时的,短暂的,转瞬即逝的;
用于修饰成员变量;
transient修饰的成员变量的值,如果该类实现的是java.io.Serializable接口,那么在序列化过程中该成员变量不会参与序列化。
assert
如果它断言的表达式为false,将会抛出java.lang.AssertionError对象。
语法格式:
assert 布尔表达式;
或
assert 布尔表达式 : "错误信息";注意:要开启断言功能,在eclipse中需要加JVM参数 -ea
异常
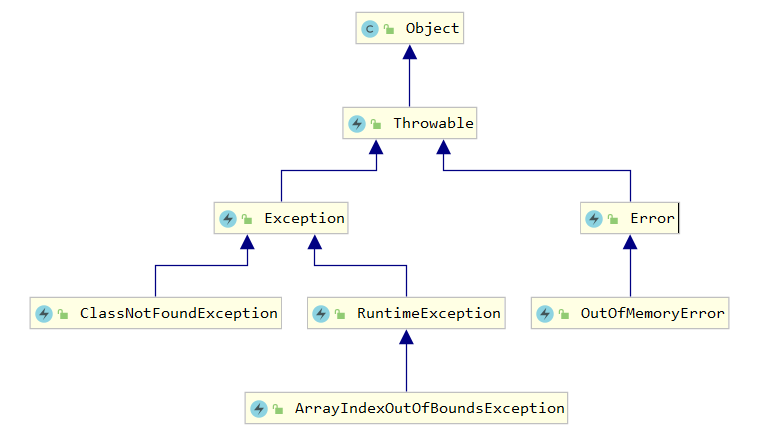
异常的构成:
- Throwable 类是 Java 语言中所有错误或异常的超类
- Exception:表示程序可以处理的异常,可以捕获且可能恢复
- 编译时异常:RuntimeException及其子类
- ArrayIndexOutOfBoundsException:数组下标越界异常
- ……
- 运行时异常:除了编译时异常
- ……
- 编译时异常:RuntimeException及其子类
- Error:一般是指与虚拟机相关的问题,仅靠程序本身无法恢复和预防,遇到这样的错误,建议让程序终止。
- VirtualMachineError (虚拟机错误)
- OutOfMemoryError(堆内存溢出)
- StackOverflowError(栈内存溢出)
- ……
- Exception:表示程序可以处理的异常,可以捕获且可能恢复
Try……Catch……finally……
语法格式:
javatry{ 可能发生异常的代码 } catch(异常的类型 异常对象名称){//异常对象名称都是用e表示 处理这个异常的代码。 处理方式:(1)输出打印异常的信息(2)进行相应的逻辑处理 } catch(异常的类型 异常对象名称){ } finally{ }注意:
多个catch,若异常为父子类,一定是子类在上,父类在下。【如果父类在上,多态可以继承的话,永远到不了子类】
catch()中的类型必须是Throwable 极其子类
多个Catch捕捉不同异常,采用相同处理,JDK1.7后允许如下写法
javacatch(ArrayIndexOutOfBoundsException | NullPointerException e){ e.printStackTrace(); }除非在try{}后catch{}中有一句System.exit(0)【退出JVM】,否则finally中的语句都一定会执行。通常都是资源释放或关闭代码写到finally中。
若finally中存在return语句,无论try……catch中是否return,返回值最终一定是finally中的值。try……catch中执行return语句,也会进到finally。
java最终返回0 public static int test(String str){ try{ Integer.parseInt(str);//假设输入会发生异常,跳到catch return 1;//不执行 }catch(NumberFormatException e){ return -1;//执行 (1)先把-1放到“操作数栈”中(2)再去执行finally }finally{ System.out.println("test结束"); //执行 (1)先把0放到“操作数栈”中(2)把“操作数栈”结果返回并结束test方法的执行【因为栈是后进先出】 return 0; } }
执行特点:
- 若try中代码不存在异常:
- 执行try中代码——>执行finally中代码
- 若try中代码存在异常
- 执行try中代码到异常发生出——>自上而下匹配catch中异常,存在则执行其中代码,不存在则将异常向上抛【抛到main方法还未解决,程序就挂了】——>执行finally中的代码
- 若try中代码不存在异常:
throws
格式:
修饰符 返回值类型 方法名(参数) throws 异常类名1,异常类名2…{ }作用:某段代码可能发生编译时异常,需要处理后才能通过编译,就可以通过throws扔出异常,在更上层进行处理。【运行时异常,编译器是检测不到的,所以不加try..catch、throws也没事】
throws重写
- 如果父类或父接口被重写方法,没有throws“编译时异常”
- 重写方法时,就不能throws编译时异常,但是可以throws运行时异常
- 如果父类或父接口被重写方法,有throws“编译时异常”
- A:重写方法时,可以不throws编译时异常 B:重写方法时,可以throws编译时异常,但是要求 <= 被重写方法的异常类型 C:对于运行时异常来说,没有限制。
- 总结:运行时异常,编译器不管,编译时异常: <=
- 如果父类或父接口被重写方法,没有throws“编译时异常”
throw
作用:用于手动抛出一个异常对象。
javapublic static int max(int... nums)throws IllegalArgumentException{ if(nums == null || nums.length<1){ throw new IllegalArgumentException("必须传入至少一个整数"); //可以代替return语句,返回一个异常对象 } int max = nums[0]; for (int i = 1; i < nums.length; i++) { if(nums[i] > max){ max = nums[i]; } } return max; }
异常信息获取
- 内容:
- (1)异常的类型 (2)异常的原因message (3)异常的堆栈跟踪信息
- 方法:配合System.err.println()方法
- (1)e.printStackTrace(); 打印异常的详细信息,包括(1)(2)(3)
- (2)e.getMessage()方法。打印(2)
- (3)e.getClass()方法。打印(1)
- (4)e.getStackTrace()方法。打印(3)
自定义异常
- 要求:
- 要继承一个异常类型:Exception或者RuntimeException
- 建议大家提供至少两个构造器,一个是无参构造,一个是(String message)构造器。【调用父类的有参构造器】
- 自定义异常对象只能throw手动抛出。抛出后由try..catch处理,也可以甩锅throws给调用者处理。
public class NotTriangleException extends Exception{
public NotTriangleException() {
}
public NotTriangleException(String message) {
super(message);
}
}
public class Triangle {
private double a;
private double b;
private double c;
public Triangle(double a, double b, double c) throws NotTriangleException {
if(a<=0 || b<=0 || c<=0){
throw new NotTriangleException("三角形的边长必须是正数");
}
if(a+b<=c || b+c<=a || a+c<=b){
throw new NotTriangleException(a+"," + b +"," + c +"不能构造三角形,三角形任意两边之后必须大于第三边");
}
this.a = a;
this.b = b;
this.c = c;
}
}File类和IO流
java.io.File类
- 作用:表示某个文件或文件夹(文件夹又称为目录)。
基本知识
路径分隔符:因为早期Windows只支持 \,现在所有平台都支持 /
要表示Windows操作系统下的D盘Download文件夹下的材料.zip。表示为:
javaFile file = new File("d:\\Download\\材料.zip"); 或者: File file = new File("d:/Download/材料.zip");
路径:
- 绝对路径:在描述文件或文件夹时,从根目录开始导航的路径。对于windows操作系统来说,盘符就是根,如d:/Download;对于linux操作系统来说,/就是根,如/Download。
- 相对路径:在描述文件或文件夹时,不是从根目录开始导航的路径。例如:download/1.txt。对于IDEA中,JUnit的test方法,相对路径是相当于当前的模块;main方法,相对路径是相当于当前的project
- 构造路径:在new File对象时,在()中填写的路径。构造路径可以是相对路径,也可以绝对路径。
- 非规范路径:如果路径名中出现了“.."等情况,会进行解析,表示回退到上一级目录。
常用方法
构造方法
public File(String pathname):通过将给定的路径名字符串创建新的File实例。
javaFile file = new File("d:/Download/材料.zip");public File(String parent, String child):根据父路径和子路径拼接后的路径创建File实例
javaFile file = new File("d:/Download","材料.zip");
常用方法1
public String getName() :返回由此File表示的文件或目录的名称
public long length() :返回由此File表示的文件的大小。如果不是文件,而是目录【文件夹】,则返回值是不确定的。
String getPath() :获取的是构造路径的值
String getAbsolutePath():获取绝对路径的值,不会对路径中的 \. 等进行处理
String getCanonicalPath():获取规范路径的值,会对路径中的 \. 等进行处理
public long lastModified():返回File对象对应的文件或目录的最后修改时间(毫秒值)
boolean renameTo(File file):将当前文件修改参数文件的名字,注意:需要传绝对路径
javaFile file3 = new File(file1+"\\"+string+".wav"); System.out.println(file3); try { boolean b = file2.renameTo(file3); System.out.println(b); } catch (Exception e) { throw new RuntimeException(e); }
常用方法2
- new file仅是在JVM堆内存中创建file对象,而未在硬盘中做对应处理,所以指定路径文件夹是否存在不影响其f创建,只有调用createNewFile或mkdir/mkdirs才会创建文件或文件夹
- public boolean createNewFile()throws IOException :创建一个新文件,路径存在才能创建,与mkdir结合使用
- public public boolean mkdir():创建文件夹,但只能创建一级,不包括任何必需但不存在的父目录
- public public boolean mkdirs():创建文件夹,可以创建多级,包括任何必需但不存在的父目录
- public boolean delete():删除文件或文件夹,如果文件夹是非空目录,那么是无法删除的。即只能删除空文件夹。注意,删除后不在回收站。
常用方法3
- public boolean exists() :此File表示的文件或目录是否实际存在。
- public boolean isDirectory() :此File表示的是否为目录。
- public boolean isFile():此File表示的是否为文件。
常用方法4
public String[] list():返回一个String数组,表示该File目录中的所有子文件或目录,不会返回子文件下的内容。
public File[] listFiles():返回一个File数组,表示该File目录中的所有的子文件或目录,不会返回子文件下的内容。
public File[] listFiles**(FileFilter filter):返回所有满足指定过滤器的文件和目录。如果给定 filter 为 null,则接受所有路径名。否则,当且仅当在路径名上调用过滤器的 FileFilter.accept(File pathname)方法返回 true 时,该路径名才满足过滤器。如果当前File对象不表示一个目录,或者发生 I/O 错误,则返回 null。**
java//过滤参数为文件 dir.listFiles(new FileFilter() { @Override public boolean accept(File file) { return file.isDirectory(); } });public String[] list(FilenameFilter filter):返回返回所有满足指定过滤器的文件和目录。如果给定 filter 为 null,则接受所有路径名。否则,当且仅当在路径名上调用过滤器的 FilenameFilter .accept(File dir, String name)方法返回 true 时,该路径名才满足过滤器。如果当前File对象不表示一个目录,或者发生 I/O 错误,则返回 null。
public File[] listFiles(FilenameFilter filter):返回返回所有满足指定过滤器的文件和目录。如果给定 filter 为 null,则接受所有路径名。否则,当且仅当在路径名上调用过滤器的 FilenameFilter .accept(File dir, String name)方法返回 true 时,该路径名才满足过滤器。如果当前File对象不表示一个目录,或者发生 I/O 错误,则返回 null。
java//过滤参数包括文件和文件名 dir.listFiles(new FilenameFilter() { @Override public boolean accept(File dir, String name) { return name.endsWith(".txt"); } });java.io.FileFilter:文件过滤接口,抽象方法:boolean accept(File pathname),pathname是某个文件夹在列出下一级时的每一个下一级,如果pathname根据某个条件返回true,就表示要留下这个文件或文件夹。
java使用递归输出一个文件夹极其所有子文件/子文件夹 @Test public void test1(){ File file=new File("D:/word"); test3(file); } public void test3(File file){ if(file.isDirectory()){//如果是文件进入循环 File[] files = file.listFiles(new FileFilter() {//传入一个FileFilter对象【文件过滤】,重写accept方法 @Override public boolean accept(File pathname) {//判断文件是否为.md结尾或者该File为文件夹而不是文件,返回真 return pathname.getName().endsWith(".md")||pathname.isDirectory(); } });//获取该文件夹的所有子文件/文件夹 for (File file1 : files) {//遍历 if(file1.isDirectory())//如果还是文件夹就递归, test3(file1); else//不是就输出 System.out.println(file1.getName()); } } } 使用递归求一个文件夹的总大小 @Test public void test4(){ File file=new File("D:/software/Genshin Impact"); System.out.println(getSize(file)); } public long getSize(File file){ long sum=0; if(file.isFile()) return file.length();//如果是文件,即递归到最后一层,直接返回 else{ File[] files = file.listFiles();//file的所有下一级 for (File sub : files) { sum+=getSize(sub);//当前文件夹的大小等于所有子文件/子文件夹相加之和 } } return sum; } 使用递归删除一个文件夹 @Test public void test5(){ File file=new File("D:\\test"); deleteFile(file); } public void deleteFile(File file){ if(file.isDirectory()){//如果是文件夹就继续 File[] files = file.listFiles(); for (File sub : files) {//如果文件夹不为空才会进入该循环 deleteFile(sub); } } file.delete();//只有当为文件或者空文件夹时,才会执行该语句。直接删除 }
IO流
概念:流向内存是输入流,流出内存的输出流。输入也叫做读取数据,输出也叫做作写出数据。
基础IO划分:
按照方向分:
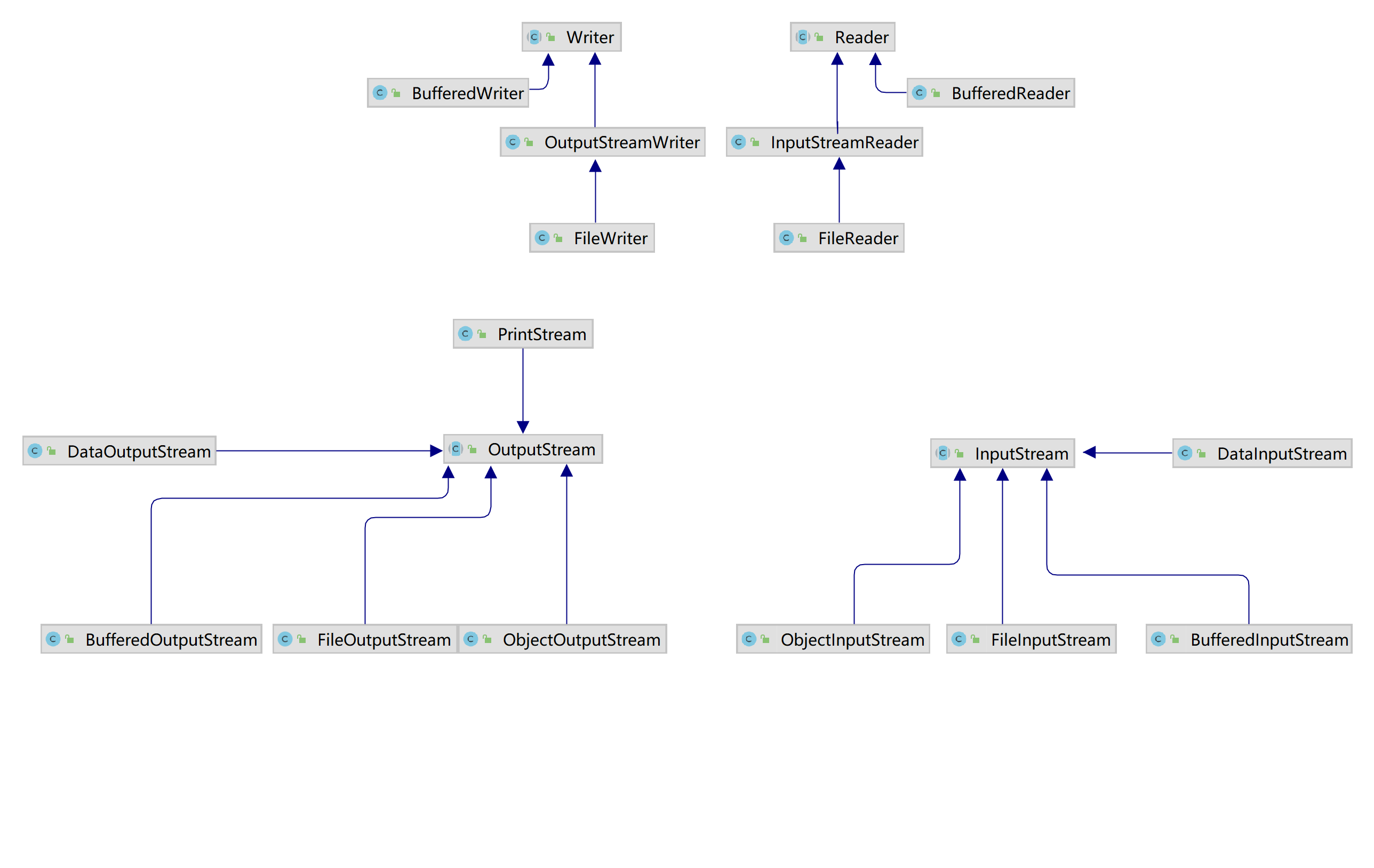
- 输入流类:InputStream、Reader系列
- 输出流类:OutputStream、Writer系列
按照操作数据的方式:
- 字节流:InputStream、OutputStream系列
- 字符流:Reader、Writer
按照角色不同:
节点流:和数据的源头/目的地连接的IO流,构造时不需要另一个流作为参数。
javaFileInputStream、FileOutputStream、FileReader、FileWriter:读写文件(以它为例讲解) ByteArrayInputStream、ByteArrayOutputStream、CharArrayReader、CharArrayWriter:读写数组处理流/包装流/装饰流:它是在其他IO流基础上,增加功能用的。构造时必须以另一个流作为参数。
javaBufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter,给其他IO流增加缓冲功能 InputStreamReader、OutputStreamWriter,给其他IO流转换类型用的,或者给其他IO编码、解码用的
IO流的四个基类:以字节方式写入的数据,查看文件时可能会出现乱码
- 字节输入流:InputStream,可以读 图片、视频、文本等。
- 字节输出流:OutputStream,可以写 图片、视频、文本等。
- 字符输入流:Reader,只能读 文本(字符串,char)。
- 字符输出流:Writer,只能写 文本(字符串,char)。
IO流操作流程:
- A:先选择合适的IO流类,创建它的对象
- B:读或写操作
- C:关闭IO流,如果写入为空,那么是没关闭IO流,且未刷新,数据留在了缓冲区
- IO流类的对象会在JVM内存中开辟空间,这些由JVM的GC自动回收。close方法主要是通知操作系统释放IO操作调用操作系统的一些函数所创建对应的内存。
流的关闭顺序:
- 先关闭外层的包装流,再关闭内层的被包装流。
文件IO流
FileInputStream类
- 如果文件不存在,会报错java.io.FileNotFoundException: (系统找不到指定的文件。)
- 父类:InputStream类
- public int read(): 从输入流读取一个字节,返回时自动提升为int类型。如果已经到达流末尾,没有数据可读,则返回-1。
- public int read(byte[] b): 从输入流中读取字节,并储存到byte数组中,并返回实际读取字节个数。每次最多读取b.length个字节。如果已经到达流末尾,没有数据可读,则返回-1。
- public int read(byte[] b,int off,int len):从输入流中读取字节,并从off下标开始储存到byte数组中,每次最多读取len个字节 。返回实际读取的字节个数。如果已经到达流末尾,没有数据可读,则返回-1。
- public void close():关闭此输入流并释放与此流相关联的任何系统资源。
FileOutputStream类【父类:OutputStream类】
文件不存在,自动创建;文件已存在,覆盖原内容;如果要追加,在创建FileOutputStream类对象时,加一个参数true
父类OutPutStream类
- public void write(int b) :将指定的字节输出。自动截断参数为int类型四个字节,保留一个字节的信息写出。
- public void write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。
- public void write(byte[] b, int off, int len):从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。
- public void close():关闭此输出流并释放与此流相关联的任何系统资源。
代码:
java下方代码写入后文件会报错,因为当这个字节数组写入的是这些数字,而不是对应的编码。编辑器将这些数字当做编码解读就会报错。所以需要使用DataOutputStream来写入 FileOutputStream fileOutputStream=new FileOutputStream("D://Test.txt"); byte[] bytes=new byte[1024]; for(int i=0;i<1024;i++){ bytes[i]=(byte) i; } fileOutputStream.close();
使用字节流复制文件:
java@Test public void test1() throws IOException{ FileInputStream fis=new FileInputStream("D:\\视频\\01、JavaSE【完结】\\day0107_JavaSE_第1天资料\\day0107_01video\\day1.avi");//打开要复制的文件 FileOutputStream fos=new FileOutputStream("D:\\test.avi");//找到哦啊要复制的地址 int len; byte[] arr=new byte[1024];//一次复制一个byte的大小 while((len=fis.read(arr))!=-1){//读取到内存。如果返回值不等于-1,标明没有到结尾 fos.write(arr,0,len);//从内存写入。每次写入要和读取的相同,所以使用len限制 } fis.close(); fos.close(); }FileReader类
- 父类Reader类
- public int read(): 从输入流读取一个字符。返回时自动提升为int类型。如果已经到达流末尾,没有数据可读,则返回-1。
- public int read(char[] cbuf):从输入流中读取字符,并储存到char数组中,并返回实际读取字节个数。每次最多读取cbuf.length个字节。如果已经到达流末尾,没有数据可读,则返回-1。
- public int read(char[] cbuf,int off,int len):从输入流中读取字符,并从off下标开始储存到char数组中,每次最多读取len个字节 。返回实际读取的字符个数。如果已经到达流末尾,没有数据可读,则返回-1。
- public void close() :关闭此流并释放与此流相关联的任何系统资源。
- 父类Reader类
FileWriter类
- 父类Writer类
- public void write(int c):写入单个字符。
- public void write(char[] cbuf):写入字符数组。
- public void write(char[] cbuf, int off, int len):写入字符数组的某一部分,off数组的开始索引,len写的字符个数。
- public void write(String str):写入字符串。
- public void write(String str, int off, int len):写入字符串的某一部分,off字符串的开始索引,len写的字符个数。
- public void flush():刷新该流的缓冲
- public void close():关闭此流,但要先刷新它。
- 父类Writer类
注意:
直接基于“文件夹/目录”创建IO流对象是错误,应该是基于文件
会报java.io.FileNotFoundException: d:\download (拒绝访问。)像FileWriter等很多的输出流的内部有自己的一个小小缓冲区,它在调用write方法时,会先将数据写到缓冲区。当缓冲区满的时候,会自动“溢出”到文件。当缓冲区没满的时候,会close方法执行时,把缓冲区的数据“清空”输出,回收内存。如果希望数据及时写出,可以使用flush刷新.
文件缓冲流
- 作用:给IO流增加缓冲区,提高效率。即缓冲流它只能是装饰(包装)别的流。
- 原理:所有的缓冲流在内部会开辟一块更大的缓冲区,默认大小是8192字节/字符(本质就是一个8192长度的byte/char数组),先将数据读取到缓冲区中,在从缓冲区读取到目标位置。因为内存之间的访问速度远远大于内存和硬盘之间的访问速度,所以可以增加速度。也可以直接开辟一个大的数组,从硬盘中直接读到该数组。
- 类:
- BufferedInputStream:只能包装InputStream系列的IO流
- BufferedOutputStream:只能包装OutputStream系列的IO流
- BufferedReader:只能包装Reader系列的IO流
- String readLine()//一次读取一行的数据
- BufferedWriter :只能包装Writer系列的IO流
- void newLine()//换行
- Windows系统里,每行结尾是
回车+换行,即\r\n; - Unix系统里,每行结尾只有
换行,即\n; - Mac系统里,每行结尾是
回车,即\r。从 Mac OS X开始与Linux统一。
转换IO流
作用:读取字节,并使用指定的字符集将其解码为字符。
InputStreamReader:输入流,从字节流到字符流的桥梁。Reader子类
- InputStreamReader(InputStream in):创建一个使用默认字符集的 InputStreamReader
- InputStreamReader(InputStream in, Charset cs):创建使用给定字符集的 InputStreamReader
- InputStreamReader(InputStream in, CharsetDecoder dec):创建使用给定字符集解码器的 InputStreamReader
- InputStreamReader(InputStream in, String charsetName):创建使用指定字符集的 InputStreamReader。
OutputStreamWriter:输出流,从字节流到字符流的桥梁。Writer子类
- 方法同InputStreamRead
代码:
java@Test public void test04()throws IOException{ FileOutputStream fos = new FileOutputStream("1.txt"); //(1)可以加这BufferedOutputStream BufferedOutputStream bos = new BufferedOutputStream(fos);//因为被包装的fos是字节流 OutputStreamWriter osw = new OutputStreamWriter(bos,"GBK");//把字符数据用GBK编码转为字节数据输出 //(2)也可以BufferedWriter加入这儿 BufferedWriter bw = new BufferedWriter(osw);//因为osw是字符流 bw.write("Hello World"); bw.close(); osw.close(); bos.close(); fos.close(); }
序列化IO流
作用:处理Java程序中的各种数据类型的数据
序列化:把Java对象直接转为字节序列过程,要求这个对象的类型必须实现java.io.Serializable接口
- 不参与序列化的字段:
- transient修饰的属性字段
- static修饰的属性字段
- 不参与序列化的字段:
反序列化:把字节序列转为Java对象的过程
当对象已经序列化好之后,对对象的类做了修改,导致反序列化的代码运行失败
javajava.io.InvalidClassException(无效的类异常): com.atguigu.object.Student; local(本地) class incompatible(不相容的;矛盾的;): stream(流) classdesc(类描述) serialVersionUID(序列化版本ID) = -3979294235569238736, local(本地) class serialVersionUID(序列化版本ID) = 5212389082514962991在类声明并实现java.io.Serializable接口时,固定 serialVersionUID(序列化版本ID)值【任意值】。可以避免上述问题。
eg:private static final long serialVersionUID = -3979294235569238736L;
类:
DataInputStream:读Java各种基本数据类型的数据+String。
DataOutputStream:写Java各种基本数据类型的数据+String。
ObjectInputStream:读Java任意类型,包括对象
ObjectOutputStream:写Java任意类型,包括对象。
javaFileInputStream fis = new FileInputStream("game.dat"); ObjectInputStream ois = new ObjectInputStream(fis); //支持写入基本数据类型,但是读的时候要对应顺序读 String name = ois.readUTF(); int age = ois.readInt(); char gender = ois.readChar(); int energy = ois.readInt(); double price = ois.readDouble(); boolean relive = ois.readBoolean(); Object object = ois.readObject(); //支持写入对象,读的时候同样要对应读 ObjectOutputStream流中支持序列化的方法是: public final void writeObject (Object obj)` : 将指定的对象写出。 ObjectInputStream流中支持反序列化的方法是: public final Object readObject ()` : 读取一个对象。
System类与IO流
System类中有三个常量对象:
- public final static InputStream in = null;//标准输入流,Scannner中的参数就是这个
- public final static PrintStream out = null;//标准输出流
- public final static PrintStream err = null;//标准错误流【标红输出】
对应修改方法:
- public static void setIn(InputStream in)//可以修改指向的流,默认是键盘输入,可以通过setIn改为文件输入
- public static void setOut(PrintStream out)
- public static void setErr(PrintStream err)
final修饰还可以发生改变:因为你这些方法是本地方法,final仅仅限制Java的修改
- private static native void setIn0(InputStream in);
- private static native void setOut0(PrintStream out);
- private static native void setErr0(PrintStream err);
Scanner类
如果没有修改过System.in,那么Scanner input = new Scanner(System.in);,默认是从键盘输入 在创建Scanner对象时,指定了其他的IO流,会从其他IO流中读取文本数据。
javaeg:Scanner input = new Scanner(new FileInputStream("2.txt"));//从文件输入 while(input.hasNextLine()){//判断有无下一行 String line = input.nextLine();//一次输入一行 System.out.println(line); } input.close();
PrintStream
作用:
可以支持各种数据类型的打印
其方法支持输出换行【print】,输出不换行【println】,还支持格式化输出【printf】
输出可以输出到各种其他IO流中,也可以直接输出到文件,也可以输出到控制台。
javaeg: PrintStream ps = new PrintStream("3.txt","UTF-8"); ps.print("hello");
方法:
- PrintStream(File file) :创建具有指定文件且不带自动行刷新的新打印流。
- PrintStream(File file, String csn):创建具有指定文件名称和字符集且不带自动行刷新的新打印流。
- PrintStream(OutputStream out) :创建新的打印流。
- PrintStream(OutputStream out, boolean autoFlush):创建新的打印流。 autoFlush如果为 true,则每当写入 byte 数组、调用其中一个 println 方法或写入换行符或字节 ('\n') 时都会刷新输出缓冲区。
- PrintStream(OutputStream out, boolean autoFlush, String encoding) :创建新的打印流。
- PrintStream(String fileName):创建具有指定文件名称且不带自动行刷新的新打印流。
- PrintStream(String fileName, String csn) :创建具有指定文件名称和字符集且不带自动行刷新的新打印流。
try..catch自动关闭流
语法:JDK1.7版本引入了新的的语法
try()中不是所有类型的对象声明和创建都可以放进去的,只能放实现了AutoClose接口的类型 只有在try()中声明的才会自动关闭。不在这里声明的不会自动关闭。 try( 需要自动关闭的资源对象的声明和创建){ 需要异常检查的业务逻辑代码 }catch(异常类型 e){ 异常处理代码 }finally{ 这里写的时其他的必须执行的代码,但是不是资源关闭的代码。 }代码:
javatry( FileInputStream fis = new FileInputStream("1.txt"); InputStreamReader isr = new InputStreamReader(fis,"GBK"); BufferedReader br = new BufferedReader(isr); FileOutputStream fos = new FileOutputStream("2.txt"); OutputStreamWriter osw = new OutputStreamWriter(fos, "UTF-8"); BufferedWriter bw = new BufferedWriter(osw); ) { String line; while ((line = br.readLine()) != null) { bw.write(line); bw.newLine(); } }catch(IOException e){ e.printStackTrace(); }
多线程
相关概念
程序:一组指令的集合,占用硬盘/存储卡的空间,运行时读取进入内存。
进程:【看做火车】 当一个程序启动后,操作系统都会给这个程序分配一个进程的ID,并且会给他分配一块独立的内存空间。一个程序可以有多个进程。
线程:【看做火车车厢】进程中的其中一条执行路径。多个线程会同属于一个进程。
- 一个程序至少有一个进程,一个进程至少有一个线程。
- 操作系统分配的资源的最小单位是进程,CPU调度的最小单位是线程。
- 因为CPU运行速度很快,所以可以交替执行线程,而线程分属不同进程,即后台可以有很多进程,但他们并不是同时执行的。几核的CPU就能同时执行几个线程。
线程多了好还是少好? 合理最好: 一般和CPU核心数差不错最好 1、如果程序执行的是耗时操作,即IO操作,线程多一些好 2、如果程序执行的是cpu计算型操作,线程越少越好,因为cpu调度线程时 切换上下文也需要时间并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。
并发(concurrency):指在同一个时刻只能有一条指令执行,但多个进程的指令被快速轮换执行,使得在宏观上具有多个进程同时执行的效果。
- 多核CPU:并行+并发
- 单核CPU:只能并发
分时调度: 所有线程轮流使用 CPU 的使用权,平均分配每个线程占用 CPU 的时间。
抢占式调度:优先让优先级高的线程使用 CPU,如果线程的优先级相同,那么会随机选择一个(线程随机性),Java使用的为抢占式调度。
守护线程:线程分为被守护线程和守护线程。当系统中所有的被守护线程都结束之后,守护线程就算自己的事情没有做完,也会自动结束。即系统中不会只有守护线程在单独运行。后台运行的GC线程等就是守护线程,当main线程结束了,GC线程就没必要存在的。
- 设置守护线程:my.setDaemon(true);//把my线程变为守护线程,这里main线程就是非守护线程【必须是继承Thread类的类对象】
- 在JUnit的测试方法中,启动的其他线程【除了test】,都默认是守护线程,有可能其任务还未完成,但是Junit的test方法运行结束了,也会自动结束。
开启线程
一个进程至少要有一个线程,Java程序至少有一个main线程,是主线程。共有四种开启线程的方式。
- 继承Thread类
- 实现Runnable接口
- 实现Callable接口
- 线程池
继承Thread类
创建Thread的子类
重写父类的public void run(){}方法。线程调度时,自动调用。写在线程体【run()方法的方法体】中的代码将会加载进入新的线程执行。
创建对应的对象
对象.start启动线程
java//现象:将run方法加载进入线程之后,main方法继续执行,输出结果交替出现 //new Thread()为匿名对象,等同于新创建了一个类,并继承了Thread类,并new出了该类的对象 public class ThreadCreate1 { public static void main(String[] args) { new Thread(){ @Override public void run() { for(int i=1;i<=5;i++) System.out.println("新开线程中:"+i); } }.start(); for(int i=1;i<=5;i++) System.out.println("main方法中:"+i); } }
实现Runnable接口
创建Runnable的实现类,重写接口抽象方法:public void run(),并创建其对象
创建Thread对象【没有方法体,不是子类】,将接口实现类对象作为参数传入。创建它的目的是为了调用start方法【start方法属于Thread】
启动线程
java线程调度器会调用t对象的run方法,因为这里启动的是t线程。(t.start()) Thread类的run() @Override public void run() { if (target != null) {//target就是传进来的Runnable接口实现类 target.run(); } } 输出结果交替出现 public class TestCreate2 { public static void main(String[] args) { new Thread( new Runnable(){//实现Runnable接口,并重写接口抽象方法的对象,将其作为参数传入Thread的有参构造器 @Override public void run() { for(int i=1;i<=5;i++) System.out.println("新开线程中:"+i); } } ).start(); for(int i=1;i<=5;i++) System.out.println("main中:"+i); } }
继承Thread和实现Runable接口区别
Java不支持多重继承:如果一个类已经继承了另一个类,那么它不能再继承 Thread 类,但它可以实现 Runnable 接口。 资源共享:如果多个线程执行同一个 Runnable 对象,那么它们可以共享同一个对象的资源。但是,如果多个线程执行同一个 Thread 子类的实例,那么每个线程都需要在内存中创建一个新的对象,这可能会导致资源的浪费。 灵活性:实现 Runnable 接口比继承 Thread 类更灵活。你可以将 Runnable 对象传递给 Thread 类的构造函数,也可以传递给 Executor 服务,或者用于网络请求等。 总的来说,虽然这两种方式都可以用于创建线程,但实现 Runnable 接口通常被认为是更好的做法
Thread类的方法
构造方法
- public Thread() :分配一个新的线程对象。
- public Thread(String name) :分配一个指定名字的新的线程对象。
- public Thread(Runnable target) :分配一个带有指定目标新的线程对象【runnable接口的实现类】。
- public Thread(Runnable target,String name) :分配一个带有指定目标新的线程对象并指定名字。
- String getName():获取线程的名称
- 如果没有手动指定线程名称,默认是Thread-编号,从0开始。
- 如果需要手动指定线程名称,可以通过构造器,或者setName(String name)方法设置线程名称。
- static Thread currentThread():获取执行当前语句的线程对象.
- 因为返回的是Thread对象,所以可以调用对象的方法,如:Thread.currentThread().getName()。
优先级相关
- 线程优先级高的,更多的机会/概率被优先调用,但并不是绝对。
- 优先级有范围:[MIN_PRIORITY, MAX_PRIORITY],即[1,10],当设置优先级不属于该范围,就会排除异常:IllegalArgumentException 非法参数异常
- MIN_PRIORITY:1 MAX_PRIORITY:10 NORM_PRIORITY:5
- public final int getPriority() :返回线程优先级
- public final void setPriority(int newPriority) :改变线程的优先级
- 线程优先级高的,更多的机会/概率被优先调用,但并不是绝对。
线程状态相关
public static void sleep(long millis) throws InterruptedException:线程休眠,单位毫秒
wait:Object的方法,会释放锁,线程唤醒后从等待时所在的行继续向后执行 sleep:thread的方法,不会释放锁public static void yield():让当前线程暂停下,让出CPU,但是下一次CPU有可能还是调用它。
void join() throws InterruptedException
在调用join的线程执行完之前,让这句代码所在线程停止。其内部调用了wait方法,其会让当前线程陷入等待。
javathreadB.start(); // 开始执行线程 B threadB.join(); // 等待线程 B 执行完毕 // 这里的代码将在线程 B 执行完毕后执行
void join(long millis) throws InterruptedException
- 等待该线程终止的时间最长为 millis 毫秒。如果millis时间到,将不再等待。
void join(long millis, int nanos) throws InterruptedException
- 等待该线程终止的时间最长为 millis 毫秒 + nanos 纳秒。
线程停止
- public final void stop()
- 强迫线程停止执行。 该方法具有固有的不安全性,已经标记为@Deprecated。所以使用其他方法,如标记法
- public final void stop()
线程安全
概述
线程数据共享【多个线程执行一段代码】
成员变量的共享:完成Runnable的实现类,在创建Thread对象时传入同一个实现类对象。
- 成员变量是属于对象的,不同线程需要共享,就要使用同一个对象。
静态变量的共享:同一个类的静态变量是共享的
- 因为静态变量是属于类的,即使是不同线程,共用的也是一个类。
局部变量无法共享。
javaclass TicketSaleThread extends Thread{ private static int total = 100;//静态变量,可以共享 int b=10;//成员变量,需要使用Thread代理同一个Runnable对象。 public void run(){ int a=5;//局部变量,无法在线程中共享 while(total>0) { System.out.println(getName() + "卖出一张票,剩余:" + --total); } } } //对同一个 Thread 子类的实例调用两次 start() 方法会抛出 IllegalThreadStateException。Thread 类的 start() 方法会启动一个新的线程并调用 run() 方法。当 start() 方法被调用后,线程的状态将变为 Runnable。如果你再次调用 start() 方法,Java 虚拟机会认为你试图重新启动一个已经运行的线程,这是不允许的。
线程数据共享问题,
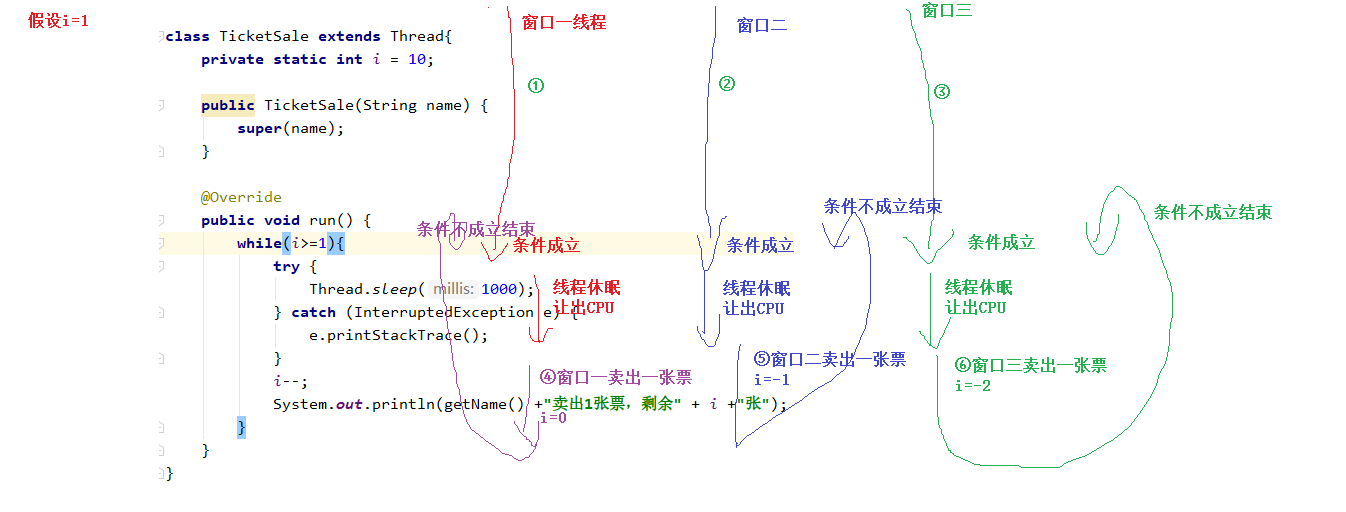
- 假设有多个窗口卖票(即多线程),sleep(1000)时会导致当前线程休眠【sleep(1000)的目的让问题更加显著,不加的话,也有小概率两个线程同时进入了判断】,让出CPU。而其他线程会继续运行,在i符合条件的情况下,进入了run多次,会导致负数票、卖出同一张票的出现。
各种锁
synchronized:排他的悲观的独占的非公平的可重入锁
偏向锁(偏向第一个线程,效率最高) ---> 如果有线程竞争升级为轻量级锁(自旋锁) ---> 自旋10次升级为重量级锁(悲观锁)
ReentrantLock:排他的悲观的独占的可公平可不公平的可中断的可重入锁
ReentrantReadWriteLock:可重入的读写锁
读锁:共享锁
写锁:独占锁
synchronized锁
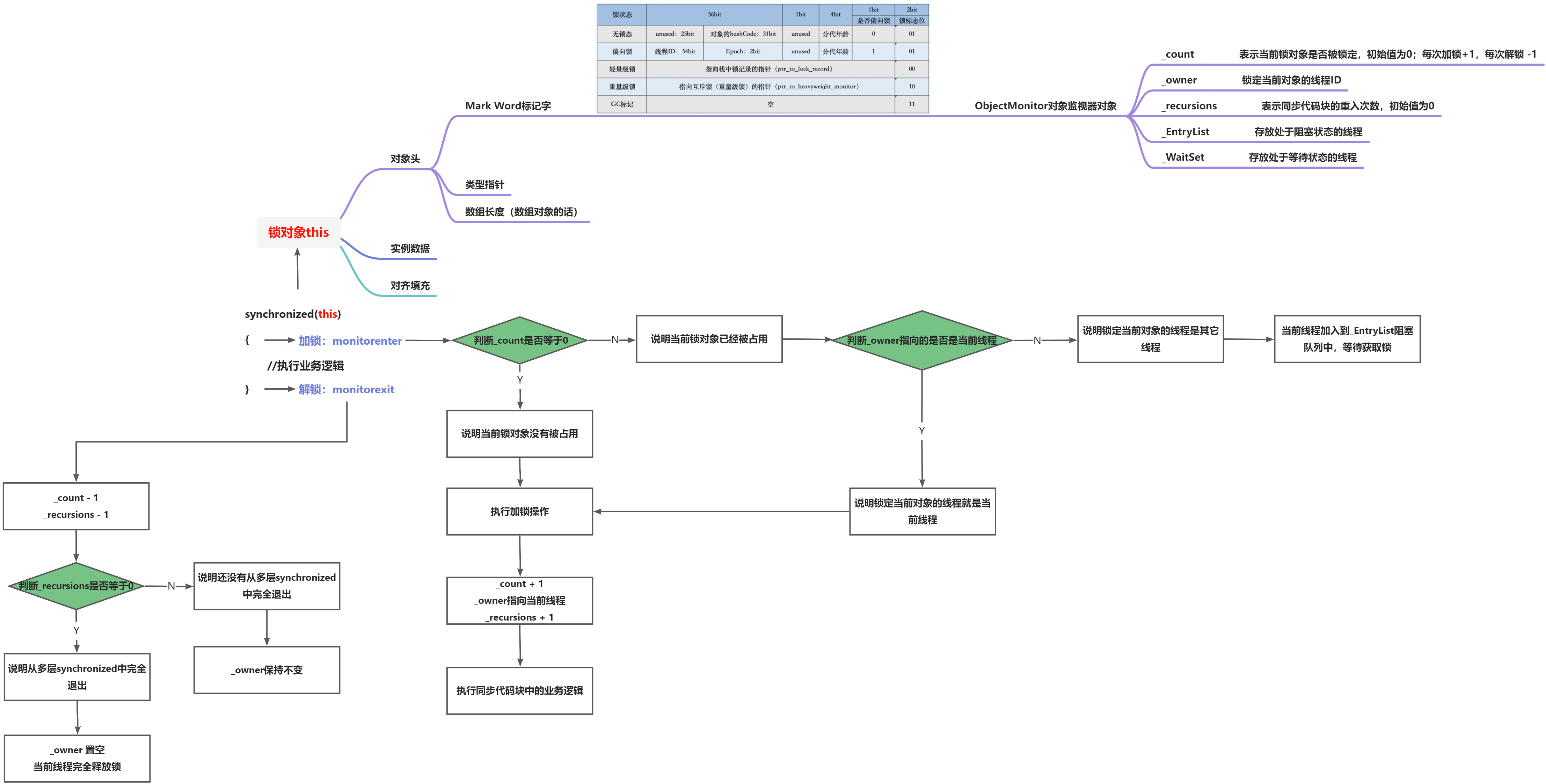
概念:给某段代码加“锁”。java对象的对象头存储了锁标记信息,这个标记记录当前线程的ID【即占有监视器对象或说占有锁】,被synchronized标识的方法,只有占有监视器(锁)对象才能执行,这些代码称为同步代码。当锁对象被线程占有时,其他线程就只能等待了,除非这个线程”释放“了锁对象
获取锁:当一个线程尝试进入一个 synchronized方法或代码块时,它需要获取一个锁。如果锁已经被其他线程持有,那么这个线程将会被阻塞,直到锁被释放。 锁的释放:当一个线程退出 synchronized 方法或代码块,或者调用了 wait() 方法,它会释放持有的锁。 锁的争用:如果多个线程同时尝试获取同一个锁,那么 JVM 会选择其中一个线程(选择规则可能依赖于 JVM 的实现),并让它获取锁。其他的线程将会被阻塞,直到锁被释放。 锁的重入:如果一个线程已经持有一个锁,那么它可以再次获取这个锁(即进入另一个 synchronized 方法或代码块)而不会被阻塞。这被称为锁的重入。监视器对象:每一个java对象均对应一个监视器对象,该对象储存在堆中,java对象头储存着一个指向其的指针。
监视器对象的信息
javaObjectMonitor() { _header = NULL; //锁对象的原始对象头 _count = 0; //抢占当前锁的线程数量 _waiters = 0, //调用wait方法后等待的线程数量 _recursions = 0; //记录锁重入次数 _object = NULL; _owner = NULL; //指向持有ObjectMonitor的线程/ _WaitSet = NULL; //处于wait状态的线程队列,等待被唤醒 _WaitSetLock = 0 ; _Responsible = NULL ; _succ = NULL ; _cxq = NULL ; FreeNext = NULL ; _EntryList = NULL ; //等待锁的线程队列 _SpinFreq = 0 ; _SpinClock = 0 ; OwnerIsThread = 0 ; _previous_owner_tid = 0; }monitorenter指令
当JVM执行某个线程的某个方法内部的monitorenter时,它会尝试去获取当前对象对应的monitor的所有权。大体过程如下:
若monior的进入数为0,线程可以进入monitor,并将monitor的进入数置为1,当前线程成为monitor的owner(拥有这把锁的线程)
若线程已拥有monitor的所有权,允许它重入monitor,则进入monitor的进入数加1(记录线程拥有锁的次数);
若其他线程已经占有monitor的所有权,那么当前尝试获取monitor的所有权的线程会被阻塞,直到monitor的进入数变为0,才能重新尝试获取monitor的所有权;
monitorexit指令
- 执行monitorexit指令的线程一定是拥有当前对象的monitor的所有权的线程;执行monitorexit时会将monitor的进入数减1,当monitor的进入数减为0时,当前线程退出,其他线程可以进入执行代码。
使用:
同步方法
【修饰符】 synchronized 返回值类型 方法名(【形参列表】)【throws 异常列表】{ 方法体 }同步代码块
synchronized(锁对象){ 需要被锁起来的代码 }锁的释放:当synchronized锁的代码全部执行完,才会释放锁。
原理概述:被synchronized表示的方法会先判断当前对象的监视器对象是否被占用
- 被占用:加入队列,等待锁被释放
- 未被占用:占用当前监视器对象,修改其信息表示以占用,执行代码,结束后释放锁
锁对象选择:
任意类型的对象都可以当做监视线程的锁对象。即类型不限制。
javasynchronized(new Interger()){ 需要被锁起来的代码 }必须保证使用共享数据的多个线程(具有竞争关系的多个线程)使用同一个监视器对象。
同步方法的锁对象是不能自由选择的,是默认的。
- 非静态方法的锁对象是this对象。
- 静态方法的锁对象是当前类的Class对象。 只要是同一个类,那么Class就一定是同一个。
- 代码块锁的就是代码块中的对象
代码:
静态方法的锁:锁的是当前类,该类中所有被synchronized标识的静态方法竞争一个线程,只有占有了监视器对象才能执行。
javapublic class SafeDemo4 { public static void main(String[] args) { //因为锁的是静态方法,所以只要求是同一个类 TicketSale t1 = new TicketSale("窗口一"); TicketSale t2 = new TicketSale("窗口二"); TicketSale t3 = new TicketSale("窗口三"); t1.start(); t2.start(); t3.start(); } } class TicketSale extends Thread{ private static int i = 1000; public TicketSale(String name) { super(name); } @Override public void run() { while(i>=1){ saleOneTicket(); } } //如果不是静态方法,则三个对象的不一样,其锁信息无法交互。 public static synchronized void saleOneTicket(){ if(i>=1){ try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } i--; System.out.println(Thread.currentThread().getName() +"卖出1张票,剩余" + i +"张"); } } }非静态方法的锁:锁的是this对象。由该对象调用,且被synchronized表示的方法竞争一把锁
javapublic class SafeDemo3 { public static void main(String[] args) { //因为锁的是非静态方法,所以要创建一个对象,使用Thread代理该对象。 TicketRunnable t = new TicketRunnable(); Thread t1 = new Thread(t,"窗口一"); Thread t2 = new Thread(t,"窗口二"); Thread t3 = new Thread(t,"窗口三"); t1.start(); t2.start(); t3.start(); } } class TicketRunnable implements Runnable{ private int i = 10; @Override public void run() { while(i>=1){ saleOneTicket(); } } public synchronized void saleOneTicket(){ if(i>=1){//锁的代码内部也需要进行条件判断 try { Thread.sleep(10);//这里加入休眠是为了让问题暴露的明显问题 } catch (InterruptedException e) { e.printStackTrace(); } i--; System.out.println(Thread.currentThread().getName() +"卖出1张票,剩余" + i +"张"); } } }代码块的锁:锁的是传入对象
javaclass TicketSale extends Thread{ private static int i = 100; private static Object lock = new Object();//必须是静态的 public TicketSale(String name) { super(name); } @Override public void run() { while(i>=1){ synchronized (TicketSale.class) {//锁的是当前类对象 if (i >= 1) {//内部也需要条件判断 try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } i--; System.out.println(getName() + "卖出1张票,剩余" + i + "张"); } } } } }
Lock锁
ReentrantLock
可重入锁:同一个线程在外层方法获取锁的时候,在该方法内调用另一个锁对象的方法时,会自动获得锁。
公平锁:也就是在锁上等待时间最长的线程将获得锁的使用权
限时等待:tryLock方法来实现,可以选择传入时间参数,表示等待指定的时间,无参则表示立即返回锁申请的结果
class Ticket{
private Integer number = 20;
private ReentrantLock lock = new ReentrantLock();
public void sale(){
//加锁
lock.lock();
//boolean b = lock.tryLock(1000, TimeUnit.MILLISECONDS)
if (number <= 0) {
System.out.println("票已售罄!");
//释放锁
lock.unlock();
return;
}
try {
Thread.sleep(200);
number--;
System.out.println(Thread.currentThread().getName() + "买票成功,当前剩余:" + number);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}ReentrantLock和synchronized区别
(1)synchronized是独占锁,加锁和解锁的过程自动进行,易于操作,但不够灵活。ReentrantLock也是独占锁,加锁和解锁的过程需要手动进行,不易操作,但非常灵活。
(2)synchronized可重入,因为加锁和解锁自动进行,不必担心最后是否释放锁;ReentrantLock也可重入,但加锁和解锁需要手动进行,且次数需一样,否则其他线程无法获得锁。
(3)synchronized不可响应中断,一个线程获取不到锁就一直等着;ReentrantLock可以响应中断。
(4)synchronzied锁的是对象,锁是保存在对象头里面的,根据对象头数据来标识是否有线程获得锁/争抢锁;ReentrantLock锁的是线程,根据进入的线程和int类型的state标识锁的获得/争抢。
ReentrantReadWriteLock读写锁
对共享资源有读和写的操作,且写操作没有读操作那么频繁。在没有写操作的时候,多个线程同时读一个资源没有任何问题,所以应该允许多个线程同时读取共享资源;但是如果一个线程想去写这些共享资源,就不应该允许其他线程对该资源进行读和写的操作了。大部分只是读数据,写数据很少,如果仅仅是读数据的话并不会影响数据正确性(出现脏读),而如果在这种业务场景下,依然使用独占锁的话,很显然这将是出现性能瓶颈的地方。针对这种读多写少的情况,java还提供了另外一个实现Lock接口的ReentrantReadWriteLock(读写锁)。读写锁允许同一时刻被多个读线程访问,但是在写线程访问时,所有的读线程和其他的写线程都会被阻塞。
class MyCache{
private volatile Map<String, String> cache= new HashMap<>();
// 加入读写锁
ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
public void put(String key, String value){
//加写锁
rwl.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName() + " 开始写入!");
Thread.sleep(500);
cache.put(key, value);
System.out.println(Thread.currentThread().getName() + " 写入成功!");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//释放写锁
rwl.writeLock().unlock();
}
}
public void get(String key){
//加入读锁
rwl.readLock().lock();
try {
System.out.println(Thread.currentThread().getName() + " 开始读出!");
Thread.sleep(500);
String value = cache.get(key);
System.out.println(Thread.currentThread().getName() + " 读出成功!" + value);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//释放读锁
rwl.readLock().unlock();
}
}
}等待唤醒机制
线程间通信(synchronized)
wait():线程不再活动,不再参与调度。
notify:随机选取一个wait对象释放。
notifyAll:释放所通知对象的 wait set 上的全部线程。
注意:
- 当这上面方法不是线程的监视器对象【同步锁对象】调用时,会报IllegalMonitorStateException (非法监视器异常)
- 被通知线程被唤醒后也不一定能立即恢复执行,因为它当初中断的地方是在同步块内,而此刻它已经不持有锁,所以她需要再次尝试去获取锁(很可能面临其它线程的竞争),成功后才能在当初调用 wait 方法之后的地方恢复执行。
案例:多个厨师和服务员
案例:有家餐馆的取餐口比较小,只能放10份快餐,厨师做完快餐放在取餐口的工作台上,服务员从这个工作台取出快餐给顾客。现在有多个厨师和多个服务员。
1、为什么cook和remove的条件判断处if改为while?
因为该线程唤醒之后并不一定满足条件,若用if,因为之前判断过了就不会在判断了。
eg:现在有10盘菜,假设厨师1条件判断成立,进入wait。厨师二条件判断成立,进入wait。服务员1端走一盘菜,剩余9,并且唤醒了厨师 1。厨师1制作了一盘菜,剩余10,并唤醒了厨师2。厨师2因为之前if里面的代码已经执行了,继续向下,制作了一盘菜,剩余11,溢出。
2、为什么要将notify修改为notifyAll?
因为notify是随机唤醒一个线程,可能导致最后所有线程均wait。
eg:假设只能放1盘菜,现在有1盘菜。厨师1判断条件成立,进入wait。厨师2判断条件成立进入wait。服务员1端走1盘菜,剩余0,并唤醒服务员2。服务员2判断条件成立,进入wait。服务员1判断条件成立,进入wait。
public class TestMian {
public static void main(String[] args) {
WorkBench w=new WorkBench();
//创建厨师线程,并指定线程名
new Thread("厨师1"){
@Override
public void run() {
while (true) {
w.cook();
}
}
}.start();
//创建服务员线程,并制定线程名
new Thread("服务员1"){
@Override
public void run() {
while (true) {
w.remove();
}
}
}.start();
new Thread("厨师2"){
@Override
public void run() {
while (true) {
w.cook();
}
}
}.start();
new Thread("服务员2"){
@Override
public void run() {
while (true) {
w.remove();
}
}
}.start();
}
}
class WorkBench{
private final int MAX_COUNT=1;
private int total;
//锁住当前对象
synchronized void cook(){
while(total>=MAX_COUNT){
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
Thread.sleep(100);
} catch (Exception e) {
throw new RuntimeException(e);
}
total++;
System.out.println(Thread.currentThread().getName()+"制作了一份,总份数为:"+total);
this.notifyAll();
}
synchronized void remove(){
while(total<=0){
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
Thread.sleep(100);
} catch (Exception e) {
throw new RuntimeException(e);
}
total--;
System.out.println(Thread.currentThread().getName()+"拿走了一份,总份数为:"+total);
this.notifyAll();
}
}线程通信(Condition)
class ShareDataOne {
private Integer number = 0;
final Lock lock = new ReentrantLock(); // 初始化lock锁
final Condition condition = lock.newCondition(); // 初始化condition对象
/**
* 增加1
*/
public void increment() throws InterruptedException {
lock.lock(); // 加锁
try {
// 1. 判断
while (number != 0) {
// this.wait();
condition.await();
}
// 2. 干活
number++;
System.out.println(Thread.currentThread().getName() + ": " + number);
// 3. 通知
// this.notifyAll();
condition.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
/**
* 减少1
*/
public void decrement() throws InterruptedException {
lock.lock();
try {
// 1. 判断
while (number != 1) {
// this.wait();
condition.await();
}
// 2. 干活
number--;
System.out.println(Thread.currentThread().getName() + ": " + number);
// 3. 通知
//this.notifyAll();
condition.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}定制化调用通信
/*
多线程之间按顺序调用,实现A->B->C。三个线程启动,要求如下:
AA打印5次,BB打印10次,CC打印15次
接着
AA打印5次,BB打印10次,CC打印15次
。。。打印10轮
*/
class ShareDataTwo {
private Integer flag = 1; // 线程标识位,通过它区分线程切换
private final Lock lock = new ReentrantLock();
private final Condition condition1 = lock.newCondition();
private final Condition condition2 = lock.newCondition();
private final Condition condition3 = lock.newCondition();
public void print5() {
lock.lock();
try {
while (flag != 1) {
condition1.await();
}
for (int i = 0; i < 5; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + (i + 1));
}
flag = 2;
condition2.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void print10() {
lock.lock();
try {
while (flag != 2) {
condition2.await();
}
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + (i + 1));
}
flag = 3;
condition3.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void print15() {
lock.lock();
try {
while (flag != 3) {
condition3.await();
}
for (int i = 0; i < 15; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + (i + 1));
}
flag = 1;
condition1.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
public class ThreadOrderAccess {
public static void main(String[] args) {
ShareDataTwo sdt = new ShareDataTwo();
new Thread(()->{
for (int i = 0; i < 10; i++) {
sdt.print5();
}
}, "AAA").start();
new Thread(()->{
for (int i = 0; i < 10; i++) {
sdt.print10();
}
}, "BBB").start();
new Thread(()->{
for (int i = 0; i < 10; i++) {
sdt.print15();
}
}, "CCC").start();
}
}线程生命周期
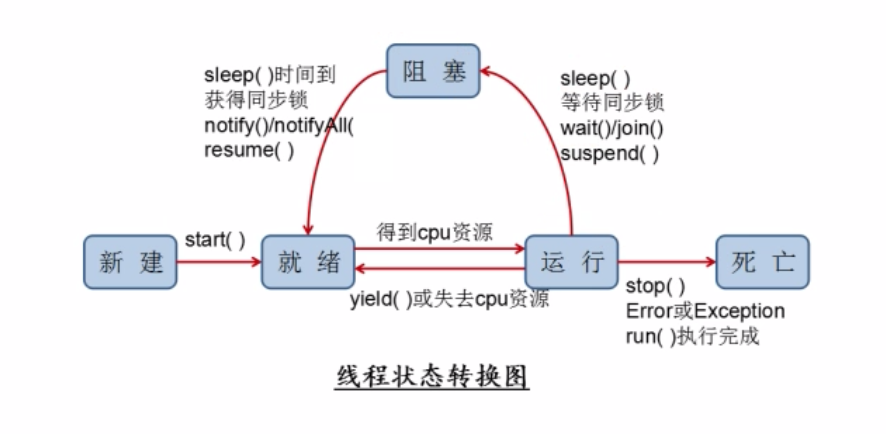
jdk1.5前
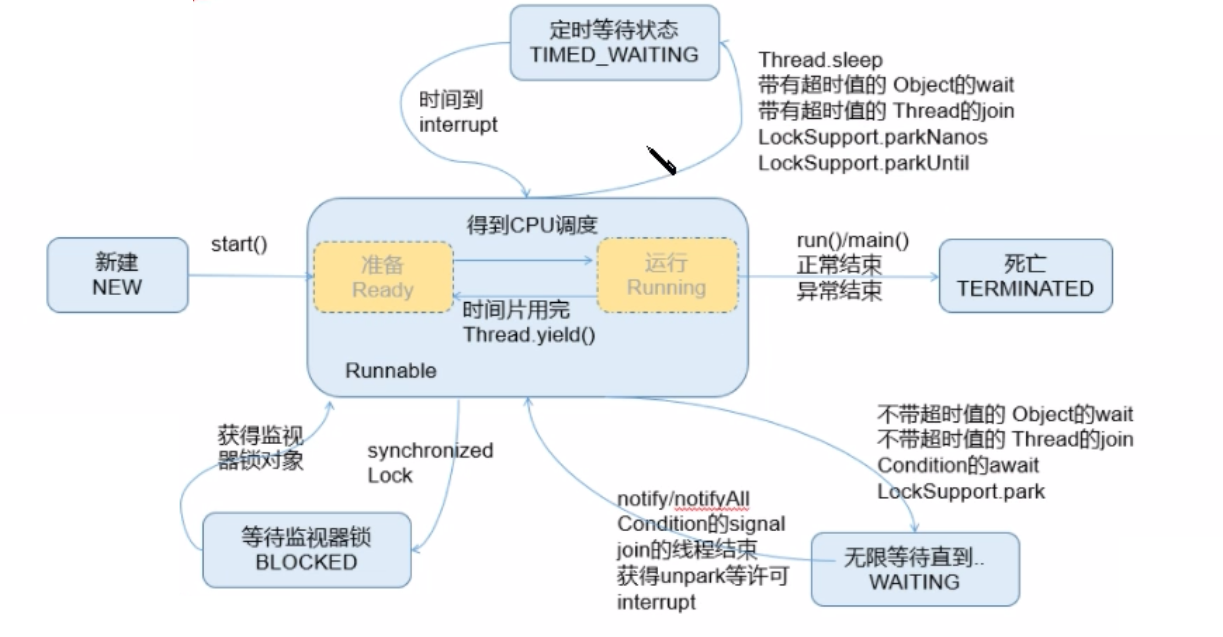
jdk1.5后
死锁
释放锁的操作
- 当前线程的同步方法、同步代码块执行结束会释放锁。
- 当前线程在同步代码块、同步方法中出现了未处理的Error或Exception,导致当前线程异常结束会释放锁。
- 当前线程在同步代码块、同步方法中执行了锁对象的wait()方法,当前线程被挂起,并释放锁。
不会释放锁的操作
- 线程执行同步代码块或同步方法时,程序调用Thread.sleep()、Thread.yield()方法暂停当前线程的执行。
- 线程执行同步代码块时,其他线程调用了该线程的suspend()方法将该该线程挂起,该线程不会释放锁(同步监视器)。应尽量避免使用suspend()和resume()这样的过时来控制线程。
导致死锁
不同的线程分别锁住对方需要的同步监视器对象不释放,都在等待对方先放弃时就形成了线程的死锁。一旦出现死锁,整个程序既不会发生异常,也不会给出任何提示,只是所有线程处于阻塞状态,无法继续。
javaeg://若是出现第一个线程仅占据了goods锁,但是还未来得及占据money锁,第二个线程就占据了money锁,就会卡死。 public class TestDeadLock { public static void main(String[] args) { Object g = new Object(); Object m = new Object(); Owner s = new Owner(g,m); Customer c = new Customer(g,m); new Thread(s).start();//同时开始两个线程 new Thread(c).start(); } } class Owner implements Runnable{ private Object goods; private Object money; public Owner(Object goods, Object money) { super(); this.goods = goods; this.money = money; } @Override public void run() { synchronized (goods) { System.out.println("先给钱");//第一个线程先占据goods的锁,在占据money的锁 synchronized (money) { System.out.println("发货"); } } } } class Customer implements Runnable{ private Object goods; private Object money; public Customer(Object goods, Object money) { super(); this.goods = goods; this.money = money; } @Override public void run() { synchronized (money) { System.out.println("先发货");//第二个线程先占据money的锁,在占据goods的锁 synchronized (goods) { System.out.println("再给钱"); } } } }
死锁问题排除
jps(命令行操作)(JVM Process Status Tool):显示当前系统的 Java 进程情况
jstack(命令行操作):java虚拟机自带的一种堆栈跟踪工具,查看Java进程内的线程堆栈信息,使用jstack命令查看线程堆栈信息时可能会看到的线程的几种状态:
- NEW 未启动的。
- RUNNABLE 运行中。
- BLOCKED 受阻塞并等待监视器锁。
- WATING 等待另一个线程执行特定操作。
- TIMED_WATING 有时限的等待另一个线程的特定操作。
- TERMINATED 已退出的。
如果出现:Found one Java-level deadlock 代表死锁

并发容器类
Vector或者synchronizedList
- vector:内存消耗比较大,适合一次增量比较大的情况
- SynchronizedList:迭代器涉及的代码没有加上线程同步代码
public static void main(String[] args) {
//List<String> list = new Vector<>();
List<String> list = Collections.synchronizedList(new ArrayList<>());
for (int i = 0; i < 200; i++) {
new Thread(()->{
list.add(UUID.randomUUID().toString().substring(0, 8));
System.out.println(list);
}, String.valueOf(i)).start();
}
}CopyOnWrite容器
CopyOnWrite容器(简称COW容器)即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
//CopyOnWrite并发容器用于读多写少的并发场景。比如:白名单,黑名单。假如我们有一个搜索网站,用户在这个网站的搜索框中,输入关键字搜索内容,但是某些关键字不允许被搜索。这些不能被搜索的关键字会被放在一个黑名单当中,黑名单一定周期才会更新一次。
public static void main(String[] args) {
//List<String> list = new Vector<>();
//List<String> list = Collections.synchronizedList(new ArrayList<>());
List<String> list = new CopyOnWriteArrayList<>();
for (int i = 0; i < 200; i++) {
new Thread(()->{
list.add(UUID.randomUUID().toString().substring(0, 8));
System.out.println(list);
}, String.valueOf(i)).start();
}
}ConcurrentHashMap
JUC提供的CopyOnWrite容器实现类有:CopyOnWriteArrayList和CopyOnWriteArraySet。对于Map而言,java.util.concurrent提供了ConcurrentHashMap作为线程安全的map。
同步容器和并发容器
同步容器可以简单地理解为通过synchronized来实现同步的容器。同步容器会导致多个线程中对容器方法调用的串行执行,降低并发性,因为它们都是以容器自身对象为锁。在并发下进行迭代的读和写时并不是线程安全的。如:Vector、Stack、HashTable、Collections类的静态工厂方法创建的类(如Collections.synchronizedList)
并发容器是针对多个线程并发访问而设计的,在jdk5.0引入了concurrent包,其中提供了很多并发容器,如ConcurrentHashMap、CopyOnWriteArrayList等。
ConcurrentHashMap:内部采用Segment结构,进行两次Hash进行定位,写时只对Segment加锁
CopyOnWriteArrayList:CopyOnWrite写时复制一份新的,在新的上面修改,然后把引用指向新的。只能实现数据的最终一致性,非实时一致的;代替List,适用于读操作为主的情况JUC辅助类
CountDownLatch(倒计数器)
例如:在手机上安装一个应用程序,假如需要5个子进程检查服务授权,那么主进程会维护一个计数器,初始计数就是5。用户每同意一个授权该计数器减1,当计数减为0时,主进程才启动,否则就只有阻塞等待了。
- new CountDownLatch(int count) //实例化一个倒计数器,count指定初始计数
- countDown() // 每调用一次,计数减一
- await() //等待,当计数减到0时,阻塞线程(可以是一个,也可以是多个)并行执行
public class CountDownLatchDemo {
/**
* main方法也是一个进程,在这里是主进程,即上锁的同学
*
* @param args
*/
public static void main(String[] args) throws InterruptedException {
// 初始化计数器,初始计数为6
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 0; i < 6; i++) {
new Thread(()->{
try {
// 每个同学墨迹几秒钟
TimeUnit.SECONDS.sleep(new Random().nextInt(5));
System.out.println(Thread.currentThread().getName() + " 同学出门了");
// 调用countDown()计算减1
countDownLatch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, String.valueOf(i)).start();
}
// 调用计算器的await方法,等待6位同学都出来
countDownLatch.await();
System.out.println("值班同学锁门了");
}
}CountDownLatch 与 join 方法的区别
调用一个子线程的 join()方法后,该线程会一直被阻塞直到该线程运行完毕。而 CountDownLatch 则使用计数器允许子线程运行完毕或者运行中时候递减计数,也就是 CountDownLatch 可以在子线程运行任何时候让 await 方法返回而不一定必须等到线程结束(只要调用countDownLatch.countDown()即可);另外使用线程池来管理线程时候一般都是直接添加 Runnable 到线程池这时候就没有办法在调用线程的 join 方法了,countDownLatch 相比 Join 方法让我们对线程同步有更灵活的控制。
CyclicBarrier(循环栅栏)
- CyclicBarrier(int parties, Runnable barrierAction) 创建一个CyclicBarrier实例,parties指定参与相互等待的线程数,barrierAction一个可选的Runnable命令,该命令只在每个屏障点运行一次,可以在执行后续业务之前共享状态。该操作由最后一个进入屏障点的线程执行。
- CyclicBarrier(int parties) 创建一个CyclicBarrier实例,parties指定参与相互等待的线程数。
- await() 该方法被调用时表示当前线程已经到达屏障点,当前线程阻塞进入休眠状态,直到所有线程都到达屏障点,当前线程才会被唤醒。
public class CyclicBarrierDemo {
public static void main(String[] args) {
CyclicBarrier cyclicBarrier = new CyclicBarrier(3, () -> {
System.out.println(Thread.currentThread().getName() + " 过关了");
});
for (int i = 0; i < 3; i++) {
new Thread(()->{
try {
System.out.println(Thread.currentThread().getName() + " 开始第一关");
TimeUnit.SECONDS.sleep(new Random().nextInt(4));
System.out.println(Thread.currentThread().getName() + " 开始打boss");
//开始等待,需要有三个线程执行到该位置,才会唤醒
cyclicBarrier.await();
System.out.println(Thread.currentThread().getName() + " 开始第二关");
TimeUnit.SECONDS.sleep(new Random().nextInt(4));
System.out.println(Thread.currentThread().getName() + " 开始打boss");
cyclicBarrier.await();
System.out.println(Thread.currentThread().getName() + " 开始第三关");
TimeUnit.SECONDS.sleep(new Random().nextInt(4));
System.out.println(Thread.currentThread().getName() + " 开始打boss");
cyclicBarrier.await();
} catch (Exception e) {
e.printStackTrace();
}
}, String.valueOf(i)).start();
}
}
}
//输出
//注意:所有的"过关了"都是由最后到达await方法的线程执行打印的
1 开始第一关
2 开始第一关
0 开始第一关
0 开始打boss
2 开始打boss
1 开始打boss
1 过关了
0 开始第二关
2 开始第二关
1 开始第二关
1 开始打boss
0 开始打boss
2 开始打boss
2 过关了
1 开始第三关
2 开始第三关
0 开始第三关
1 开始打boss
0 开始打boss
2 开始打boss
2 过关了CyclicBarrier和CountDownLatch的区别?
CountDownLatch的计数器只能使用一次,而CyclicBarrier的计数器可以使用reset()方法重置,可以使用多次,所以CyclicBarrier能够处理更为复杂的场景;CountDownLatch允许一个或多个线程等待一组事件的产生,而CyclicBarrier用于等待其他线程运行到栅栏位置。
Semaphore(信号量)
Semaphore可以控制同时访问的线程个数。非常适合需求量大,而资源又很紧张的情况。比如给定一个资源数目有限的资源池,假设资源数目为N,每一个线程均可获取一个资源,但是当资源分配完毕时,后来线程需要阻塞等待,直到前面已持有资源的线程释放资源之后才能继续。
- public Semaphore(int permits) // 构造方法,permits指资源数目(信号量)
- public void acquire() throws InterruptedException // 占用资源,当一个线程调用acquire操作时,它要么通过成功获取信号量(信号量减1),要么一直等下去,直到有线程释放信号量,或超时。
- public void release() // (释放)实际上会将信号量的值加1,然后唤醒等待的线程。
public class SemaphoreDemo {
public static void main(String[] args) {
// 初始化信号量,3个车位
Semaphore semaphore = new Semaphore(3);
// 6个线程,模拟6辆车
for (int i = 0; i < 6; i++) {
new Thread(()->{
try {
// 抢占一个停车位
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + " 抢到了一个停车位!!");
// 停一会儿车
TimeUnit.SECONDS.sleep(new Random().nextInt(10));
System.out.println(Thread.currentThread().getName() + " 离开停车位!!");
// 开走,释放一个停车位
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, String.valueOf(i)).start();
}
}
}
//输出
0 抢到了一个停车位!!
1 抢到了一个停车位!!
2 抢到了一个停车位!!
1 离开停车位!!
3 抢到了一个停车位!!
2 离开停车位!!
4 抢到了一个停车位!!
0 离开停车位!!
5 抢到了一个停车位!!
5 离开停车位!!
3 离开停车位!!
4 离开停车位!!Callable接口
Thread类和Runnable接口都不允许声明检查型异常,也不能定义返回值。java5开始,提供了Callable接口,是Runable接口的增强版。用Call()方法作为线程的执行体,增强了之前的run()方法。因为call方法可以有返回值,也可以声明抛出异常。
FutureTask:未来的任务,用它就干一件事,异步调用。通常用它解决耗时任务,挂起堵塞问题。
在主线程中需要执行比较耗时的操作时,但又不想阻塞主线程时,可以把这些作业交给Future对象在后台完成,当主线程将来需要时,就可以通过Future对象获得后台作业的计算结果或者执行状态。
一般FutureTask多用于耗时的计算,主线程可以在完成自己的任务后,再去获取结果。
FutureTask仅在call方法完成时才能get结果;如果计算尚未完成,则阻塞 get 方法。
一旦计算完成,就不能再重新开始或取消计算。get方法获取结果只有在计算完成时获取,否则会一直阻塞直到任务转入完成状态,然后会返回结果或者抛出异常。
创建Callable的实现类,并重写call()方法,该方法为线程执行体,并且该方法有返回值
创建Callable的实例。
实例化FutureTask类,参数为Callable接口实现类的对象,FutureTask封装了Callable对象call()方法的返回值
创建多线程Thread对象来启动线程,参数为FutureTask对象。
通过FutureTask类的对象的get()方法来获取线程结束后的返回值
java/** * 1. 创建Callable的实现类,并重写call()方法,该方法为线程执行体,并且该方法有返回值 */ class MyCallableThread implements Callable<Integer>{ @Override public Integer call() throws Exception { System.out.println(Thread.currentThread().getName() + "执行了!"); return 200; } } public class CallableDemo { public static void main(String[] args) throws ExecutionException, InterruptedException { // 2. 创建Callable的实例,并用FutureTask类来包装Callable对象 // 3. 创建FutureTask对象,需要一个Callable类型的参数 FutureTask task = new FutureTask<Integer>(new MyCallableThread()); // 4. 创建多线程,由于FutureTask的本质是Runnable的实现类,所以第一个参数可以直接使用task new Thread(task, "threadName").start(); //new Thread(task, "threadName2").start(); /*while (!task.isDone()) { System.out.println("wait..."); }*/ System.out.println(task.get()); System.out.println(Thread.currentThread().getName() + " over!"); } } 注意: 1. 为了防止主线程阻塞,建议get方法放到最后 2. 只计算一次,FutureTask会复用之前计算过得结果,不想复用之前的计算结果。怎么办?再创建一个FutureTask对象即可。
阻塞队列(BlockingQueue)
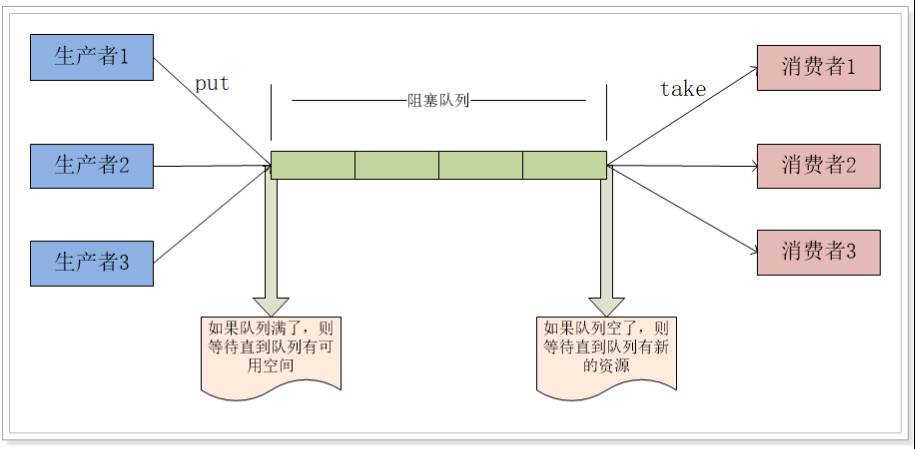
概述
在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦条件满足,被挂起的线程又会自动被唤起。BlockingQueue是为了解决多线程中数据高效安全传输而提出的。从阻塞这个词可以看出,在某些情况下对阻塞队列的访问可能会造成阻塞。被阻塞的情况主要有如下两种:
当队列满了的时候进行入队列操作
当队列空了的时候进行出队列操作
因此,当一个线程试图对一个已经满了的队列进行入队列操作时,它将会被阻塞,除非有另一个线程做了出队列操作;同样,当一个线程试图对一个空队列进行出队列操作时,它将会被阻塞,除非有另一个线程进行了入队列操作。
阻塞队列主要用在生产者/消费者的场景,下面这幅图展示了一个线程生产、一个线程消费的场景:
实现类
BlockingQueue接口主要有以下7个实现类:
- <font color="red">ArrayBlockingQueue:由数组结构组成的有界阻塞队列。</font>
- <font color="red">LinkedBlockingQueue:由链表结构组成的有界(但大小默认值为integer.MAX_VALUE)阻塞队列。</font>
- PriorityBlockingQueue:支持优先级排序的无界阻塞队列。
- DelayQueue:使用优先级队列实现的延迟无界阻塞队列。
- <font color="red">SynchronousQueue:不存储元素的阻塞队列,也即单个元素的队列。</font>
- LinkedTransferQueue:由链表组成的无界阻塞队列。
- LinkedBlockingDeque:由链表组成的双向阻塞队列。
方法
| 抛出异常 | 特殊值 | 阻塞 | 超时 | |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| 移除 | remove() | poll() | take() | poll(time, unit) |
| 检查 | element() | peek() | 不可用 | 不可用 |
抛出异常
add正常执行返回true,element(不删除)和remove返回阻塞队列中的第一个元素 当阻塞队列满时,再往队列里add插入元素会抛IllegalStateException:Queue full 当阻塞队列空时,再往队列里remove移除元素会抛NoSuchElementException 当阻塞队列空时,再调用element检查元素会抛出NoSuchElementException
特定值 插入方法,成功ture失败false 移除方法,成功返回出队列的元素,队列里没有就返回null 检查方法,成功返回队列中的元素,没有返回null
一直阻塞
如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。 当阻塞队列满时,再往队列里put元素,队列会一直阻塞生产者线程直到put数据or响应中断退出 当阻塞队列空时,再从队列里take元素,队列会一直阻塞消费者线程直到队列可用
超时退出
如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。 返回一个特定值以告知该操作是否成功(典型的是 true / false)。
public class BlockingQueueDemo {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> queue = new ArrayBlockingQueue<>(3);
// 第一组方法:add remove element
// System.out.println(queue.add("a"));
// System.out.println(queue.add("b"));
// System.out.println(queue.add("c"));
// // System.out.println(queue.add("d"));
// // System.out.println(queue.element());
// System.out.println(queue.remove());
// System.out.println(queue.remove());
// System.out.println(queue.remove());
// //System.out.println(queue.remove());
// //System.out.println(queue.element());
// 第二组:offer poll peek
// System.out.println(queue.offer("a"));
// System.out.println(queue.offer("b"));
// System.out.println(queue.offer("c"));
// System.out.println(queue.offer("d"));
// System.out.println(queue.peek());
// System.out.println(queue.poll());
// System.out.println(queue.poll());
// System.out.println(queue.poll());
// System.out.println(queue.poll());
// System.out.println(queue.peek());
// 第三组:put take
// queue.put("a");
// queue.put("b");
// queue.put("c");
// System.out.println(queue.take());
// queue.put("d");
// System.out.println(queue.take());
// System.out.println(queue.take());
// System.out.println(queue.take());
// 第四组:offer poll
System.out.println(queue.offer("a"));
System.out.println(queue.offer("b"));
System.out.println(queue.offer("c"));
System.out.println(queue.offer("d", 5, TimeUnit.SECONDS));
}
}ThreadPool线程池
Executors工具类
线程池的优势: 线程池做的工作主要是<font color="red">控制运行的线程数量,如果线程数量超过了最大数量,超出数量的线程排队等候</font>,等线程任务执行完毕,再从队列中取出任务来执行。
它的主要特点为:<font color="red">线程复用;控制最大并发数;管理线程。</font>
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的销耗。
- 提高响应速度。当任务到达时,任务可以不需要等待线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会销耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
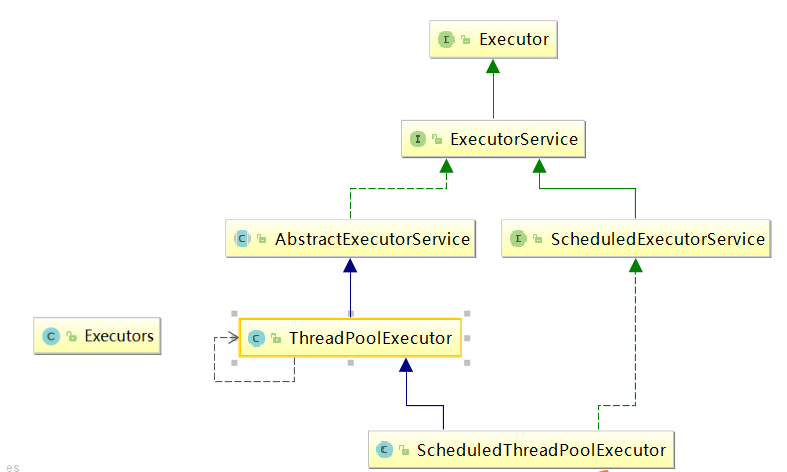
常见方法
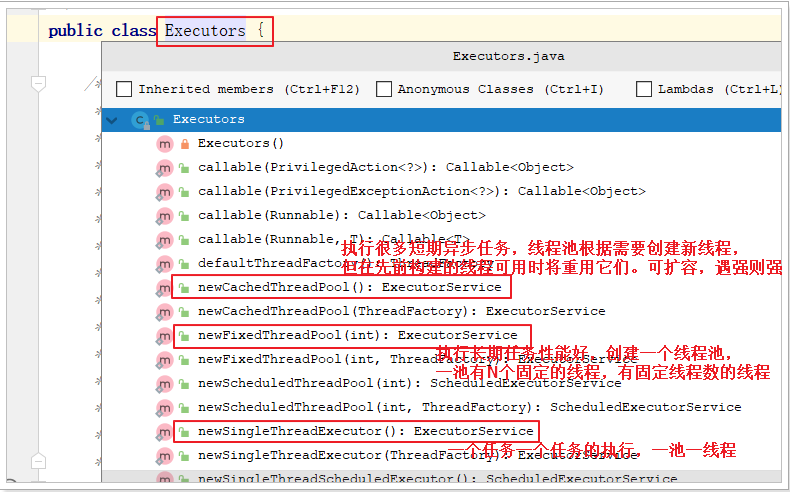
本质都是ThreadPoolExecutor的实例化对象,只是具体参数值不同。
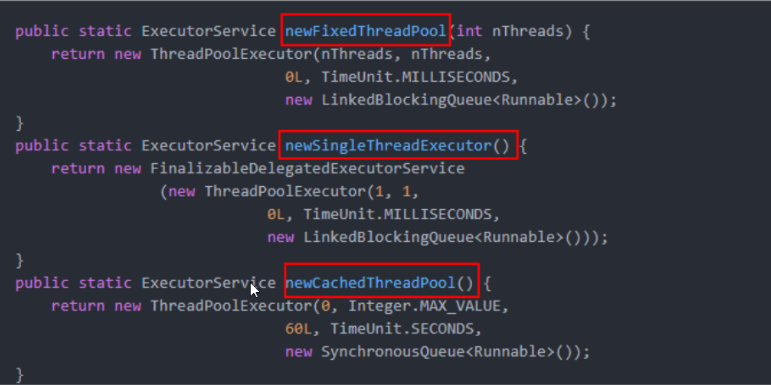
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
1. corePoolSize:线程池中的常驻核心线程数
2. maximumPoolSize:线程池中能够容纳同时 执行的最大线程数,此值必须大于等于1
3. keepAliveTime:多余的空闲线程的存活时间 当前池中线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁直到 只剩下corePoolSize个线程为止
4. unit:keepAliveTime的单位
5. workQueue:任务队列,被提交但尚未被执行的任务
6. threadFactory:表示生成线程池中工作线程的线程工厂, 用于创建线程,一般默认的即可。
7. handler:拒绝策略,表示当队列满了,并且工作线程大于 等于线程池的最大线程数(maximumPoolSize)时,如何来拒绝 请求执行的runnable的策略
public class ThreadPoolDemo {
public static void main(String[] args) {
// 创建单一线程的连接池
// ExecutorService threadPool = Executors.newSingleThreadExecutor();
// 创建固定数线程的连接池
// ExecutorService threadPool = Executors.newFixedThreadPool(3);
// 可扩容连接池
// ExecutorService threadPool = Executors.newCachedThreadPool();
//创建延时任务的连接池
//ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(3);
//executor.scheduleAtFixedRate(()->{
// System.out.println("任务正在执行:"+ new Date());
//},5 , 3 , TimeUnit.SECONDS);
// 自定义连接池
ExecutorService threadPool = new ThreadPoolExecutor(2, 5,
2, TimeUnit.SECONDS, new ArrayBlockingQueue<>(3),
Executors.defaultThreadFactory(),
//new ThreadPoolExecutor.AbortPolicy()
//new ThreadPoolExecutor.CallerRunsPolicy()
//new ThreadPoolExecutor.DiscardOldestPolicy()
//new ThreadPoolExecutor.DiscardPolicy()
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("自定义拒绝策略");
}
}
);
try {
for (int i = 0; i < 9; i++) {
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "执行了业务逻辑");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown();
}
}
}CPU密集型 vs IO密集型
开发中我们可以把任务分为计算(CPU)密集型和IO密集型。
计算(CPU)密集型任务大部份时间用来做计算、逻辑判断,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,任务同时进行的数量应当等于CPU的核心数。一般公式:线程数量=CPU核数+1个
IO密集型CPU消耗很少,任务的大部分时间都在等待IO操作完成(99%的时间都花在IO上,花在CPU上的时间很少)。此类任务,任务越多,CPU效率越高,但也有一个限度。大部分任务都是IO密集型任务,比如Web应用。一般公式:线程数量=CPU核数/(1-阻塞系数) 阻塞系数为0.8~0.9之间
线程池处理逻辑
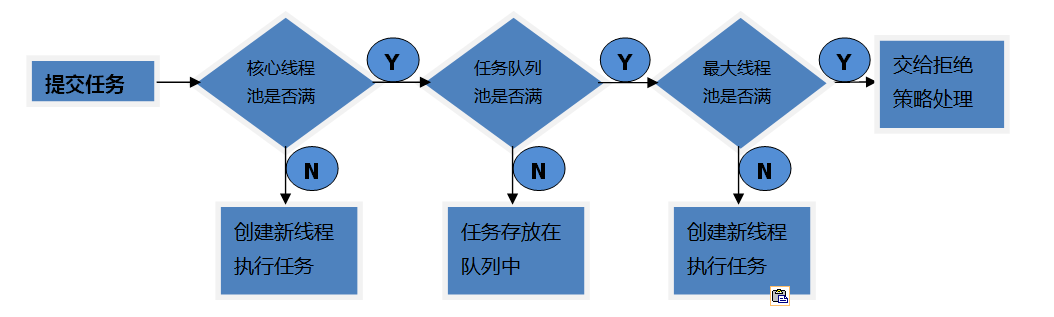
在创建了线程池后,线程池中的线程数为零。
当调用execute()方法添加一个请求任务时,线程池会做出如下判断:
- 如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务;
- 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列;
- 如果这个时候队列满了且正在运行的线程数量还小于maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
- 如果队列满了且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略来执行。
当一个线程完成任务时,它会从队列中取下一个任务来执行。
当一个线程无事可做超过一定的时间(keepAliveTime)时,线程会判断:
如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉。
所以线程池的所有任务完成后,它最终会收缩到corePoolSize的大小。
拒绝策略
一般我们创建线程池时,为防止资源被耗尽,任务队列都会选择创建有界任务队列,但种模式下如果出现任务队列已满且线程池创建的线程数达到你设置的最大线程数时,这时就需要你指定ThreadPoolExecutor的RejectedExecutionHandler参数即合理的拒绝策略,来处理线程池"超载"的情况。
ThreadPoolExecutor自带的拒绝策略如下:
- AbortPolicy(默认):直接抛出RejectedExecutionException异常阻止系统正常运行
- CallerRunsPolicy:“调用者运行”一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量。
- DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加人队列中 尝试再次提交当前任务。
- DiscardPolicy:该策略默默地丢弃无法处理的任务,不予任何处理也不抛出异常。 如果允许任务丢失,这是最好的一种策略。
以上内置的策略均实现了RejectedExecutionHandler接口,也可以自己扩展RejectedExecutionHandler接口,定义自己的拒绝策略
多线程原理
java内存模型(JMM)
JMM即为JAVA 内存模型(java memory model)。因为在不同的硬件生产商和不同的操作系统下,内存的访问逻辑有一定的差异,结果就是当你的代码在某个系统环境下运行良好,并且线程安全,但是换了个系统就出现各种问题。Java内存模型,就是为了屏蔽系统和硬件的差异,让一套代码在不同平台下能到达相同的访问结果。JMM从java 5开始的JSR-133发布后,已经成熟和完善起来。
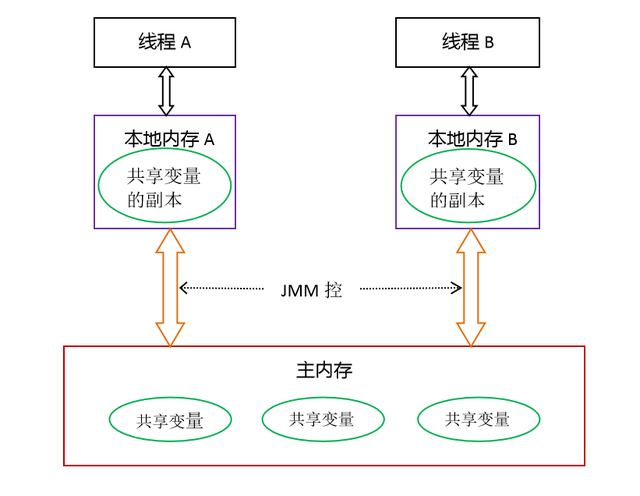
JMM规定了内存主要划分为主内存和工作内存两种。
主内存:保存了所有的变量。 共享变量:如果一个变量被多个线程使用,那么这个变量会在每个线程的工作内存中保有一个副本,这种变量就是共享变量。 工作内存:每个线程都有自己的工作内存,线程独享,保存了线程用到的变量副本(主内存共享变量的一份拷贝)。工作内存负责与线程交互,也负责与主内存交互。
此处的主内存和工作内存跟JVM内存划分(堆、栈、方法区)是在不同的维度上进行的,如果非要对应起来,主内存对应的是Java堆中的对象实例部分,工作内存对应的是栈中的部分区域,从更底层的来说,主内存对应的是硬件的物理内存,工作内存对应的是寄存器和高速缓存。
JMM对共享内存的操作做出了如下两条规定:
- 线程对共享内存的所有操作都必须在自己的工作内存中进行,不能直接从主内存中读写;
- 不同线程无法直接访问其他线程工作内存中的变量,因此共享变量的值传递需要通过主内存完成。
内存模型的三大特性:
原子性:即不可分割性。比如 a=0;(a非long和double类型) 这个操作是不可分割的,那么我们说这个操作是原子操作。再比如:a++; 这个操作实际是a = a + 1;是可分割的,所以他不是一个原子操作。非原子操作都会存在线程安全问题,需要使用同步技术(sychronized)或者锁(Lock)来让它变成一个原子操作。一个操作是原子操作,那么我们称它具有原子性。java的concurrent包下提供了一些原子类,我们可以通过阅读API来了解这些原子类的用法。比如:AtomicInteger、AtomicLong、AtomicReference等。
可见性:每个线程都有自己的工作内存,所以当某个线程修改完某个变量之后,在其他的线程中,未必能观察到该变量已经被修改。在 Java 中 volatile、synchronized 和 final 实现可见性。volatile只能让被他修饰内容具有可见性,但不能保证它具有原子性。
有序性:java的有序性跟线程相关。一个线程内部所有操作都是有序的,如果是多个线程所有操作都是无序的。因为JMM的工作内存和主内存之间存在延迟,而且java会对一些指令进行重新排序。volatile和synchronized可以保证程序的有序性,很多程序员只理解这两个关键字的执行互斥,而没有很好的理解到volatile和synchronized也能保证指令不进行重排序。
volatile关键字
Java语言允许线程访问共享变量,为了确保共享变量能被准确和一致的更新,线程应该确保通过排它锁单独获取这个变量。Java语言提供了volatile,在某些情况下比锁要更加方便。如果一个字段被声明为volatile,Java线程内存模型确保所有线程看到这个变量的值是一致的。
在访问volatile变量时不会执行加锁操作,因此也就不会使执行线程阻塞,因此volatile变量是一种比sychronized关键字更轻量级的同步机制。volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不发生乱序执行。
可见性
//未给flag添加volatile修饰,则会陷入死循环,因为主线程修改的值并不会通知Thread线程,会一直阻塞
//使用volatile修饰后,则不会,因为结果修改后会通知其他线程
public class VolatileDemo {
private static Integer flag = 1;
public static void main(String[] args) throws InterruptedException {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("我是子线程工作内存flag的值:" + flag);
while(flag == 1){
}
System.out.println("子线程操作结束..." + flag);
}
}).start();
Thread.sleep(500);
flag = 2;
System.out.println("我是主线程工作内存flag的值:" + flag);
}
}有序性
禁止指令重排序优化。有volatile修饰的变量,赋值后多执行了一个“load addl $0x0, (%esp)”操作,这个操作相当于一个内存屏障(指令重排序时不能把后面的指令重排序到内存屏障之前的位置),只有一个CPU访问内存时,并不需要内存屏障。
非原子性
最终的结果不是10000
class DataOne{
private volatile Integer number = 0;
public Integer incr(){
return ++number;
}
}
public class VolatileAtomicDemo {
public static void main(String[] args) {
DataOne dataOne = new DataOne();
for (int i = 0; i < 10000; i++) {
new Thread(() -> {
System.out.println(dataOne.incr());
}).start();
}
}
}Happen-Before原则
先行发生原则,意思就是当A操作先行发生于B操作,则在发生B操作的时候,操作A产生的影响能被B观察到,“影响”包括修改了内存中的共享变量的值、发送了消息、调用了方法等。
- 程序次序规则(Program Order Rule):在一个线程内,程序的执行规则跟程序的书写规则是一致的,从上往下执行。
- 管程锁定规则(Monitor Lock Rule):一个Unlock的操作肯定先于下一次Lock的操作。这里必须是同一个锁。同理我们可以认为在synchronized同步同一个锁的时候,锁内先行执行的代码,对后续同步该锁的线程来说是完全可见的。
- volatile变量规则(volatile Variable Rule):对同一个volatile的变量,先行发生的写操作,肯定早于后续发生的读操作
- 线程启动规则(Thread Start Rule):Thread对象的start()方法先行发生于此线程的每一个动作
- 线程中止规则(Thread Termination Rule):Thread对象的中止检测(如:Thread.join(),Thread.isAlive()等)操作,必行晚于线程中所有操作
- 线程中断规则(Thread Interruption Rule):对线程的interruption()调用,先于被调用的线程检测中断事件(Thread.interrupted())的发生
- 对象中止规则(Finalizer Rule):一个对象的初始化方法先于一个方法执行Finalizer()方法
- 传递性(Transitivity):如果操作A先于操作B、操作B先于操作C,则操作A先于操作C
以上这些规则保障了happen-before的顺序,如果不符合以上规则,那么在多线程环境下就不能保证执行顺序等同于代码顺序。通过这些条件的判定,仍然很难判断一个线程是否能安全执行,线程安全多数依赖于工具类的安全性来保证。想提高自己对线程是否安全的判断能力,必然需要理解所使用的框架或者工具的实现,并积累线程安全的经验。
CAS
概述
CAS:Compare and Swap。比较并交换的意思。CAS操作有3个基本参数:内存地址A,旧值B,新值C。它的作用是将指定内存地址A的内容与所给的旧值B相比,如果相等,则将其内容替换为指令中提供的新值C;如果不等,则更新失败。类似于修改登陆密码的过程。当用户输入的原密码和数据库中存储的原密码相同,才可以将原密码更新为新密码,否则就不能更新。
CAS是解决多线程并发安全问题的一种乐观锁算法。因为它在对共享变量更新之前,会先比较当前值是否与更新前的值一致,如果一致则更新,如果不一致则循环执行(称为自旋锁),直到当前值与更新前的值一致为止,才执行更新。
在JUC下有个atomic包,有很多原子操作的包装类:它们都是基于CAS解决并发安全问题的(类似在线教育的数据库记录的version版本号)
public class CasDemo {
public static void main(String[] args) {
AtomicInteger i = new AtomicInteger(1);
System.out.println("第一次更新:" + i.compareAndSet(1, 200));
System.out.println("第一次更新后i的值:" + i.get());
System.out.println("第二次更新:" + i.compareAndSet(1, 300));
System.out.println("第二次更新后i的值:" + i.get());
System.out.println("第三次更新:" + i.compareAndSet(200, 300));
System.out.println("第三次更新后i的值:" + i.get());
}
}
//输出结果
第一次更新:true
第一次更新后i的值:200
第二次更新:false
第二次更新后i的值:200
第三次更新:true
第三次更新后i的值:300
//原因
第一次更新:i的值(1)和预期值(1)相同,所以执行了更新操作,把i的值更新为200
第二次更新:i的值(200)和预期值(1)不同,所以不再执行更新操作
第三次更新:i的值(200)和预期值(1)相同,所以执行了更新操作,把i的值更新为300缺点
开销大:在并发量比较高的情况下,如果反复尝试更新某个变量,却又一直更新不成功,会给CPU带来较大的压力
ABA问题:当变量从A修改为B再修改回A时,变量值等于期望值A,但是无法判断是否修改,CAS操作在ABA修改后依然成功。
AtomicStampedReference在构建的时候需要一个类似于版本号的int类型变量stamped,每一次针对共享数据的变化都会导致该stamped的变化(stamped 需要应用程序自身去负责,AtomicStampedReference并不提供,一般使用时间戳作为版本号)
public static void main(String[] args) {
AtomicStampedReference<String> r = new AtomicStampedReference<String>("a",1);
System.out.println("修改前版本号:"+r.getStamp()+" ,值: "+ r.getReference());
r.compareAndSet("a","b",1,2);
System.out.println("第一次修改后版本号:"+r.getStamp()+" ,值 "+ r.getReference());
r.compareAndSet("b","a",1,3);
System.out.println("第二次修改后版本号:"+r.getStamp()+" ,值 "+ r.getReference());
}不能保证代码块的原子性:CAS机制所保证的只是一个变量的原子性操作,而不能保证整个代码块的原子性。
AQS
AbstractQueuedSynchronizer抽象队列同步器简称AQS,它是实现同步器的基础组件(框架),juc下面Lock的实现以及一些并发工具类(Semaphore、CountDownLatch、CyclicBarrier等)就是通过AQS来实现的。具体用法是通过继承AQS实现其模板方法,然后将子类作为同步组件的内部类。
AQS将大部分的同步逻辑均已经实现好,继承的自定义同步器只需要实现state的获取(acquire)和释放(release)的逻辑代码就可以,主要包括下面方法:
- tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。
- tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。
- tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
- tryReleaseShared(int):共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回true,否则返回false。
- isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。
也就是说:
通过AQS可以实现独占锁(只有一个线程可以获取到锁,如:ReentrantLock),也可以实现共享锁(多个线程都可以获取到锁Semaphore/CountDownLatch等)
ThreadLocal
Thread类中,有个ThreadLocal.ThreadLocalMap 的成员变量。
ThreadLocalMap内部维护了Entry数组,每个Entry代表一个完整的对象,key是ThreadLocal本身,value是ThreadLocal储存的对应泛型对象值。
当我们调用ThreadLocal的set()或get()方法时,实际上是通过当前线程的引用,获取到线程的ThreadLocalMap,然后在这个ThreadLocalMap中存取真正的对象。
JDK早期ThreadLocal设计
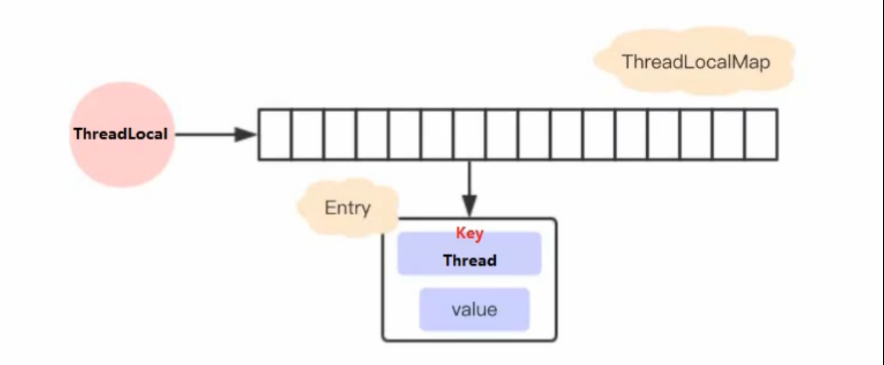
JDK现今ThreadLocal设计
优势:由Thread维护ThreadLocalMap,当线程结束后就可以gc回收,减少内存占用。
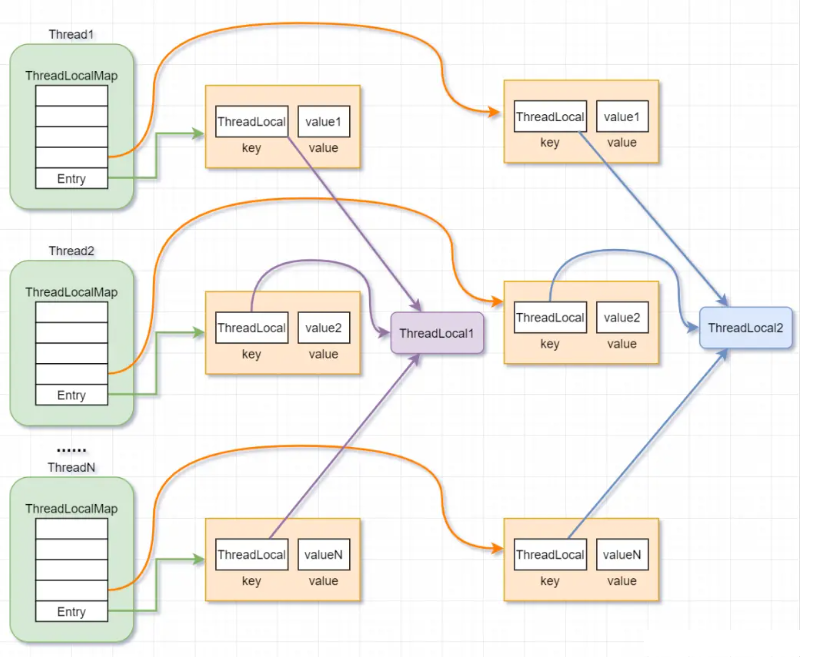
//创建了username和userId两个ThreadLocal静态对象,以set为例,当调用对应ThreadLocal的set时,本质上就是调用当前线程的ThreadLocalMap对象,然后计算出这个ThreadLocal(作为key)的HashCode,将储存的value值放入算出的位置,get同理
public class AuthContextHolder {
private static ThreadLocal<Long> userId = new ThreadLocal<Long>();
private static ThreadLocal<String> username = new ThreadLocal<String>();
public static void setUserId(Long _userId) {
userId.set(_userId);
}
public static Long getUserId() {
return userId.get();
}
public static void removeUserId() {
userId.remove();
}
public static void setUsername(String _username) {
username.set(_username);
}
public static String getUsername() {
return username.get();
}
public static void removeUsername() {
username.remove();
}
}ThreadLocal的生命周期和当前线程的生命周期一样,当使用线程池时,复用线程,ThreadLocal储存的数据就会重复出现,所以在使用结束之后最好调用一下remove方法
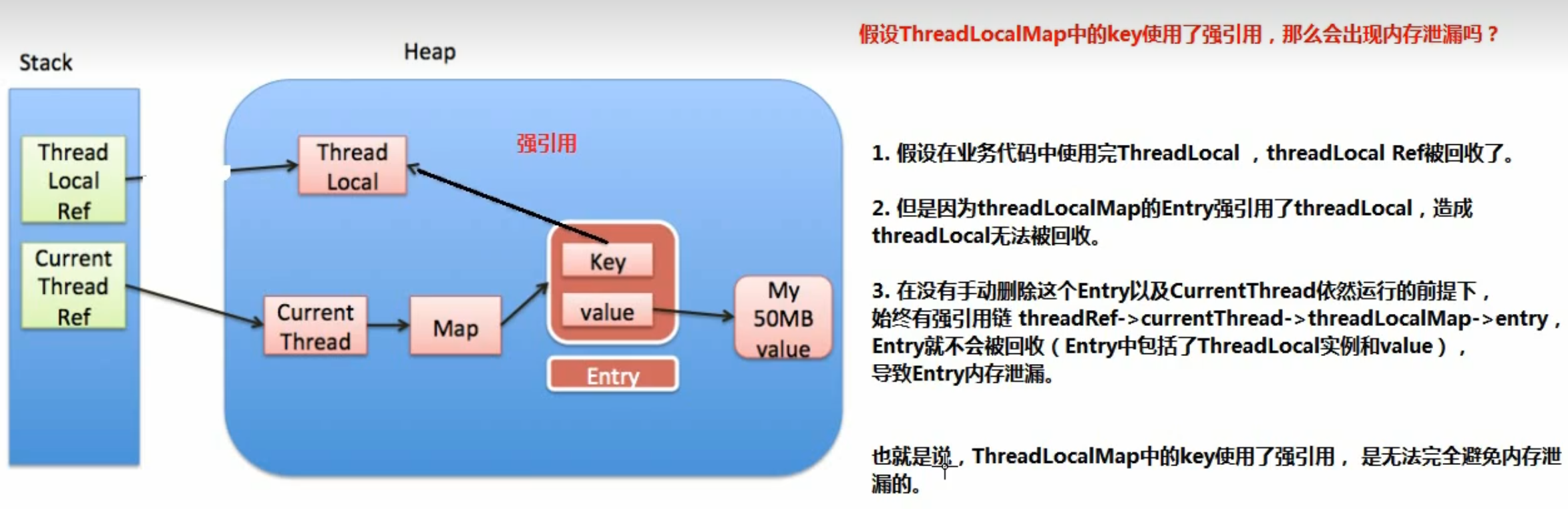
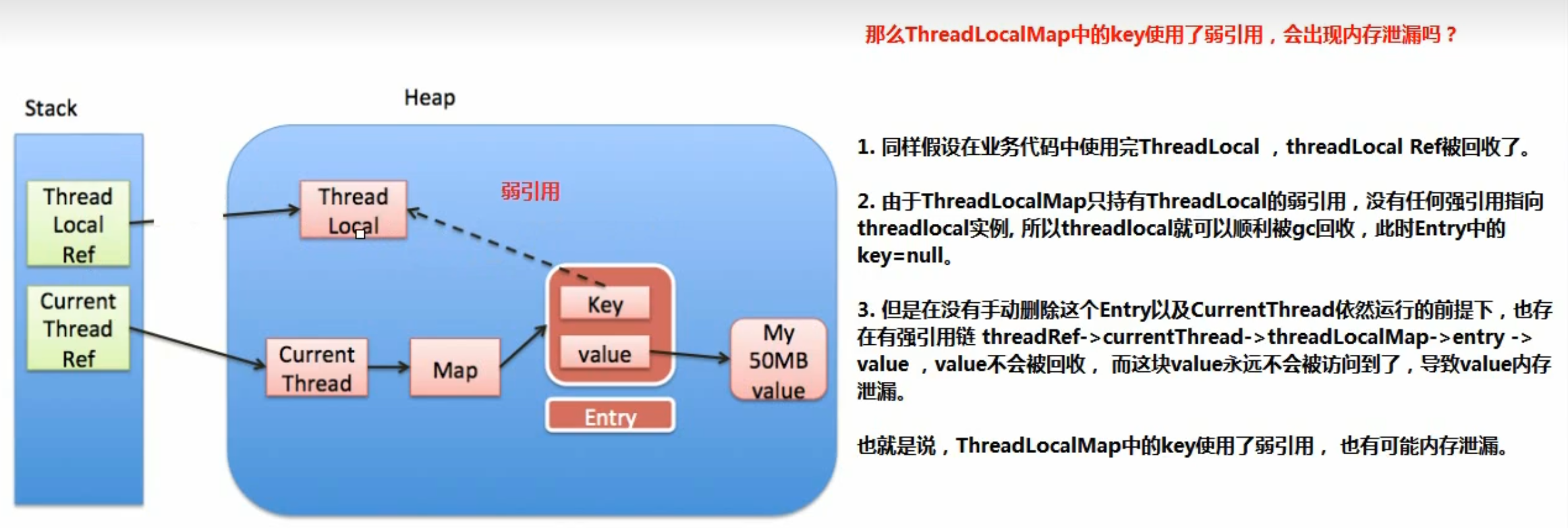
CompletableFuture异步编程
CompletableFuture是Java 8中引入的一个类,它实现了Future接口,用于异步编程,可以链式调用多个任务。
异步任务的创建并不会立刻执行,而是会在抢到CPU时间片后才会执行,异步任务的本质就是以开启线程的方式去执行任务!!!
Future使用
1.在没有阻塞的情况下,无法对Future的结果执行进一步的操作。Future不会告知你它什么时候完成,你如果想要得到结果,必须通过一个get()方法,该方法会阻塞直到结果可用为止。
2.它不具备将回调函数附加到Future后并在Future的结果可用时自动调用回调的能力,而且它无法解决任务相互依赖的问题。 如上述案例中,filterWordFuture和newsFuture的结果不能自动发送给replaceFuture, 需要在replaceFuture中手动获取,所以使用Future不能轻而易举地创建异步工作流。
3.不能将多个Future合并在一起。 假设你有多种不同的Future, 你想在它们全部并行完成后然后运行某个函数,Future很难独立完成这一需要。
4.没有异常处理。 Future提供的方法中没有专门的API应对异常处理,还需要开发者自己手动异常处理。
public static void main(String[] args) throws ExecutionException, InterruptedException {
//创建一个最多运行5个线程的线程池
ExecutorService executor = Executors.newFixedThreadPool(5);
// step 1: 读取敏感词汇 => thread1
Future<String[]> filterWordFuture = executor.submit(() -> {
String str = CommonUtils.readFile("E:\\project\\main\\java\\filter_words.txt");
String[] filterWords = str.split(",");
return filterWords;
});
// step 2: 读取新闻稿 => thread2
Future<String> newsFuture = executor.submit(() -> {
return CommonUtils.readFile("E:\\project\\competable-future\\src\\main\\java\\news.txt");
});
// step 3: 替换操作 => thread3
Future<String> replaceFuture = executor.submit(() -> {
String[] words = filterWordFuture.get();
String news = newsFuture.get();
for (String word : words) {
if (news.indexOf(word) > 0) {
news = news.replace(word, "**");
}
}
return news;
});
// step 4: 打印输出替换后的新闻稿 => main
String filteredNews = replaceFuture.get();
System.out.println("filteredNews = " + filteredNews);
//关闭线程池
executor.shutdown();
}CompletableFuture使用
开启异步任务
static CompletableFuture<Void> runAsync(Runnable runnable)
static CompletableFuture<Void> runAsync(Runnable runnable,Executor executor):
如果你要异步运行某些耗时的后台任务,并且不想从任务中返回任何内容,则可以使用CompletableFuture.runAsync()方法。它接受一个Runnable接口实现类对象,方法返回CompletableFuture<Void>对象
javaCompletableFuture.runAsync(() -> { CommonUtils.printTheadLog("读取文件开始"); CommonUtils.sleepSecond(3); CommonUtils.printTheadLog("读取文件结束"); });static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)
static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier,Executor executor):它入参一个Supplier<U>供给者,用于供给带返回值的异步任务,并返回CompletableFuture<U>,其中的U是供给者给值的类型
javaCompletableFuture<String> future = CompletableFuture.supplyAsync(() -> { String news = CommonUtils.readFile("E:\\project\\competable-future\\src\\main\\java\\news.txt"); return news; });注意:
- CompletableFuture会从全局ForkJoinPool.commonPool()线程池获取来执行这些任务,当然, 你也可以创建一个线程池,并将其传递给runAsync() 和supplyAsync()方法,以使它们在从你指定的线程池获得的线程中执行任务,将虚拟线程池传入可以使用到虚拟线程。
- 如果所有completableFuture共享一个线程池,那么一旦有异步任务执行一些很慢的I/O操作,就会导致线程池中所有的线程都阻塞在I/O操作上,从而造成线程饥饿,进而影响整个系统的性能。所以,强烈建议你要根据不同的业务类型创建不同的线程池,以避免互相干扰
异步任务回调
CompletalbeFuture.get()方法是阻塞的。调用时它会阻塞等待,直到这个Future完成,并在完成后返回结果。但是,很多时候这不是我们想要的。对于构建异步系统,我们应该能够将回调附加到CompletableFuture上,当这个Future完成时,该回调自动被调用,这样,我们就不必等待结果了,然后在Future的回调函数内编写完成Future之后需要执行的逻辑。我们可以使用thenApply(),thenAccept()和thenRun()方法,它们可以把回调函数附加到CompletableFuture上
CompletableFuture<U> thenApply(Function<? super T,? extends U> fn):会在 CompletableFuture 完成的同一个线程中执行,所以它不会创建新的线程。
CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn):和supplyAsync中的异步任务使用的是同一个线程池。
CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn, Executor executor): 会在一个新的线程中执行这个函数,如果有传入连接池就从连接池中获取,未传入就是要底层的连接池。
通过附加一系列thenApply()回调方法,在CompletableFuture上编写一系列转换序列。一个thenApply()方法的结果可以传递给序列中的下一个。
javaCompletableFuture.supplyAsync(() -> { String filterWordContent = CommonUtils.readFile("E:\\project\\competable-future\\src\\main\\java\\filter_words.txt"); return filterWordContent; }).thenApply(content -> { String[] filterWords = content.split(","); return filterWords; });CompletableFuture<Void> thenAccept(Consumer<? super T> action):如果不想从回调函数返回结果,而只想在Future完成后运行一些代码,则可以使用thenAccpet(),该方法通常用作回调链中的最后一个回调
CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action)
CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action Executor executor)
CompletableFuture<Void> thenRun(Runnable action):只是想从CompletableFuture的链式操作得到一个完成的通知,甚至都不使用上一个链式操作的结果,那么CompletableFuture.thenRun()会是你最佳的选择。
CompletableFuture<Void> thenRunAsync(Runnable action)
CompletableFuture<Void> thenRunAsync(Runnable action,Executor executor)
异步任务的编排
编排2个依赖关系的异步任务 thenCompose()
CompletableFuture<U> thenCompose(Function<? super T, ? extends CompletionStage<U>> fn)
CompletableFuture<U> thenComposeAsync(Function<? super T, ? extends CompletionStage<U>> fn)
CompletableFuture<U> thenComposeAsync(Function<? super T, ? extends CompletionStage<U>> fn, Executor executor):连接(编排)两个依赖关系的异步任务(CompletableFuture对象),就使用thenCompose()方法
javapublic static CompletableFuture<String> readFileFuture(String fileName) { return CompletableFuture.supplyAsync(()->{ String filterWordsContent = CommonUtils.readFile(fileName); return filterWordsContent; }); } public static CompletableFuture<String[]> splitFuture(String content) { return CompletableFuture.supplyAsync(()->{ String[] filterWords = content.split(","); return filterWords; }); } //使用thenApply //结果会被CompletableFuture嵌套 CompletableFuture<CompletableFuture<String[]>>future=readFileFuture("E:\\filter_words.txt").thenApply(content -> { return splitFuture(content); });
编排2个非依赖关系的异步任务 thenCombine()
CompletableFuture<V> thenCombine(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn)
CompletableFuture<V> thenCombineAsync(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn)
CompletableFuture<V> thenCombineAsync(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn, Executor executor):当两个Future都完成时,才将两个异步任务的结果传递给thenCombine的回调函数进一步处理!!!
javaT:是第一个任务的结果 U:是第二个任务的结果 V:经BiFunction应用转换后的结果 //读取新闻稿(news.txt) CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> { String newsContent = CommonUtils.readFile("E:\\project\\competable-future\\src\\main\\java\\news.txt"); return newsContent; }); //替换敏感词 CompletableFuture<String> future3 = future1.thenCombine(future2, (words, newsContent) -> { for (String word : words) { if (newsContent.indexOf(word) > 0) { newsContent = newsContent.replace(word, "**"); } } return newsContent; });
合并多个异步 allOf / anyOf
public static CompletableFuture<Void> allOf(CompletableFuture<?>... cfs):需要传入一个数组或者多个元素,返回一个新的 CompletableFuture,这个新的 CompletableFuture 会在所有的输入 CompletableFuture 都完成时完成。
javapublic static CompletableFuture<String> readFileFuture(String fileName){ return CompletableFuture.supplyAsync(()->{ String content = CommonUtils.readFile(fileName); return content; }); } public static void main(String[] args) { //需求:统计news1.txt、new2.txt、new3.txt文件中包合CompLetableFuture.关键字的文件的个数 // step 1: 创建List集合存储文件名 List<String> files = Arrays.asList("E:\\news1.txt", "E:\\news2.txt", "E:\\news3.txt"); // step 2: 根据文件名调用readFileFuture创建多个CompletableFuture,并存入List集合中 List<CompletableFuture<String>> readFileFutureList = files.stream().map(file -> { return readFileFuture(file); }).collect(Collectors.toList()); // step 3: 把List集合转换成数组待用,以便传入allOf方法中 int len = readFileFutureList.size(); CompletableFuture[] readFileArray = readFileFutureList.toArray(new CompletableFuture[len]); // step 4: 使用allOf方法合并多个异步任务 CompletableFuture<Void> allOfFuture = CompletableFuture.allOf(readFileArray); // step 5: 当多个异步任务都完成后,使用回调操作文件结果,统计符合条件的文件个数 CompletableFuture<Long> countFuture = allOfFuture.thenApply(v -> { return readFileFutureList.stream(). map(future -> future.join()). filter(content -> content.contains("CompletableFuture")). count(); }); // step 6: 主线程打印输出文件个数 Long count = countFuture.join(); System.out.println("count = " + count); }public static CompletableFuture<Object> anyOf(CompletableFuture<?>... cfs):anyOf()返回一个新的CompletableFuture, 新的CompletableFuture的结果和cfs已完成的那个异步任务结果相同。
java//anyOf() 方法返回类型必须是 CompletableFutue <Object>,如果你拥有返回不同类型结果的CompletableFuture,那么你将不知道最终CompletableFuture的类型。 public static void main(String[] args) throws ExecutionException, InterruptedException { //anyOf() CompletableFuture<String> future1 =CompletableFuture.supplyAsync(()->{ CommonUtils.sleepSecond(2); return "Future1的结果"; }); CompletableFuture<String> future2 =CompletableFuture.supplyAsync(()->{ CommonUtils.sleepSecond(1); return "Future2的结果"; }); CompletableFuture<String> future3 =CompletableFuture.supplyAsync(()->{ CommonUtils.sleepSecond(3); return "Future3的结果"; }); CompletableFuture<Object> anyOfFuture = CompletableFuture.anyOf(future1, future2, future3); Object ret = anyOfFuture.get(); System.out.println("ret = " + ret); }
异步任务的异常处理
如果在 supplyAsync 任务中出现异常,后续的 thenApply 和 thenAccept 回调都不会执行, CompletableFuture 将传入异常处理 如果在第一个thenApply中出现异常,第二个 thenApply 和最后的 thenAccept 回调不会被执行,CompletableFuture 将转入异常处理,依次类推
CompletableFuture<T> exceptionally(Function<Throwable, ? extends T> fn)
CompletableFuture<T> exceptionallyAsync(Function<Throwable, ? extends T> fn) // jdk17+
CompletableFuture<T> exceptionallyAsync(Function<Throwable, ? extends T> fn, Executor executor) // jdk17+
java//因为 exceptionally 只处理一次异常,所以常常用在回调链的末端 public static void main(String[] args) { CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> { // int r = 1 / 0; return "result1"; }).thenApply(result -> { CommonUtils.printTheadLog(result); String str = null; int length = str.length(); return result + " result2"; }).thenApply(result -> { return result + " result3"; }).exceptionally(ex ->{ String message = ex.getMessage(); System.out.println("message = " + message); return "Unknown"; }); }CompletableFuture<U> handle(BiFunction<? super T, Throwable, ? extends U> fn)
CompletableFuture<U> handleAsync(BiFunction<? super T, Throwable, ? extends U> fn)
CompletableFuture<U> handleAsync(BiFunction<? super T, Throwable, ? extends U> fn, Executor executor):handle() 表示从异常中恢复 handle() 常常被用来恢复回调链中的一次特定的异常,回调链恢复后可进一步向下传递。
java//如果发生异常,则 result 参数为 null ,否则 ex 参数将为 null,即异步任务不管是否发生异常,handle方法都会执行。所以,handle核心作用在于对上一步异步任务进行现场修复 public static void main(String[] args) throws ExecutionException, InterruptedException { // handle() CommonUtils.printTheadLog("main start"); CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> { int r = 1 / 0; return "result1"; }).handle((result,ex)->{ CommonUtils.printTheadLog("上一步异常的恢复"); if(ex != null){ CommonUtils.printTheadLog("出现异常:" + ex.getMessage()); return "UnKnown"; } return result; }); CommonUtils.printTheadLog("main continue"); String ret = future.get(); CommonUtils.printTheadLog("ret = " + ret); CommonUtils.printTheadLog("main end"); }
异步任务的交互
异步任务的交互是指在异步任务获取结果的速度相比较中,按一定的规则(先到先得)进行下一步处理。
CompletableFuture<U> applyToEither(CompletionStage<? extends T> other, Function<? super T, U> fn)
CompletableFuture<U> applyToEitherAsync(CompletionStage<? extends T> other, Function<? super T, U> fn)
CompletableFuture<U> applyToEitherAsync(CompletionStage<? extends T> other, Function<? super T, U> fn,Executor executor):applyToEither() `把两个异步任务做比较,异步任务先得到结果的,就对其获得的结果进行下一步操作。
javapublic static void main(String[] args) throws ExecutionException, InterruptedException { //异步任务1 CompletableFuture<Integer> future1 = CompletableFuture.supplyAsync(() -> { int x = new Random().nextInt(3); CommonUtils.sleepSecond(x); CommonUtils.printTheadLog("任务1耗时" + x + "秒"); return x; }); //异步任务2 CompletableFuture<Integer> future2 = CompletableFuture.supplyAsync(() -> { int y = new Random().nextInt(3); CommonUtils.sleepSecond(y); CommonUtils.printTheadLog("任务2耗时" + y + "秒"); return y; }); //哪个异步任务结果先到达,使用哪个异步任务的结果 CompletableFuture<Integer> future3 = future1.applyToEither(future2, result -> { CommonUtils.printTheadLog("最先到达的是" + result); return result; }); CommonUtils.sleepSecond(4); Integer ret = future3.get(); CommonUtils.printTheadLog("ret ="+ret); //异步任务交互指两个异步任务,哪个结果先到,就使用哪个结果(先到先用) }CompletableFuture<Void> acceptEither(CompletionStage<? extends T> other, Consumer<? super T> action)
CompletableFuture<Void> acceptEitherAsync(CompletionStage<? extends T> other, Consumer<? super T> action)
CompletableFuture<Void> acceptEitherAsync(CompletionStage<? extends T> other, Consumer<? super T> action,Executor executor):把两个异步任务做比较,异步任务先到结果的,就对先到的结果进行下一步操作(
消费使用),没有返回值。CompletableFuture<Void> runAfterEither(CompletionStage<?> other,Runnable action)
CompletableFuture<Void> runAfterEitherAsync(CompletionStage<?> other,Runnable action)
CompletableFuture<Void> runAfterEitherAsync(CompletionStage<?> other,Runnable action,Executor executor):演示在最先完成的异步任务时得到它完成的通知,没有接收值,也没有返回值。
其他方法
get和join
get() 和 join() 都是CompletableFuture提供的以阻塞方式获取结果的方法,使用时,我们发现,get() 抛出检查时异常,需要程序必须处理;而join() 方法抛出运行时异常,程序可以不处理。所以, join()更适合用在流式编程中。
public static <U> CompletableFuture<U> completedFuture(U value)
返回一个完成的CompletableFuture,通常在你已经知道结果,但需要返回一个 CompletableFuture 对象以满足方法签名要求时使用,也可以用于创建初始默认值。
CompletableFuture<Boolean> res1=CompletableFuture.completedFuture(true);
CompletableFuture<Boolean> res2=CompletableFuture.completedFuture(true);
//插入新加的权限
if(!addPermissionList.isEmpty()){
res1 = VirtualThreadUtil.executorAsync(() -> userPermissionMapper.insertRolePermissions(addPermissionList, roleId) > 0);
}
//删除移出的权限
if(!removePermissionList.isEmpty()){
res2=VirtualThreadUtil.executorAsync(()->userPermissionMapper.removeRolePermissions(removePermissionList,roleId)>0);
}
return res1.thenCombine(res2,(a,b)->a&b).join();ParallelStream 与 CompletableFuture
CompletableFuture 比 ParallelSteam 优点之一是你可以指定Excutor去处理任务。你能选择更合适数量的线程。我们可以选择大于Runtime.getRuntime().availableProcessors()数量的线程。
- 如果你的任务是IO密集型,你应该使用 CompletableFuture;
- 如果你的任务是CPU密集型,使用比处理器更多的线程是没有意义的,所以选择 ParallelSteam,因为它不需要创建线程池,更容易使用。
public static void main(String[] args) {
// CompletableFuture 在流式操作中的优势
// 需求: 创建10个 MyTask 耗时的任务, 统计它们执行完的总耗时
// 方案四:使用CompletableFuture(指定线程数量)
// step 1: 创建10个MyTask对象,每个任务持续1s, 存入List集合
IntStream intStream = IntStream.range(0, 10);
List<MyTask> tasks = intStream.mapToObj(item -> {
return new MyTask(1);
}).collect(Collectors.toList());
// 准备线程池
int N_CPU = Runtime.getRuntime().availableProcessors();
// 设置线程池中的线程的数量至少为10
ExecutorService executor = Executors.newFixedThreadPool(Math.min(tasks.size(),N_CPU * 2));
// step 2: 根据MyTask对象构建10个异步任务
List<CompletableFuture<Integer>> futures = tasks.stream().map(myTask -> {
return CompletableFuture.supplyAsync(()-> {
return myTask.doWork();
},executor);
}).collect(Collectors.toList());
// step 3: 执行异步任务,执行完成后,获取异步任务的结果,存入List集合中,统计总耗时
long start = System.currentTimeMillis();
List<Integer> results = futures
.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList());
long end = System.currentTimeMillis();
double costTime = (end - start) / 1000.0;
System.out.printf("processed %d tasks %.2f second", tasks.size(), costTime);
// 关闭线程池
executor.shutdown();
/**
* 总结
* CompLetabLeFuture可以控制更多的线程数量,而ParalLelstream不能
*/
}虚拟线程
虚拟线程提供了一种更高效、更轻量级的线程模型,可以在 Java 应用程序中创建数百万甚至数十亿个线程,而不会受到操作系统线程数量的限制。
工作原理
传统的物理线程(也叫平台线程)是基于操作系统线程来实现的,而操作系统线程属于重量级的线程,创建和上下文切换都是非常消耗系统资源的;
虚拟线程是工作在物理线程(平台线程)之上的,任务最终还是被物理线程执行的,优点是当虚拟线程检测到它实际上正在执行阻塞IO操作,它不会阻塞正在运行的平台线程,而是从该平台线程卸载自身,将自己的上下文(即堆栈)移动到内存中的其他位置,这样其他的虚拟线程就可以获得这些被释放的物理线程继续执行。当响应返回后,再将其放入ForkJoinPool平台线程的等待列表中
虚拟线程的阻塞成本比平台线程低得多,即移动堆栈的成本,所以虚拟线程中运行的是阻塞任务时才有意义,如果仅进行内存中计算任务是没有的,如果在虚拟线程中运行并行流,实际上还会降低性能
平台线程是被操作系统调度的,而虚拟线程是直接被JDK调度的,因此虚拟线程在切换时可以显著地降低开销。
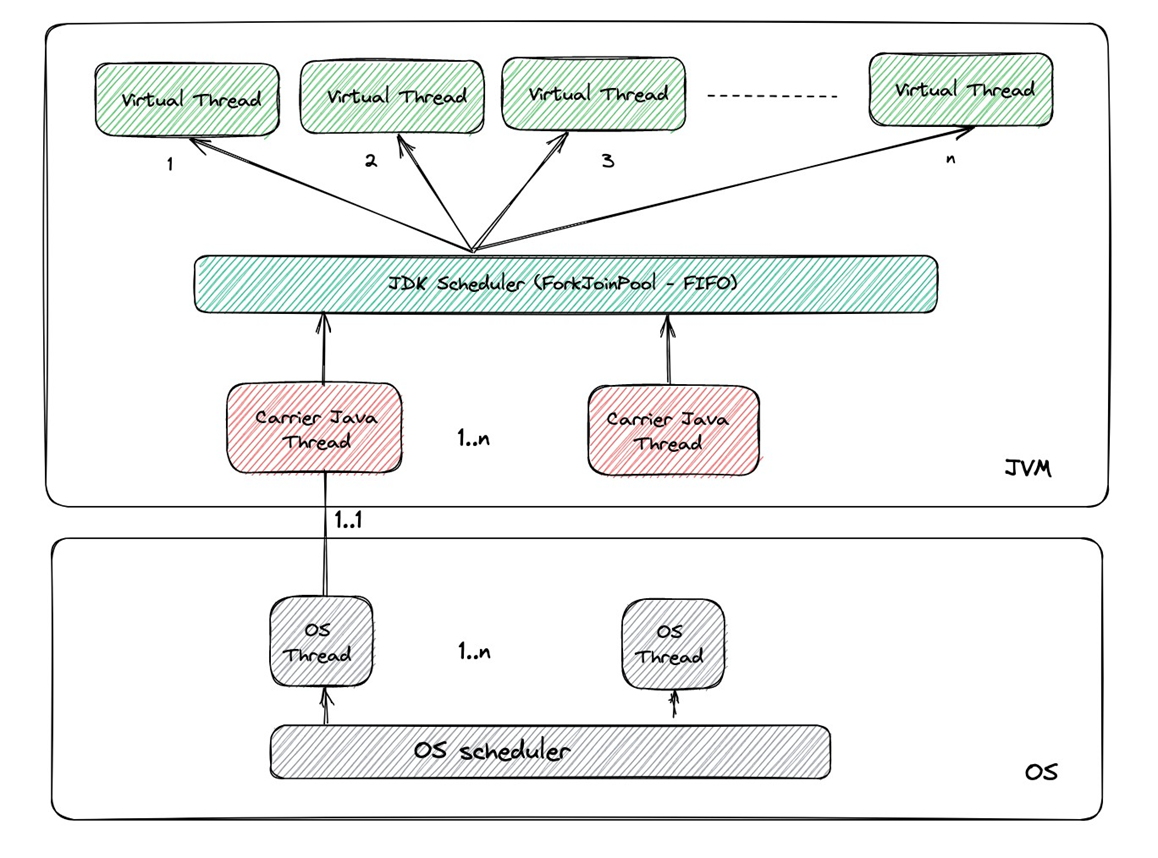
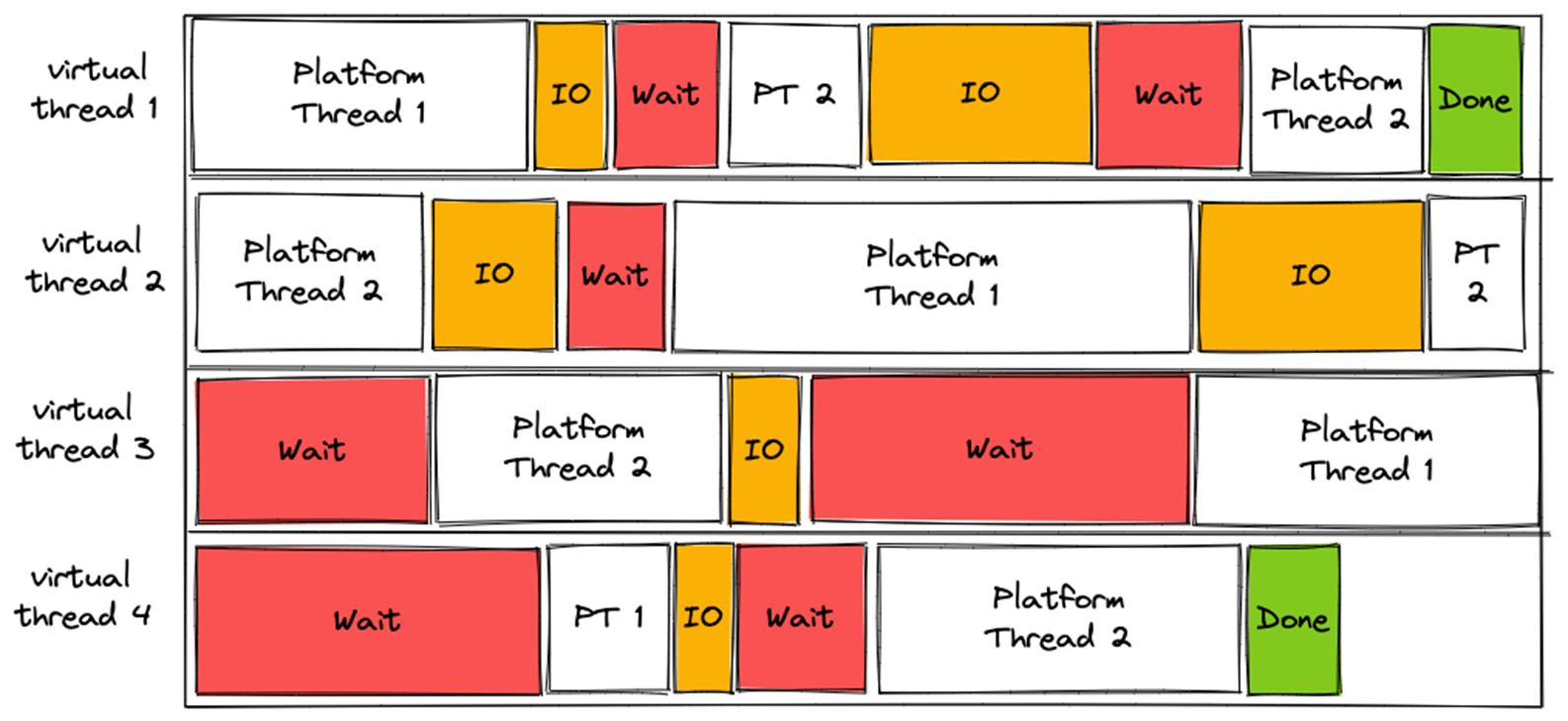
使用注意
- 虚拟线程不是更快的线程,而是为了跑满CPU的性能,提高系统的吞吐量,在其陷入等待之后,让出线程运行其他代码。
- 虚拟线程只适合IO密集型的任务,如果你的任务是CPU密集型的或者需要长时间进行内存计算,那么不要使用虚拟线程。
- 虚拟线程不需要池化,你只需要在需要用到它的时候创建它,JDK会自动完成清理工作。
虚拟线程的使用
方案一:使用Thread.startVirtualThread()方法,方法内部会自动开启线程。
Thread t1 = Thread.startVirtualThread(() -> System.out.println("虚拟线程1执行了"));
方案二:使用Thread.ofVirtual()方法,创建虚拟线程。
Thread t2 = Thread.ofVirtual().name("虚拟线程2")
.start(() -> System.out.println("虚拟线程2执行了"));
t2.join();
Thread t3 = Thread.ofVirtual().name("虚拟线程3")
.unstarted(() -> System.out.println("虚拟线程3执行了"));
t3.start();
t3.join();方案三:通过Thread.ofVirtual().factory()方法获取一个线程工厂,再通过线程工厂创建虚拟线程。
ThreadFactory factory = Thread.ofVirtual().factory();
Thread t4 = factory.newThread(new MyRunnable());方案四:使用Executors.newVirtualThreadPerTaskExecutor()方法,创建虚拟线程
//虚拟线程池不存储任何线程,每次提交一个任务,就会创建一个虚拟线程,执行完后释放该线程
ExecutorService service = Executors.newVirtualThreadPerTaskExecutor();
service.submit(() -> System.out.println("虚拟线程5执行了")); 反射
Class对象
概念:Java所有类型都有Class对象,包括基本数据类型、void、引用数据类型(数组、类、接口、枚举、注解等)。
Class对象获取:
类型名.class ,如:int.class。要求编译时这个类型就是已知,已存在的类型
Class<HashMap> hashMapClass = HashMap.class对象名.getClass() ,如:"hello".getClass();只针对引用数据类型
Class<? extends HashMap> aClass1 = new HashMap<>().getClass();Class.forName("类型的全名称"), 如:Class.forName("java.lang.String");一般是针对普通引用数据类型
ClassLoader类方法getSystemClassLoader获取当前系统的默认的类加载器对象,类加载器对象.loadClass("类型的全名称")
eg: ClassLoader cl = ClassLoader.getSystemClassLoader(); Class c1 = cl.loadClass("java.lang.String");针对同一个类型来说,这四种方式获取到的Class是同一个。也就是说每一种类型在内存中只有唯一的一个Class对象。
类加载的过程
概念:JVM加载类信息到内存中的过程,包括连续的三个步骤:加载、连接、初始化
过程:
加载:load,就是指将类型的class字节码数据读入内存
连接:link
- ①验证:校验合法性等【防止强制修改其它类型文件后缀为class】
- ②准备:准备对应的内存(方法区),创建Class对象,为类变量赋默认值,为静态常量赋初始值。【static final修饰的】
- ③解析:把字节码中的符号引用替换为对应的直接地址引用
初始化:initialize即执行<clinit>类初始化方法,(1)静态类变量的显式赋值代码(2)静态代码块中的代码构成。
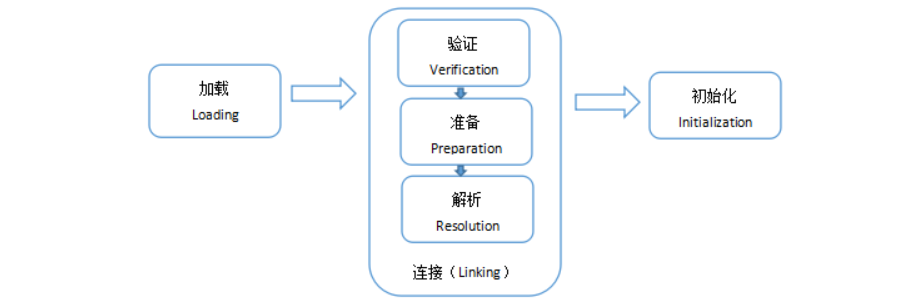
初始化时间:使用才会初始化
类加载时完成初始化
- (1)运行主方法所在的类,要先完成类初始化,再执行main方法
- (2)第一次使用某个类型就是在new它的对象,此时这个类没有初始化的话,先完成类初始化再做实例初始化
- (3)调用某个类的静态成员(类变量和类方法),此时这个类没有初始化的话,先完成类初始化
- (4)子类初始化时,发现它的父类还没有初始化的话,那么先初始化父类
- (5)通过反射操作某个类时,如果这个类没有初始化,也会导致该类先初始化
延迟初始化
- (1)使用某个类的静态的常量(static final),链接阶段就赋值了
- (2)通过子类调用父类的静态变量,静态方法,只会导致父类初始化,不会导致子类初始化,即只有声明静态成员的类才会初始化
- (3)用某个类型声明数组并创建数组对象时,不会导致这个类初始化
类加载模式
类加载器的类型
- 引导类加载器:负责加载最最核心的类库,例如:JRE的核心类库中的rt.jar等。引导类加载器不是Java语言实现的,所以在Java中得不到它的对象。
- 扩展类加载器:负责加载JRE目录下lib文件中的ext扩展库
- 应用程序类加载器:负责程序员自己编写的类、接口等 例如:TestClassLoader是我们自己写的
- 自定义类加载器:存在以下两种特殊使用情况:
- A:字节码文件需要加密,自定义类加载器在加载类的过程中先解密,然后再创建Class对象等。
- B:自定义的类或类路径是在特殊的,特定的路径,和平时其他项目的类路径不同。 例如:tomcat服务器,它的classes是放在 WEB-INF/classes文件夹,而有的系统是把字节码文件放到网络中的某个数据库中,或者是某台文件服务器,和程序运行不在一个服务器。
双亲委托模式
概念:类加载器之间的工作模式被称为“双亲委托模式”。【主要讨论(1)(2)(3)】,从下到上看是否加载过,如果都没有,再从上到下看能否加载,都不能就报错。
作用:为了安全。例如:我自己写一个类,叫做java.lang.String,通过双亲委托模式,加载出来的一定是Java.rt.lang包中的String类,而非自己写的。这样可以避免new出错误的对象
注意:
- 获取某个类的类加载器对象:通过这个类的Class对象.getClassLoader()
- 每一个类加载器都有一个parent属性,记录父加载器。应用程序类加载器---[父类]--->扩展类加载器---[父类]--->引导类加载器
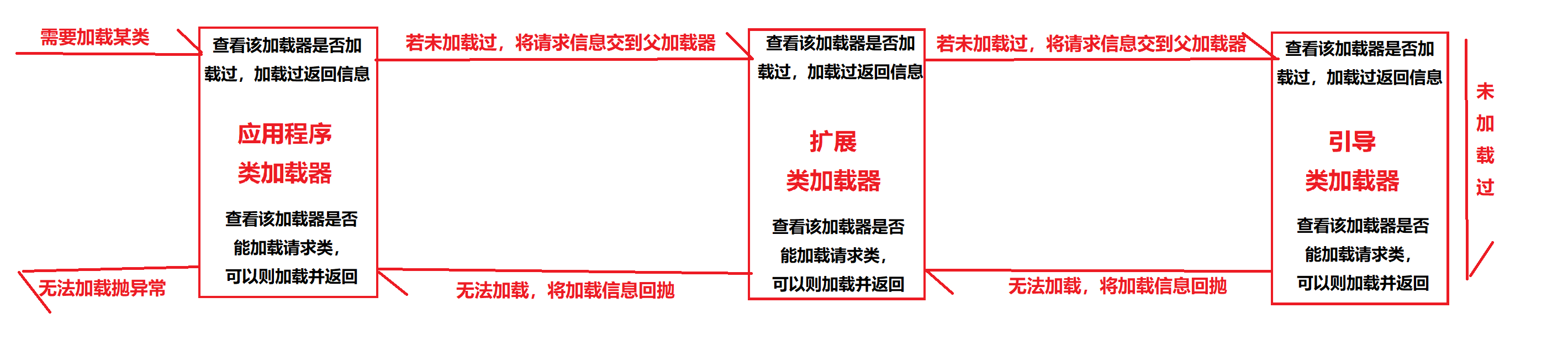
具体步骤: A:当系统需要加载某个类时,同时时应用程序类加载器先接到任务,例如:要加载java.lang.String类型, B:应用程序类加载器接到任务后,会先在方法区搜索这个类的Class对象,如果找到了,说明这个类已经被加载过了,那么就直接返回它的Class对象,不会重复加载。 如果没有找到这个类的Class对象,会把这个任务先提交给“父”加载器,应用程序加载器的父加载器就是扩展类加载器。 C:扩展类加载器接到任务之后,会在方法区搜索这个类的Class对象,如果找到了,说明这个类已经被加载过了,那么就直接返回它的Class对象,不会重复加载。 如果没有找到这个类的Class对象,会把这个任务先提交给“父”加载器,扩展类加载器的父加载器就是引导类加载器,也称为根加载器 D:引导类加载器接到任务之后,会在方法区搜索这个类的Class对象,如果找到了,说明这个类已经被加载过了,那么就直接返回它的Class对象,不会重复加载。 如果没有找到这个类的Class对象,会把在自己负责的区域加载这个类,例如它负责rt.jar等。如果找到了,就返回它的Class对象,如果没找到,就把任务往回传,传给扩展类加载器 E:扩展类加载器接到父加载器回传的任务,就会在他负责的目录下加载这个类,例如jre/lib/ext 如果找到了,就返回它的Class对象,如果没找到,就把任务往回传,传给应用程序类加载器 F:应用程序类加载器接到父加载器回传的任务,就会在他负责的目录下加载这个类,例如:项目路径下(idea中就是out目录) 如果找到了,就返回它的Class对象,如果没找到,就报错ClassNotFoundException。 为什么要从应用程序类加载器提交请求到引导类加载器,而不是直接从引导类加载器开始:因为加载器接到任务后,会先在方法区搜索这个类的Class对象,如果找到了,说明这个类已经被加载过了,那么就直接返回它的Class对象,而大部分需要加载的类都在应用程序类加载器和扩展累加器
反射的基本应用
1、获取类的所有信息
getPackage():获取类的包名
getName():获取类的名称
getModifiers():获取类的修饰符
- 得到一个整型值,通过 Modifier.toString(modifiers)进行转化
getSuperclass():获取父类,单继承
getInterfaces():获取父接口们,多实现
getField("属性名"):获取某一个公共的成员变量
getFields():获取所有的公共的成员变量
getDeclaredField("属性名"):获取某一个已声明的成员变量,不受权限修饰符限制
getDeclaredFields(): 获取所有已声明的成员变量,包括非公共的,私有的等
getConstructor(构造器的形参类型列表) 获取一个公共的构造器
getConstructors(); 获取所有公共的构造器
getDeclaredConstructor(构造器的形参类型列表) 获取一个已声明的构造器,不受权限修饰符限制
getDeclaredConstructors(); //获取所有已声明的构造器
getMethod(方法名,方法的形参类型列表):获取某个公共的方法
getDeclaredMethod(方法名,方法的形参类型列表):获取某个已声明的方法
getMethods() 获取所有公共的方法
getDeclaredMethods() 获取所有已声明的方法
getDeclaredClasses():获取内部类们
javapublic static void main(String[] args)throws Exception { Class clazz = Class.forName("java.lang.String"); //有了String类的Class对象,就可以获取String类的所有信息 //(1)获取类的包名 Package pkg = clazz.getPackage(); System.out.println(pkg); //(2)获取类的名称 String name = clazz.getName(); System.out.println("name = " + name); //(3)获取类的修饰符 int modifiers = clazz.getModifiers(); System.out.println("modifiers = " + modifiers);//整型值:17 System.out.println(Modifier.toString(modifiers));//public final /* Modifier类中的 常量值: 0x开头是十六键 十进制 二进制 public static final int PUBLIC = 0x00000001; ==> 1 1 public static final int PRIVATE = 0x00000002; ==》 2 10 public static final int PROTECTED = 0x00000004; ==》 4 100 public static final int STATIC = 0x00000008; ==> 8 1000 public static final int FINAL = 0x00000010; ==> 16 10000 。。。。 使用2的n次方值来表示某个修饰符,因为这些值的二进制值正好是某一位是1,其余都是0 String 的修饰符 public final 1 ^ 16 ==> 00001 10000 10001==>17 最后的二进制,某一个位有1的,就说明这个位对应的修饰符是存在的。 */ //(4)获取String类的父类,继承是单继承 Class superclass = clazz.getSuperclass(); System.out.println("superclass = " + superclass);//class java.lang.Object //(5)获取String类的接口们,返回数组,因为接口是多实现 Class[] interfaces = clazz.getInterfaces(); System.out.println("父接口们:"); for (Class anInterface : interfaces) { System.out.println(anInterface); } //(6)获取String类的成员 //clazz.getField("属性名"); 获取某一个公共的成员变量 //clazz.getFields(); 获取所有的公共的成员变量 //clazz.getDeclaredField("属性名"); 获取某一个已声明的成员变量 //clazz.getDeclaredFields(); 获取所有已声明的成员变量,包括非公共的,私有的等 Field[] declaredFields = clazz.getDeclaredFields(); System.out.println("String类所有的成员变量:"); for (Field declaredField : declaredFields) { System.out.println(declaredField); } //获取String类的构造器们 //clazz.getConstructor(构造器的形参类型列表) 获取一个公共的构造器 //clazz.getConstructors(); 获取所有公共的构造器 //clazz.getDeclaredConstructor(构造器的形参类型列表) 获取一个已声明的构造器 //clazz.getDeclaredConstructors(); //获取所有已声明的构造器 Constructor[] declaredConstructors = clazz.getDeclaredConstructors(); System.out.println("String类的构造器有:"); for (Constructor declaredConstructor : declaredConstructors) { System.out.println(declaredConstructor); } //获取String类的方法们 //clazz.getMethod(方法名,方法的形参类型列表):获取某个公共的方法 //clazz.getDeclaredMethod(方法名,方法的形参类型列表):获取某个已声明的方法 //clazz.getMethods() 获取所有公共的方法 //clazz.getDeclaredMethods() 获取所有已声明的方法 Method[] declaredMethods = clazz.getDeclaredMethods(); System.out.println("String类的所有方法:"); for (Method declaredMethod : declaredMethods) { System.out.println(declaredMethod); } //获取ArrayList的内部类 Class c2 = ArrayList.class; Class[] declaredClasses = c2.getDeclaredClasses(); System.out.println("ArrayList的内部类:"); for (Class innerClass : declaredClasses) { System.out.println(innerClass); } }
2、创建任意类型的对象
方案一:
先获取这个类的Class对象
调用Class对象的newInstance()方法来创建实例对象,要求这个类必须有无参的公共构造器。
javaClass<?> clazz = Class.forName("com.atguigu.ext.demo.AtGuiguClass"); Object obj = clazz.newInstance();
方案二:
先获取这个类的Class对象
先获取有参构造器对象
调用构造器对象的newInstance(...)方法来创建实例对象。如果构造器是非公共的,那么需要调用构造器对象的setAccessible(true),跳过权限修饰符。
javaClass<?> clazz = Class.forName("com.atguigu.ext.demo.AtGuiguDemo"); //通过构造器的形参类型列表来确定具体是哪个构造器 Constructor<?> c1 = clazz.getDeclaredConstructor(String.class, int.class); //跳过权限修饰符检查 c1.setAccessible(true); Object obj = c1.newInstance("尚硅谷", 666);
注意:
- 基本数据类型和void,抽象类,接口等无法创建对象。
- 为保证许多框架可以自动创建的对象,需要保留类公共的无参构造。
3、动态的操作任意对象的任意属性
- 步骤:
- 获取类的Class对象
- 通过class对象获取实例对象
- 先获取id属性的Field对象
- setAccessible(true),设置跳过权限修饰符限制,如果属性的权限修饰符允许,可省略。
- 操作id属性的值
- 通过id属性对应的Field对象.get(实例对象)获取id属性的值
- 通过id属性对应的Field对象.set(实例对象,值)设置id属性的值
public void test01()throws Exception{
//通过反射创建Student类的对象,并且通过反射给Student对象的id和name属性赋值,获取它们的值
//(1)获取类的Class对象
Class clazz = Class.forName("com.atguigu.bean.Student");
//(2)通过反射创建Student类的对象
Object stu = clazz.newInstance();//学生对象 stu是Student对象
//(3)先获取id属性的Field对象
Field idField = clazz.getDeclaredField("id");
//(4)因为id属性是私有化的,所以要加一步
idField.setAccessible(true);
//(5)获取id属性的值
Object idValue = idField.get(stu);//访问stu对象的id属性值 等价于 stu.id
System.out.println(idValue);
//(6)设置id属性的值
idField.set(stu, 2);//给stu对象的id属性赋值 等价于 stu.id = 2;
//再次访问id属性的值
idValue = idField.get(stu);//访问stu对象的id属性值 等价于 stu.id
System.out.println(idValue);
}4、在运行时动态的调用任意类的任意方法
- 步骤:
- 获取Class对象
- 创建这个类的实例对象
- 先获取你要调用的方法的Method对象
- 调用方法:通过Method对象.invoke(实例对象,实参)
public void test01()throws Exception{
//(1)获取Class对象
Class clazz = Class.forName("com.atguigu.ext.demo.AtGuiguClass");
//(2)创建这个类的实例对象
Object obj = clazz.newInstance();//obj是 AtGuiguClass类的对象
//(3)先获取你要调用的方法的Method对象,类名+形参列表
Method doubleNumMethod = clazz.getDeclaredMethod("doubleNum", int.class);//int.class表示 doubleNum有
//(4)调用这个方法
Object returnValue = doubleNumMethod.invoke(obj,5);//通过obj取调用这个方法
System.out.println("returnValue = " + returnValue);
}5、操作静态方法和静态成员
反射操作静态方法的步骤:
- 获取Class对象
- 先获取你要调用的方法的Method对象
- 通过Method对象.invoke(实例对象,实参)
反射操作静态变量的步骤
- 获取Class对象
- 获取要操作/访问的静态变量的Field对象
- setAccessible(true); (如果修饰符允许,可以省略这步)
- (可以访问静态变量的值,或者给静态变量赋值
- 某个静态变量对应的Field对象.get(null)就是获取静态变量的值
- 某个静态变量对应的Field对象.set(null,值)就是设置静态变量的值
注解
本质:注解本质上就是一个接口,该接口默认继承Annotation接口:public interface MyAnno extends java.lang.annotation.Annotation
属性:接口中的抽象方法
属性的返回值类型有下列取值
- 基本数据类型
- String
- 枚举
- 注解
- 以上类型的数组
定义了属性,在使用时需要给属性赋值
- 如果定义属性时,使用default关键字给属性默认初始化值,则使用注解时,可以不进行属性的赋值。
- 如果只有一个属性需要赋值,并且属性的名称是value,则value可以省略,直接定义值即可。
- 数组赋值时,值使用{}包裹。如果数组中只有一个值,则{}可以省略
java//申明注解 @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.FIELD) public @interface Person { String name(); String sex() default ""; int age() default 18; } //等同于 public interface Person extends Annotation{ String name(); default String sex(){ return ""; } default int age(){ return 18; } }
常见注解:
@Override
- 用于检测被标记的方法是否为有效的重写方法,如果不是,则报编译错误!
@Deprecated
- 标记某个方法、类等已过时。不建议程序员继续使用,如果使用有问题,或有风险。【因为之前存在程序使用方法和类,若直接删除,则这些程序将无法运行,所以打上已过时的标记,建议后面的程序员不再使用】
@SuppressWarnings
标记某个方法、类等,作用是给编译器一条指令,告诉它对被批注的代码元素内部的某些警告保持静默。
java//对unchecked类型警告保持静默 @SuppressWarnings("unchecked") public void addItems(String item){ @SuppressWarnings("rawtypes") List items = new ArrayList(); items.add(item); } //对unchecked和rawtypes类型警告保持静默 @SuppressWarnings(value={"unchecked", "rawtypes"}) public void addItems(String item){ List items = new ArrayList(); items.add(item); } //对所有警告保持静默 @SuppressWarnings("all") public void addItems(String item){ List items = new ArrayList(); items.add(item); }
元注解
给注解加注释的注解
@Target:用来解释/注释某个注解可以用在哪里,可以用注解的位置一共有10个。储存在ElementType是一个枚举类型,每一个常量对象,代表一个注解可以使用的位置。
- TYPE:类、接口(包括注解接口)、枚举或记录声明。
- FIELD:字段声明(包括枚举常量)。
- METHOD:方法声明。
- PARAMETER:形式参数声明。
- CONSTRUCTOR:构造器声明。
- LOCAL_VARIABLE:局部变量声明。
- ANNOTATION_TYPE:注解接口声明(以前被称为注解类型)。
- PACKAGE:包声明。
- TYPE_PARAMETER:类型参数声明。
- TYPE_USE:类型的使用。
- MODULE:模块声明。
- RECORD_COMPONENT:记录组件。
@Retention:用来解释/注释某个注解的生命周期 SOURCE:源代码 CLASS:字节码 RUNTIME:运行时,内存中,只有RUNTIME阶段才能被反射读取.
@Documented:用来解释/注释某个注解是不是可以被javadoc工具读取到API文档中。
@Inherited:某个类上的注解是不是可以被其子类继承
自定义注解
//声明
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Check {
}
//使用
public class Calculator {
//加法
@Check
public void add(){
System.out.println("1 + 0 =" + 1);
}
//减法
@Check
public void sub(){
System.out.println("1 - 0 =" +1);
}
}
//检查注解
public static void main(String[] args) throws IOException {
//1.创建计算器对象
Calculator c = new Calculator();
//2.获取字节码文件对象
Class cls = c.getClass();
//3.获取所有方法
Method[] methods = cls.getMethods();
int number = 0;//出现异常的次数
BufferedWriter bw = new BufferedWriter(new FileWriter("bug.txt"));
for (Method method : methods) {
//4.判断方法上是否有Check注解
if(method.isAnnotationPresent(Check.class)){
//5.有,执行
try {
method.invoke(c);
} catch (Exception e) {
//6.捕获异常
//记录到文件中
number ++;
bw.write(method.getName()+ " 方法出异常了");
bw.newLine();
bw.write("异常的名称:" + e.getCause().getClass().getSimpleName());
bw.newLine();
bw.write("异常的原因:"+e.getCause().getMessage());
bw.newLine();
bw.write("--------------------------");
bw.newLine();
}
}
}
bw.write("本次测试一共出现 "+number+" 次异常");
bw.flush();
bw.close();
}注解处理
不基于spring容器实现
已知class,直接反射
//申明注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface Person {
String name() default "";
String sex() default "";
int age() default 18;
}
//定义一个普通实体类
public class Human {
// 姓名
private String name;
// 性别
private String sex;
// 年龄
private Integer age;
@Override
public String toString() {
return "Human{" +
"name='" + name + '\'' +
", sex='" + sex + '\'' +
", age=" + age +
'}';
}
}
//注解实现及测试
public class Example01 {
@Person(name="张三", sex = "男", age = 23)
private Human human1;
@Person(name="小红", sex = "女", age = 21)
private Human human2;
public static void main(String[] args) throws Exception {
Example01 example01 = new Example01();
System.out.println(example01.human1);
System.out.println(example01.human2);
example01.initField();
System.out.println(example01.human1);
System.out.println(example01.human2);
}
// 注解实现
public void initField() throws Exception {
Class clazz = this.getClass();
Field[] fields = clazz.getDeclaredFields();
for(Field field : fields){
Person person = field.getDeclaredAnnotation(Person.class);
if(person != null) {
//field.getType()得到的是字段的类对象
Human human = ((Class<Human>) field.getType()).getDeclaredConstructor().newInstance();
human.setSex(person.sex());
human.setName(person.name());
human.setAge(person.age());
//将human赋值给this对象的filed对应字段
field.set(this, human);
}
}
}
}类扫描,然后反射
借助spring-core
//声明注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Cat {
String name() default "";
}
//添加注解
@Cat(name="tom")
public class Tomcat {
private String name;
public Tomcat(){
}
public Tomcat(String name) {
this.name = name;
}
@Override
public String toString() {
return "Tomcat{" +
"name='" + name + '\'' +
'}';
}
}
//实现注解并测试
public class SpringExample {
public static void main(String[] args) throws Exception {
//获取扫描类路径下的组件,传入true会使用默认的过滤去,只扫描@Component、@Repository、@Service、@Controller、@RestController、@ControllerAdvice等注解
ClassPathScanningCandidateComponentProvider classPathScanningCandidateComponentProvider = new ClassPathScanningCandidateComponentProvider(false);
classPathScanningCandidateComponentProvider.addIncludeFilter(new AnnotationTypeFilter(Cat.class));
// 扫描指定包下的候选组件(扫描类上的注解),并返回一组BeanDefinition对象
Set<BeanDefinition> beanDefinitions = classPathScanningCandidateComponentProvider.findCandidateComponents("com.dblones.java.annotation.example02");
for(BeanDefinition beanDefinition : beanDefinitions){
//得到全类名
String beanClassName = beanDefinition.getBeanClassName();
//获取类对象
Class clazz = Class.forName(beanClassName);
//反射得到注解
Cat cat = (Cat) clazz.getDeclaredAnnotation(Cat.class);
//得到注解中的值
String name = cat.name();
Object object = clazz.getDeclaredConstructor(String.class).newInstance(name);
System.out.println(object);
}
}
}借助reflections反射工具包
//声明注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Cat {
String name() default "";
}
//添加注解
@Cat(name="tom")
public class Tomcat {
private String name;
public Tomcat(){
}
public Tomcat(String name) {
this.name = name;
}
@Override
public String toString() {
return "Tomcat{" +
"name='" + name + '\'' +
'}';
}
}
//使用注解及测试
public class ReflectionsExample {
public static void main(String[] args) throws Exception {
// 创建一个Reflections对象,用于扫描类路径下的组件
// "com.dblones.java.annotation.example03" 是要扫描的包路径
// new TypeAnnotationsScanner() 是用于扫描类、接口或枚举上的注解
// new SubTypesScanner() 是用于扫描类的子类
// new FieldAnnotationsScanner() 是用于扫描字段上的注解
Reflections reflections = new Reflections("com.dblones.java.annotation.example03", new TypeAnnotationsScanner(), new SubTypesScanner(), new FieldAnnotationsScanner());
// 获取所有带有Cat注解的类(如果需要其他地方上的注解,需要使用对应的其他方法)
Set<Class<?>> cats = reflections.getTypesAnnotatedWith(Cat.class);
// 遍历所有带有Cat注解的类
for(Class<?> clazz : cats){
// 获取类上的Cat注解
Cat cat = (Cat) clazz.getDeclaredAnnotation(Cat.class);
// 获取Cat注解的name属性值
String name = cat.name();
// 通过反射创建一个新的对象,构造函数的参数是Cat注解的name属性值
Object object = clazz.getDeclaredConstructor(String.class).newInstance(name);
// 打印新创建的对象
System.out.println(object);
}
}
}基于Spring容器实现
如果存在多个自定义注解的时候,获取到添加了注解的目标,是整个实现自定义注解过程中,比较频繁发生的事情,如果每个注解的实现都去扫描包,很显然,扫描包这个动作重复了,而且效率低下,那有没有什么办法,可以减少扫描或者我们自己根本不需要扫描呢?一种方式是把扫描抽离出来做为公共初始化方法,另外一种方式就是如果我们的程序里面使用了spring容器,那么我们可以借助spring容器,借助spring的扫描,我们可以不需要自己扫描。

核心流程:
1.BeanFactory实例化
2.注册Bean定义
3.实例化普通单例Bean
4.依赖注入属性
5.普通Bean初始化
6.所有普通单例Bean实例化完成


1.BeanFactory实例化
2.注册Bean定义
3.注册后置处理,实现BeanDefinitionRegistryPostProcessor.postProcessBeanDefinitionRegistry
4.BeanFactory后置处理,实现BeanFactoryPostProcessor.postProcessBeanFactory
5.实例化Bean前置处理,实现InstantiationAwareBeanPostProcessor.postProcessBeforeInstantiation
6.实例化普通单例Bean
7.依赖注入属性
8.实例化Bean后置处理,实现InstantiationAwareBeanPostProcessor.postProcessAfterInstantiation
9.依赖注入后置处理,实现InstantiationAwareBeanPostProcessor.postProcessPropertyValues
10.Bean初始化前置处理,实现BeanPostProcessor.postProcessBeforeInitialization
11.普通Bean初始化( @PostConstruct注解方法初始化, InitializingBean接口afterPropertiesSet方法初始化, @Bean注解init-method属性方法初始化)
12.Bean初始化后置处理,实现BeanPostProcessor.postProcessBeforeInitialization
13.所有普通单例Bean实例化完成
14.所有普通单例bean实例化后置处理,实现SmartInitializingSingleton.afterSingletonsInstantiated基于BeanDefinitionRegistryPostProcessor接口
这个接口一般用来注册bean定义,当然也可以修改bean定义信息,触发时机在BeanFactory实例化后,注册了一些系统内置的bean定义之后。ConfigurationClassPostProcessor就是基于BeanDefinitionRegistryPostProcessor接口实现@Configuration、@Bean、@Import、@ImportResource、@ComponentScan、@PropertySource、@Conditional等注解的。
public interface BeanDefinitionRegistryPostProcessor extends BeanFactoryPostProcessor {
void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException;
}
//声明注解
@Target({ElementType.TYPE}) //声明应用在类上
@Retention(RetentionPolicy.RUNTIME) //运行期生效
@Documented
public @interface Registry {
String value() default "";
}
//添加注解
@Registry
public class Dog {
}
//注解实现
@Component
public class AnnotationBeanDefinitionRegistryPostProcessor implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
ClassPathScanningCandidateComponentProvider classPathScanningCandidateComponentProvider = new ClassPathScanningCandidateComponentProvider(false);
classPathScanningCandidateComponentProvider.addIncludeFilter(new AnnotationTypeFilter(Registry.class));
Set<BeanDefinition> beanDefinitions = classPathScanningCandidateComponentProvider.findCandidateComponents("com.dblones.java.annotation.example05");
for(BeanDefinition beanDefinition : beanDefinitions){
//注册到Spring中
registry.registerBeanDefinition(beanDefinition.getBeanClassName(), beanDefinition);
}
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
}
}
//测试验证
@Configuration
@ComponentScan("com.dblones.java.annotation.example05")
public class Example01 {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(Example01.class);
Dog dog = context.getBean(Dog.class);
System.out.println(dog);
}
}BeanFactoryPostProcessor
这个接口一般修改bean定义信息,触发时机在BeanFactory实例化后,注册了bean定义之后,BeanDefinitionRegistryPostProcessor接口的postProcessBeanDefinitionRegistry方法之后。@Configuration注解的代理实现就是在这个阶段通过ConfigurationClassPostProcessor类实现的。
public interface BeanFactoryPostProcessor {
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException;
}InstantiationAwareBeanPostProcessor
是BeanPostProcessor的子接口,通过接口字面意思翻译该接口的作用是感知Bean实例化的处理器。就是全面干预Bean实例化过程,包括Bean实例化前后,设置属性,初始化前后。
public interface InstantiationAwareBeanPostProcessor extends BeanPostProcessor {
Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException;
boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException;
PropertyValues postProcessPropertyValues(
PropertyValues pvs, PropertyDescriptor[] pds, Object bean, String beanName) throws BeansException;
}BeanPostProcessor
对实例Bean进行后置处理, Bean初始化方法调用前被调用或Bean初始化方法调用后被调用。我们常见的注解@@PostConstruct、@PreDestroy就是借助BeanPostProcessor 接口实现的,具体是通过InitDestroyAnnotationBeanPostProcessor类实现的。
public interface BeanPostProcessor {
//bean初始化方法调用前被调用
Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException;
//bean初始化方法调用后被调用
Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException;
}
//声明注解
@Target({ElementType.FIELD}) //声明应用在属性上
@Retention(RetentionPolicy.RUNTIME) //运行期生效
@Documented
public @interface Boy {
String name() default "";
}
//添加注解
@Service
public class Hello {
@Boy(name = "小明")
String name = "world";
public void say() {
System.out.println("hello, " + name);
}
}
//注解实现
@Component //注意:Bean后置处理器本身也是一个Bean
public class BoyAnnotationBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
/**
* 利用Java反射机制注入属性
*/
Field[] declaredFields = bean.getClass().getDeclaredFields();
for (Field declaredField : declaredFields) {
Boy annotation = declaredField.getAnnotation(Boy.class);
if (null == annotation) {
continue;
}
declaredField.setAccessible(true);
try {
declaredField.set(bean, annotation.name());
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
}
//测试验证
@Configuration
@ComponentScan("com.dblones.java.annotation.example04")
public class Example {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(Example.class);
Hello hello = context.getBean(Hello.class);
hello.say();
}
}SmartInitializingSingleton
对全体实例bean进行后置处理。Spring Cloud中的@LoadBalanced就是借助SmartInitializingSingleton接口实现的。
public interface SmartInitializingSingleton {
void afterSingletonsInstantiated();
}注解扩展
//注解1
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface MyComponent {
String name() default "";
}
//注解二,包含了注解1
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@MyComponent
public @interface MyService {
@AliasFor(annotation = MyComponent.class, attribute = "name")
String name() default "";
}
//在类中使用注解二
@MyService(name = "userService")
public class UserService {
}
//通过循环的方式,判断某一个类上是否有某个注解(UserService上不存在MyComponent注解,但是存在MyService注解,就会去找MyService注解是否被MyComponent注解标注)
private static boolean hasAnnoByNoRecursion(Class<?> classz,Class<? extends Annotation> annotationClass){
LinkedList<Class<?>> classQueue = new LinkedList<>();
classQueue.add(classz);
while (!classQueue.isEmpty()) {
Class<?> currentClass = classQueue.poll();
Annotation[] annotations = currentClass.getAnnotations();
for (Annotation annotation : annotations) {
if (isJavaAnnotation(annotation.annotationType())) {
if (annotation.annotationType() == annotationClass){
return true;
}else{
classQueue.add(annotation.annotationType());
}
}
}
}
return false;
}
//使用递归的方式,判断某一个类上是否有某个注解
private static boolean hasAnnoByRecursion(Class<?> classz,Class<? extends Annotation> annotationClass){
Annotation[] annotations = classz.getAnnotations();
for (Annotation annotation : annotations) {
if (isJavaAnnotation(annotation.annotationType())){
if (annotation.annotationType() == annotationClass){
return true;
}else if(hasAnnoByRecursion(annotation.annotationType(),annotationClass)){
return true;
}
}
}
return false;
}
//会查找元注解,不会合并属性
//使用Spring的方式获取注解(classz类中是否存在MyComponent.class)
//AnnotationUtils.findAnnotation方法在查找注解时,会考虑所查找的注解是否作为元注解存在。也就是说,如果MyComponent注解标注在另一个注解(例如MyService)上,而那个注解(MyService)标注在classz(例如UserService类)上,那么AnnotationUtils.findAnnotation(classz, MyComponent.class)会找到MyComponent注解。
MyComponent annotation = AnnotationUtils.findAnnotation(classz, MyComponent.class);
//会查找元注解,会合并属性
//也就是说,如果MyComponent注解标注在另一个注解上,并且那个注解有一些属性值,那么AnnotatedElementUtils.getMergedAnnotation(classz, MyComponent.class)会返回一个合并了这些属性值的MyComponent注解。即使用@AliasFor标注
MyComponent annotation = AnnotatedElementUtils.getMergedAnnotation(classz, MyComponent.class);集合与迭代器
概述
只能装对象,不能装基本数据的值。当把基本数据类型的值放到集合中时,会自动装箱为对象。
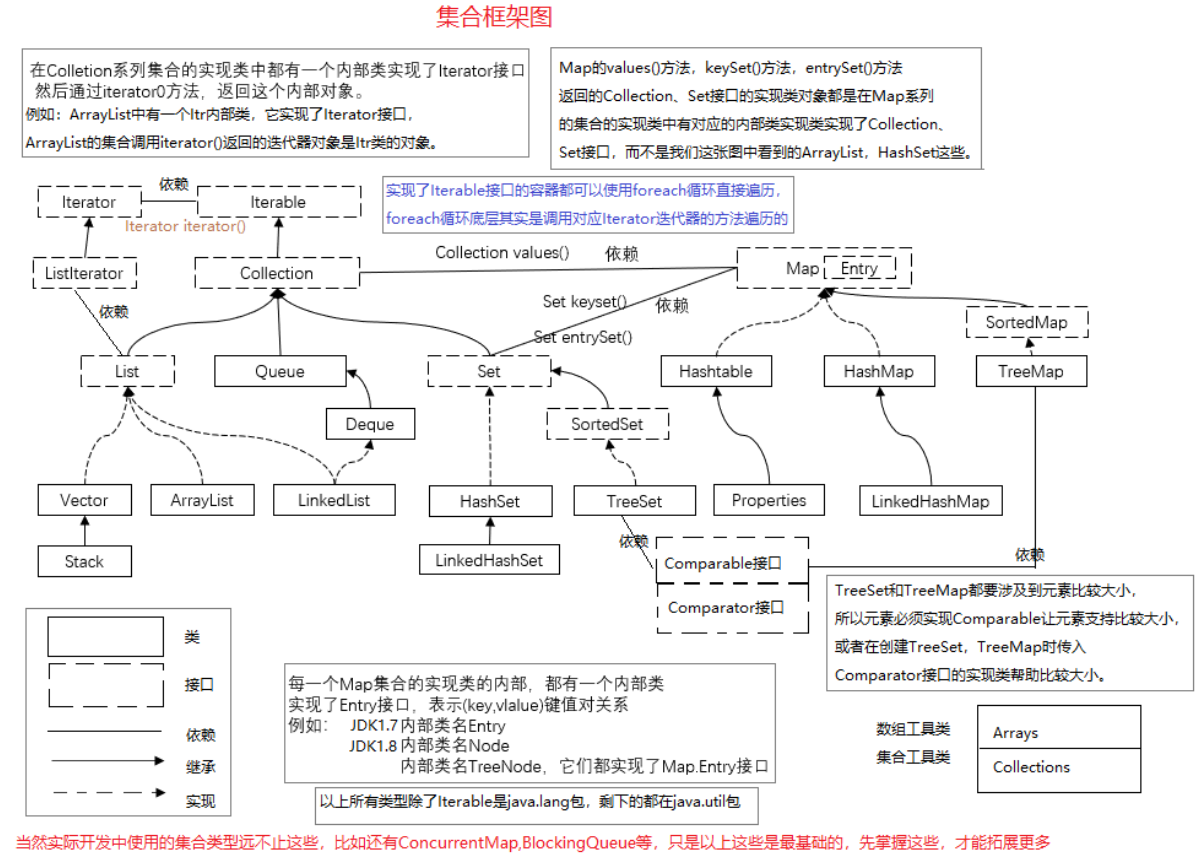
Sequenced表示元素在集合中的位置是有序的,可以通过索引或者迭代器来访问。
Sort表示集合是可以排序的(在Set和map集合中)
Navigable系列的集合是一种扩展了Sorted系列集合,可以获取集合中小于、小于等于、大于等于、大于给定元素的元素
Collection集合系列
Collection接口是Collection系列集合的根接口,将将集合划分为三类:List集合,Set集合、Queue集合。
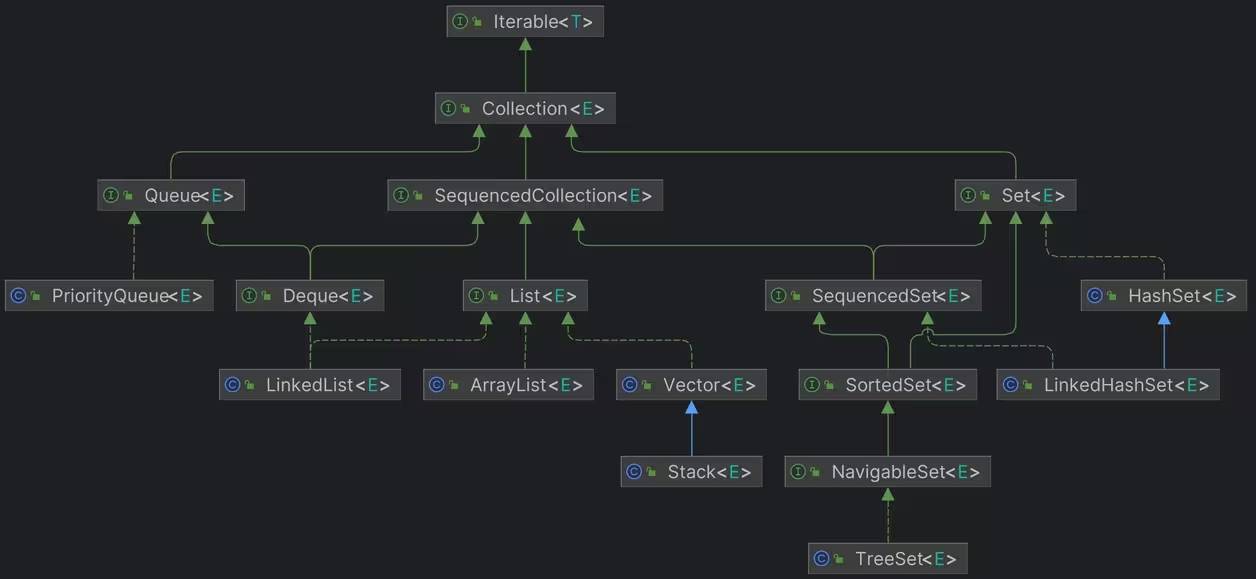
Collection接口的方法:注意,这些方法会在源集合上修改,且返回值为Boolean
boolean add(Object obj):添加元素对象到当前集合中
boolean addAll(Collection other):添加other集合中的所有元素对象到当前集合中
boolean remove(Object obj) :从当前集合中删除第一个找到的与obj对象equals返回true的元素。
boolean removeAll(Collection coll):从当前集合中删除所有与coll集合中相同的元素
boolean removeIf(Predicate filter) :删除满足给定条件的此集合的所有元素。 <a href="#Predicate">关于Predicate </a>
java传入匿名对象Predicate,并重写其Test方法 s2.removeIf(new Predicate<String>(){ @Override public boolean test(String s) { return s.contains("hello"); } });boolean retainAll(Collection coll):保留两个集合中的交集
clear():清空集合
boolean isEmpty():判断当前集合是否为空集合。
boolean contains(Object obj):判断当前集合中是否存在一个与obj对象相等的元素
boolean containsAll(Collection c):判断c集合中的元素是否在当前集合中都存在。即c集合是否是当前集合的“子集”。
int size():获取当前集合中实际存储的元素个数
Object[] toArray():返回包含当前集合中所有元素的数组
java//在参数中传入一个空的数组类型,可以指定返回值的结果,不指定默认object Integer[] array =arrayList.toArray(new Integer[0]);//是创建一个新的Integer数组,其长度为0 Integer[] array =arrayList.toArray(new Integer[]{});//创建一个新的Integer数组并初始化它,但是因为在大括号中没有给出任何元素,所以这个数组的长度也是0。 //调用generator.apply(0)来创建一个长度为0的新数组,然后将这个新数组传递给toArray(T[] a)方法。toArray(T[] a)方法会检查这个数组是否足够大来存储集合中的所有元素。如果数组够大,就直接将元素存入数组并返回;如果数组不够大,就会创建一个新的、足够大的数组来存储元素并返回。 default <T> T[] toArray(IntFunction<T[]> generator) { return toArray(generator.apply(0)); } //传入参数类型为IntFunction<T[]> generator,指定返回值的类型 String[] array = collection.toArray(String[]::new);boolean equals(Object o):判断传入参数与调用equals的对象是否相等
1. 指定的对象也是一个集合。 2. 指定的集合和当前集合有相同的大小。 3. 对于当前集合中的每一个元素,指定的集合中也有一个相等的元素。 需要注意的是,`equals` 方法对于两个集合的元素顺序可能是敏感的。例如,`List` 接口的 `equals` 方法就要求两个列表的元素顺序相同,而 `Set` 接口的 `equals` 方法则不要求元素顺序相同。int hashCode():根据集合中的所有元素的哈希码计算集合的哈希码。
Iterator<E> iterator():返回一个集合的迭代器对象 <a href="#Iterator">关于Iterator</a>
default Stream<E> stream():返回一个流对象,这个
Stream的元素是这个集合的元素。default Stream<E> parallelStream():返回一个可能并行的
Stream,这个Stream的元素是这个集合的元素。并行数由Java的ForkJoinPool.commonPool()决定的。这个值默认等于你的机器的处理器数量,减去一个。内部也是通过spliterator() default Stream<E> stream() { return StreamSupport.stream(spliterator(), false); } default Stream<E> parallelStream() { return StreamSupport.stream(spliterator(), true); }default Spliterator<E> spliterator():返回一个 Spliterator 实例,用于遍历和分割原始的 Collection。和Iterator一样,Spliterator也用于遍历数据源中的元素,但它是为了并行执行而设计的。<a href="#Spliterator">关于Spliterator</a>
关于parallelStream和spliterator
如果你需要对集合进行复杂的并行处理,并且希望系统自动管理线程,那么使用parallelStream()会更加方便。如果你需要对集合进行精细的控制,例如自定义分割逻辑,那么使用spliterator()可能会更合适。
集合元素的删除
注意:
不要在foreach遍历过程中删除元素、添加元素。
在Iterator迭代器遍历集合时,不可以用集合的删除、添加方法修改元素个数,可以使用迭代器remove方法添加元素。
报错:ConcurrentModificationException
原理:foreach遍历是迭代器的一个封装。而使用迭代器遍历元素时,若使用集合的删除,修改方法会出现以下问题:
- 1、使用集合的删除之后,后面的元素会填补前面的元素,而迭代器的指针已经后退了,前补的元素将无法访问,出现漏访问【使用迭代器的remove,指针会前移一位】。
- 2、使用集合的增加和删除,都会导致modCount增加,而迭代器中的expectedModCount未发生改变,二者不相等,根据其实现,会抛出异常。
集合中会有一个变量 modCount,迭代器中同样有一个变量Iterator,用来记录集合元素个数变化的次数。
添加一个元素modCount++
删除一个元素modCount++
替换一个元素modCount不变
ArrayList类内部类Itr的部分代码中:
private class Itr implements Iterator<E> {
int cursor; //当前指向的元素
int lastRet = -1; // 当前指向的上一个元素,初始指向-1
//使用Iterator对ArrayList进行遍历时,此时ArrayList集合元素个数变化的次数,记录下来。
int expectedModCount = modCount;
/*用处:
(1)如果在Iterator遍历ArrayList集合过程中,由另一个方法或另一个线程,修改ArrayList集合元素个数。
那么modCount和 expectedModCount不一致,说明有别人或别的方式修改了集合的个数,那么我要警惕会不会有问题。
(2)如果是Iterator自己删除(或者添加等元素),要同时修改modCount和expectedModCount。保证游标不会错乱。
*/
}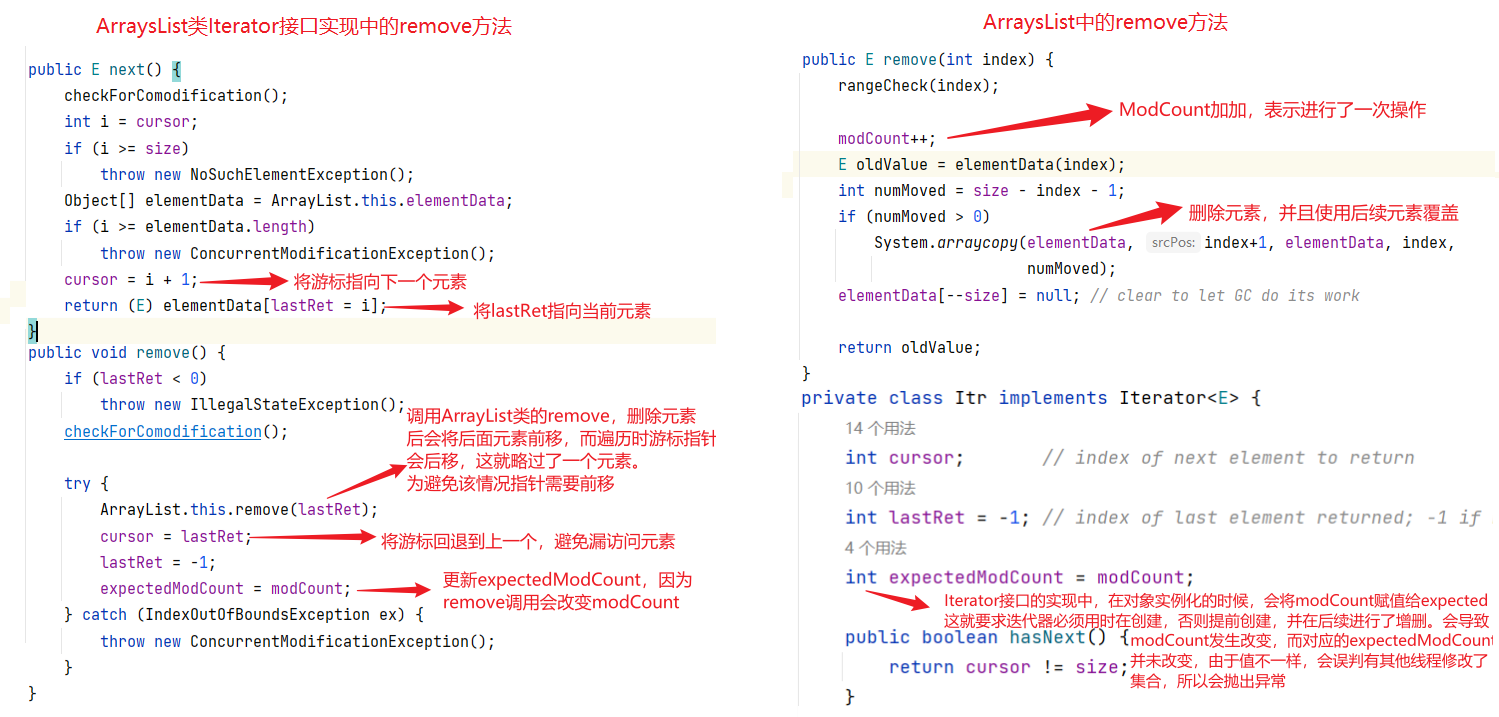
List接口
特点:有序、可以重复、线性、可以根据索引操作元素,需要指定元素类型。
接口新增方法:
void add(int index, E ele):下标为index处插入元素,index处元素后移
E set(int index, E ele):指定位置修改元素
java//只是创建了一个大小为2的底层数组,但是集合的size还是0 List<String> list = new ArrayList<>(2); System.out.println("list大小为:" + list.size()); list.add("12"); System.out.println("list大小为:" + list.size()); list.set(1,"sss");//报错,因为集合的size小于1 //add方法 if (index > size || index < 0) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); //Set方法 if (index >= size) throw new IndexOutOfBoundsException(outOfBoundsMsg(index));boolean addAll(int index, Collection<? extends E> eles):下标为index处向后添加eles中的所有元素
E remove(int index):指定位置删除元素
E get(int index) :获取指定位置的元素
int indexOf(Object o) :查询o对象在当前List集合的位置,如果有重复的多个相同元素,只返回第1个。
int lastIndexOf(Object o) :查询o对象在当前List集合的位置,如果有重复的多个相同元素,只返回最后1个。
List<E> subList(int fromIndex, int toIndex) :截取一段[fromIndex, toIndex)
ListIterator<E> listIterator()
ListIterator<E> listIterator(int index):遍历开始的位置
ListIterator<E>是Iterator<E>的子接口,Iterator功能更强大。有remove、add方法
javaA:可以支持,从任意位置开始从前往后遍历,也支持从后往前遍历。 boolean hasPrevious()//判断前面还有数据吗 E previous()//返回前一个数据 boolean hasNext()//判断当前是否有数据 E next();//返回当前数据 //从开始遍历 istIterator<String> iter = list.listIterator(); while(iter.hasNext()){ System.out.println(iter.nextIndex() + ":" + iter.next()); } //指定返回对应下标,从后面开始遍历。 ListIterator<String> iter = list.listIterator(list.size()); while(iter.hasPrevious()){ System.out.println(iter.previousIndex() + ":" + iter.previous()); } B:在遍历过程中,可以显示下标信息 int nextIndex();//返回随后调用 next()返回的元素的索引。 int previousIndex()//返回由后续调用 previous()返回的元素的索引 C:还可以在遍历的过程中添加、修改和删除元素 void add(E e)//在next后增加,previous前面增加 void set(E e)//修改当前next、previous对应的元素 void remove()//删除当前next,previous对应的元素 //判断是否相等,并在后面添加,若是要在前面添加,则需要使用hasPrevious while(iterator.hasNext()){ String str = iterator.next(); if(str.equals("java")){ iterator.add("chai"); } }
default void sort(Comparator<? super E> c):对集合元素进行排序,先转化为数组,调用Arrays排序,在转回集合。
java@SuppressWarnings({"unchecked", "rawtypes"}) default void sort(Comparator<? super E> c) { Object[] a = this.toArray(); Arrays.sort(a, (Comparator) c); ListIterator<E> i = this.listIterator(); for (Object e : a) { i.next(); i.set((E) e); } }default List<E> reversed():逆序
default void addFirst(E e):队首添加一个元素
default void addLast(E e):队尾添加一个元素
default E getFirst():得到第一个元素
default E getLast() :得到最后一个元素
default E removeFirst():去除第一个元素
default E removeLast() :去除最后一个元素
default void replaceAll(UnaryOperator<E> operator)
java//将列表中的每个元素替换为通过给定的操作符函数应用于该元素后的结果。 //执行后,列表中的元素将被替换为它们的两倍,即[2, 4, 6, 8, 10]。 List<Integer> list = Arrays.asList(1, 2, 3, 4, 5); list.replaceAll(n -> n * 2);static <E> List<E> of(E... elements):创建一个含传入参数的List子类ImmutableCollections,这个子类集合不可变。如果你尝试进行这些操作,将会抛出UnsupportedOperationException。
java//除了可变参数列表,还存在具体参数的of函数,因为对于小数量的元素,使用具体数量的参数的方法可以避免创建和初始化可变参数数组,从而提高性能。 static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9, E e10)static <E> List<E> copyOf(Collection<? extends E> coll):将传入集合转变为一个不可变集合ImmutableCollections返回
List接口实现类
动态数组:Vector和ArrayList。
1、ArrayList是新版的动态数组,线程不安全,效率高,Vector是旧版的动态数组,线程安全,效率低。
2、动态数组的扩容机制不同,ArrayList扩容为原来的1.5倍,Vector扩容增加为原来的2倍。
3、数组的初始化容量,如果在构建ArrayList与Vector的集合对象时,没有显式指定初始化容量,那么Vector的内部数组的初始容量默认为10,而ArrayList在JDK1.6及之前的版本也是10,JDK1.7之后的版本ArrayList初始化为长度为0的空数组,之后在添加第一个元素时,再创建长度为10的数组。【用的时候,再创建数组,避免浪费。因为很多方法的返回值是ArrayList类型,需要返回一个ArrayList的对象,例如:后期从数据库查询对象的方法,返回值很多就是ArrayList。有可能你要查询的数据不存在,要么返回null,要么返回一个没有元素的ArrayList对象。】
4、Vector因为版本古老,支持Enumeration 迭代器。但是该迭代器不支持快速失败。而Iterator和ListIterator迭代器支持快速失败。如果在迭代器创建后的任意时间从结构上修改了向量(通过迭代器自身的 remove 或 add 方法之外的任何其他方式),则迭代器将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就完全失败,而不是冒着在将来不确定的时间任意发生不确定行为的风险。
ArrayList方法
public ArrayList():构造一个空列表。
public ArrayList(Collection<? extends E> c):构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection 的迭代器返回它们的顺序排列的。
public ArrayList(int initialCapacity):构造一个具有指定初始容量的空列表。
public void trimToSize():此方法用于将ArrayList实例的容量修剪为列表的当前大小。如果ArrayList的实例包含的元素数量小于其内部数组的长度,那么它将创建一个新的数组,其大小与ArrayList的实际元素数量相同,并将原数组的元素复制到新数组中。这样可以减少ArrayList实例的存储空间。
public void ensureCapacity(int minCapacity):此方法用于确保ArrayList实例的容量至少可以容纳指定数量的元素。如果指定的最小容量大于内部数组的长度,那么它将增加内部数组的大小。
public Object clone():创建ArrayList实例的一个浅拷贝。如果对象不支持克隆,那么会抛出CloneNotSupportedException异常。
浅拷贝和深拷贝: 浅拷贝(Shallow Copy):创建一个新对象,然后将当前对象的非静态字段复制到该新对象。如果字段是值类型的,则对该字段执行逐位复制。如果字段是引用类型的,则复制引用但不复制引用的对象。因此,原始对象及其副本引用同一个对象。 深拷贝(Deep Copy):创建一个新对象,然后将当前对象的非静态字段复制到该新对象。如果字段是值类型的,则对该字段执行逐位复制。如果字段是引用类型的,则复制引用和引用的对象。因此,原始对象及其副本不引用同一个对象。
Vector的子类:Stack
- peek()方法:查看栈顶元素,不弹出
- pop()方法:弹出栈
- push(E e)方法:压入栈
- isEmpty()方法:判空
List子类:双链表LinkedList
- 动态数组索引访问的效率非常高。但是非末尾位置的插入和删除效率不高,且添加涉及到扩容问题。链表索引访问的效率不高,但是插入和删除不需要移动元素,只需要修改前后元素的指向关系即可,而且链表的添加不会涉及到扩容问题。
- 链表可以当做栈使用
Queue接口
Queue子接口:Deque
Deque实现类:LinkedList【链表实现】和ArrayDeque【数组实现】
单端队列:
抛出异常 返回特殊值 插入(末尾插入) add(e) offer(e) 弹出首位 remove() poll() 返回首位 element() peek() 双端队列:
<table style="text-align:center"> <tr> <td></td> <th colspan="2">第一个元素(头部)</th> <th colspan="2">最后一个元素(尾部)</th> </tr> <tr> <td></td> <td>失败抛出异常</td> <td>失败返回FALSE</td> <td>失败抛出异常</td> <td>失败返回FALSE</td> </tr> <tr> <th>插入</th> <td>addFirst(e)</td> <td>offerFirst(e)</td> <td>addLast(e)</td> <td>offerLast(e)</td> </tr> <tr> <th>移除</th> <td>removeFirst()</td> <td>pollFirst()</td> <td>removeLast()</td> <td>pollLast()</td> </tr> <tr> <th>检查</th> <td>getFirst()</td> <td>peekFirst()</td> <td>getLast()</td> <td>peekLast()</td> </tr> </table>
Set接口
Set没有扩展新方法,所以用的都是Collection接口的方法。不允许元素重复。
java//创建一个包含指定元素的不可修改的集合。这个集合是不可变的,也就是说,一旦创建,就不能添加或删除元素。 static <E> Set<E> of(E... elements) //创建一个包含指定集合中所有元素的不可修改的集合 static <E> Set<E> copyOf(Collection<? extends E> coll)SortedSet
java//返回迭代器 Comparator<? super E> comparator(); // 返回用于对此集合中的元素进行排序的比较器,如果此集合使用其元素的自然顺序,则返回 null。 Comparator<? super E> comparator(); // 返回一个视图,该视图的元素范围从 fromElement(包含)到 toElement(不包含)。 SortedSet<E> subSet(E fromElement, E toElement); // 返回一个视图,该视图的元素严格小于 toElement。 SortedSet<E> headSet(E toElement); // 返回一个视图,该视图的元素大于或等于 fromElement。 SortedSet<E> tailSet(E fromElement); // 返回当前在此集合中的第一个(最低)元素。 E first(); // 返回当前在此集合中的最后一个(最高)元素。 E last(); // 创建一个在此排序集合中的元素上的 Spliterator。Spliterator 报告 Spliterator.DISTINCT、Spliterator.SORTED 和 Spliterator.ORDERED。 @Override default Spliterator<E> spliterator() { // 在这里实现 } // 抛出 UnsupportedOperationException。由此集合的比较方法引导的遇到顺序决定了元素的位置,因此不支持显式定位。 default void addFirst(E e) { throw new UnsupportedOperationException(); } // 抛出 UnsupportedOperationException。由此集合的比较方法引导的遇到顺序决定了元素的位置,因此不支持显式定位。 default void addLast(E e) { throw new UnsupportedOperationException(); } // 返回此集合中的第一个(最低)元素。 default E getFirst() { return this.first(); } // 返回此集合中的最后一个(最高)元素。 default E getLast() { return this.last(); } // 移除并返回此集合中的第一个(最低)元素。 default E removeFirst() { E e = this.first(); this.remove(e); return e; } // 移除并返回此集合中的最后一个(最高)元素。 default E removeLast() { E e = this.last(); this.remove(e); return e; } // 返回此集合的反向视图。 default SortedSet<E> reversed() { // 在这里实现 }NavigableSet
javapublic interface NavigableSet<E> extends SortedSet<E> { // 返回此集合中严格小于给定元素的最大元素,如果没有这样的元素,则返回 null。 E lower(E e); // 返回此集合中小于或等于给定元素的最大元素,如果没有这样的元素,则返回 null。 E floor(E e); // 返回此集合中大于或等于给定元素的最小元素,如果没有这样的元素,则返回 null。 E ceiling(E e); // 返回此集合中严格大于给定元素的最小元素,如果没有这样的元素,则返回 null。 E higher(E e); // 检索并删除第一个(最低)元素,如果此集合为空,则返回 null。 E pollFirst(); // 检索并删除最后一个(最高)元素,如果此集合为空,则返回 null。 E pollLast(); // 返回此集合中元素的升序迭代器。 Iterator<E> iterator(); // 返回此集合中包含的元素的逆序视图。逆序集合由此集合支持,因此对集合的更改会反映在逆序集合中,反之亦然。 NavigableSet<E> descendingSet(); // 返回此集合中元素的降序迭代器。效果等同于 descendingSet().iterator()。 Iterator<E> descendingIterator(); // 返回此集合的一部分视图,其元素范围从 fromElement 到 toElement。 NavigableSet<E> subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive); // 返回此集合的一部分视图,其元素小于(或等于,如果 inclusive 为 true)toElement。 NavigableSet<E> headSet(E toElement, boolean inclusive); // 返回此集合的一部分视图,其元素大于(或等于,如果 inclusive 为 true)fromElement。 NavigableSet<E> tailSet(E fromElement, boolean inclusive); // 等同于 subSet(fromElement, true, toElement, false)。 SortedSet<E> subSet(E fromElement, E toElement); // 等同于 headSet(toElement, false)。 SortedSet<E> headSet(E toElement); // 等同于 tailSet(fromElement, true)。 SortedSet<E> tailSet(E fromElement); //去除第一个 default E removeFirst() //去除最后一个 default E removeLast() //逆序 default NavigableSet<E> reversed() }Hashset实现类
无序,重复元素不添加,内部由HashMap支持,底层物理实现是一个Hash表。
HashSet 集合判断两个元素相等的标准:两个对象通过 hashCode() 方法比较相等,并且两个对象的 equals() 方法返回值也相等。因此,存储到HashSet的元素要重写hashCode和equals方法。
HashSet(Collection<? extends E> c):构造一个新的集合,包含指定集合中的元素。
HashMap实例具有默认的初始容量(16)和加载因子(0.75)。 HashSet的加载因子是一个浮点数,它决定了当HashSet的元素数量达到其内部HashMap的容量的多少百分比时,HashSet会自动增加其内部HashMap的容量(即进行rehash操作)。默认的加载因子是0.75。 加载因子的选择是空间和时间效率之间的折衷。较高的值会减少空间开销,但会增加查找成本(在HashSet中包含的元素越多,查找成本就越高,因为HashMap的数据是通过散列函数散列到桶中的,每个桶可能包含多个元素)。较低的加载因子会增加空间开销,但会减少查找成本。HashSet(int initialCapacity, float loadFactor):构造一个新的空集合;后备的HashMap实例具有指定的初始容量和指定的加载因子。
HashSet(int initialCapacity):构造一个新的空集合;后备的HashMap实例具有指定的初始容量和默认的加载因子(0.75)。
HashSet(int initialCapacity, float loadFactor, boolean dummy):构造一个新的空链接哈希集。指定初始容量和指定加载因子的LinkedHashMap。
当dummy参数为true时,HashSet会使用LinkedHashMap作为其内部的HashMap实例,而不是普通的HashMap。HashSet.newHashSet(int numElements):创建一个新的、空的HashSet,适用于预期的元素数量。返回的集合使用默认的加载因子0.75,其初始容量通常足够大,以便可以添加预期数量的元素而无需调整集合的大小。
public Object clone() :浅拷贝,返回一个新Set
TreeSet实现类
- 有序,内部由TreeMap支持,底层是基于红黑树实现的!所以不需要加载因子。
- 自然排序: 让待添加的元素类型实现Comparable接口,并重写compareTo方法
- 定制排序: 创建Set对象时,指定Comparator比较器接口,并实现compare方法
- TreeSet():构造一个新的,空的树集,根据元素的自然顺序进行排序。
- TreeSet(Comparator<? super E> comparator):构造一个新的,空的树集,根据给定的比较器进行排序。
- TreeSet(Collection<? extends E> c):构造一个包含指定集合元素的新树集,根据元素的自然顺序进行排序。
- TreeSet(SortedSet<E> s):构造一个与指定有序集相同元素的新树集,使用与指定有序集相同的比较器。
LinkedHashSet实现类
- 有序(按照添加顺序),实际上底层不是按照添加顺序存储的,而是通过一个链表记录它们的添加顺序。
- 在HashSet的基础上,在结点中增加两个属性before和after维护了结点的前后添加顺序。是链表和哈希表组合的一个数据存储结构。LinkedHashSet插入性能略低于 HashSet,但在迭代访问 Set 里的全部元素时有很好的性能。
- LinkedHashSet():构造一个新的空链接哈希集。此构造函数创建的集合按照插入顺序进行迭代。
- LinkedHashSet(Collection<? extends E> c):构造一个新的链接哈希集,其元素是按照它们在指定集合的迭代器返回的顺序添加的。
- LinkedHashSet(int initialCapacity, float loadFactor):构造一个新的空链接哈希集,具有指定的初始容量和加载因子
- LinkedHashSet(int initialCapacity):构造一个新的空链接哈希集,具有指定的初始容量和默认的加载因子(0.75)。
Map集合系列
其元素是表示一组键值对(key,value), key不允许重复,value允许重复,如果key重复了,后面的value会覆盖前面的value
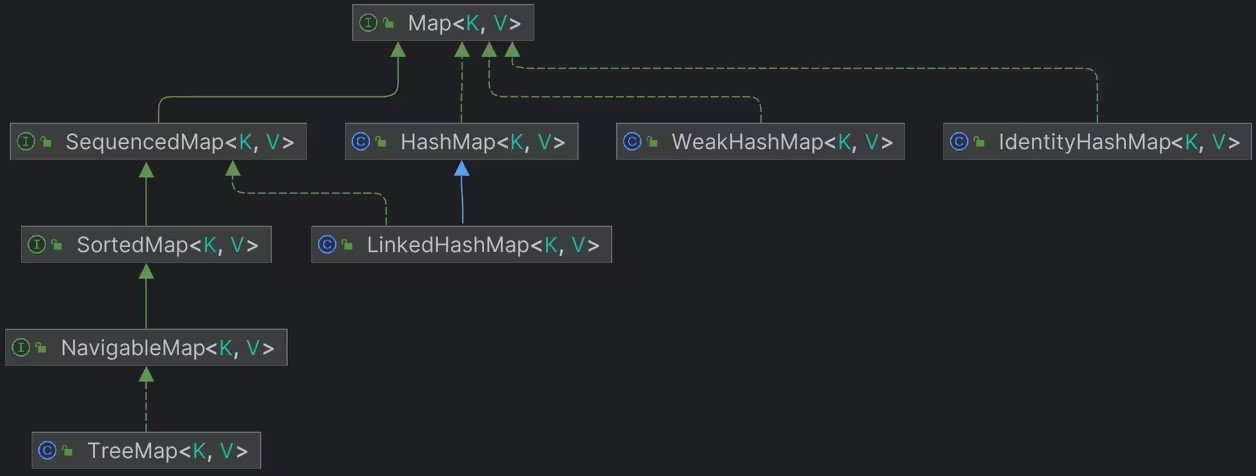
Map接口的方法
V put(K key,V value):若key值不存在,则添加,并返回null;若key值已存在,返回value,并替换为新值。
void putAll(Map<? extends K,? extends V> m):将另一个Map集合中的所有元素放入
void clear():清空Map
V remove(Object key):删除指定key对应元素
V get(Object key):找到key值对应的value
boolean containsKey(Object key):判断是否存在该key值
boolean containsValue(Object value):判断是否存在该value值
boolean isEmpty():判断集合是否为空
int size():获取键值对的数量
Set<K> keySet():获取所有的key,然后遍历所有的key.因为key不可重复,所以用Set
Collection<V> values():获取所有的value,遍历所有的value
public V getOrDefault(Object key, V defaultValue) :尝试在Map中查找给定的键。如果找到了键,并且键关联的值不为null,那么就返回该值。如果没有找到键,或者键关联的值为null,那么就返回传入的默认值。
public V putIfAbsent(K key, V value):键是否已经在 HashMap 中存在。如果键不存在,它将键和给定的值添加到 HashMap 中,并返回 null。如果键已经存在,它不会改变已经存在的键值对,而是返回与该键关联的当前值。
Set<Map.Entry<K,V>> entrySet():遍历所有的 键值对(key,value),Map中所有键值对(key,value)都是Map.Entry接口的实现类
javaSet<Map.Entry<Integer, String>> entries = map.entrySet(); for (Map.Entry<Integer, String> entry : entries) { System.out.println(entry); } //得到所有key值,并通过key值遍历value Map<String, String[]> parameterMap = request.getParameterMap(); Set<String> strings = parameterMap.keySet(); for (String string : strings) { System.out.println("key = " + string); String[] strings1 = parameterMap.get(string); for (String s : strings1) { System.out.println("s = " + s); } } // 使用entrySet()方法获取Map中的键值对集 Set<Map.Entry<String, Integer>> entries = map.entrySet(); // 遍历键值对集 for (Map.Entry<String, Integer> entry : entries) { System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue()); }public boolean replace(K key, V oldValue, V newValue) :如果当前Map中指定的key存在,并且与oldValue相等,则将其值替换为newValue
public V replace(K key, V value) :如果当前Map中指定的key存在,则将其值替换为value,并返回旧值。不存在返回null
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) :如果指定的key不存在,则使用mappingFunction计算其值,并添加到Map中
public V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) :如果指定的key存在,则使用remappingFunction根据旧值计算新值,并替换旧值
public V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction):使用remappingFunction根据key和其对应的值计算新值,并替换旧值,如果计算结果为null,则删除该key
public V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction):如果指定的key不存在,则将其值设置为给定值,如果存在,则使用remappingFunction根据旧值和给定值计算新值,并替换旧值
public void forEach(BiConsumer<? super K, ? super V> action) :对Map中的每个键值对执行给定的action操作
无修改方法,就是重新put,而且只能修改value,不能修改key。如果key被修改了,会导致原来的数据找不到,也删不掉。
SequencedMap
java// 返回此映射中的第一个键值映射,如果映射为空,则返回 null。 default Map.Entry<K,V> firstEntry() {} // 返回此映射中的最后一个键值映射,如果映射为空,则返回 null。 default Map.Entry<K,V> lastEntry() {} // 移除并返回此映射中的第一个键值映射,如果映射为空,则返回 null。 default Map.Entry<K,V> pollFirstEntry() {} // 移除并返回此映射中的最后一个键值映射,如果映射为空,则返回 null。 default Map.Entry<K,V> pollLastEntry() {} //如果给定映射尚未存在,则将其插入到映射中,如果已存在则替换映射的值(可选操作)。此操作正常完成后,给定映射将存在于此映射中,并且将是此映射中的第一个映射。 default V putFirst(K k, V v) {} // 如果给定映射尚未存在,则将其插入到映射中,如果已存在则替换映射的值(可选操作)。此操作正常完成后,给定映射将存在于此映射中,并且将是此映射中的最后一个映射。 default V putLast(K k, V v) {} // 返回此映射的 keySet 的 SequencedSet 视图。 default SequencedSet<K> sequencedKeySet() {} // 返回此映射的 values 集合的 SequencedCollection 视图。 default SequencedCollection<V> sequencedValues() {} // 返回此映射的 entrySet 的 SequencedSet 视图。 default SequencedSet<Map.Entry<K, V>> sequencedEntrySet() {}SortedMap
java// 返回用于在此映射中对键进行排序的比较器,如果此映射使用其键的自然顺序,则返回 null。 Comparator<? super K> comparator() {} // 返回此映射的部分视图,其键的范围从 fromKey(包含)到 toKey(不包含)。 SortedMap<K,V> subMap(K fromKey, K toKey) {} // 返回此映射的部分视图,其键严格小于 toKey。 SortedMap<K,V> headMap(K toKey) {} // 返回此映射的部分视图,其键大于或等于 fromKey。 SortedMap<K,V> tailMap(K fromKey) {} // 返回此映射中当前的第一个(最低)键。 K firstKey() {} // 返回此映射中当前的最后一个(最高)键。 K lastKey() {} // 返回此映射中包含的键的 Set 视图。 Set<K> keySet() {} // 返回此映射中包含的值的 Collection 视图。 Collection<V> values() {} // 返回此映射中包含的映射的 Set 视图。 Set<Map.Entry<K, V>> entrySet() {} // 抛出 UnsupportedOperationException。由此映射的比较方法引导的遇到顺序决定了映射的位置,因此不支持显式定位。 default V putFirst(K k, V v) {} // 抛出 UnsupportedOperationException。由此映射的比较方法引导的遇到顺序决定了映射的位置,因此不支持显式定位。 default V putLast(K k, V v) {} // 返回此映射的反向排序视图。 default SortedMap<K, V> reversed() {}NavigableMap
javaMap.Entry<K,V> lowerEntry(K key); // 返回与此映射中严格小于给定键的最大键关联的键值映射;如果没有这样的键,则返回 null。 K lowerKey(K key); // 返回此映射中严格小于给定键的最大键;如果没有这样的键,则返回 null。 Map.Entry<K,V> floorEntry(K key); // 返回与此映射中小于等于给定键的最大键关联的键值映射;如果没有这样的键,则返回 null。 K floorKey(K key); // 返回此映射中小于等于给定键的最大键;如果没有这样的键,则返回 null。 Map.Entry<K,V> ceilingEntry(K key); // 返回与此映射中大于等于给定键的最小键关联的键值映射;如果没有这样的键,则返回 null。 K ceilingKey(K key); // 返回此映射中大于等于给定键的最小键;如果没有这样的键,则返回 null。 Map.Entry<K,V> higherEntry(K key); // 返回与此映射中严格大于给定键的最小键关联的键值映射;如果没有这样的键,则返回 null。 K higherKey(K key); // 返回此映射中严格大于给定键的最小键;如果没有这样的键,则返回 null。 Map.Entry<K,V> firstEntry(); // 返回此映射中当前最小键关联的键值映射;如果映射为空,则返回 null。 Map.Entry<K,V> lastEntry(); // 返回此映射中当前最大键关联的键值映射;如果映射为空,则返回 null。 Map.Entry<K,V> pollFirstEntry(); // 移除并返回此映射中当前最小键关联的键值映射;如果映射为空,则返回 null。 Map.Entry<K,V> pollLastEntry(); // 移除并返回此映射中当前最大键关联的键值映射;如果映射为空,则返回 null。 NavigableMap<K,V> descendingMap(); // 返回此映射中所包含映射的逆序视图。 NavigableSet<K> navigableKeySet(); // 返回此映射中所包含键的 NavigableSet 视图。 NavigableSet<K> descendingKeySet(); // 返回此映射中所包含键的逆序 NavigableSet 视图。 NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive); // 返回此映射的部分视图,其键的范围从 fromKey 到 toKey。 NavigableMap<K,V> headMap(K toKey, boolean inclusive); // 返回此映射的部分视图,其键小于(或等于,如果 inclusive 为 true)toKey。 NavigableMap<K,V> tailMap(K fromKey, boolean inclusive); // 返回此映射的部分视图,其键大于(或等于,如果 inclusive 为 true)fromKey。 SortedMap<K,V> subMap(K fromKey, K toKey); // 返回此映射的部分视图,其键的范围从 fromKey(包含)到 toKey(不包含)。 SortedMap<K,V> headMap(K toKey); // 返回此映射的部分视图,其键小于 toKey。 SortedMap<K,V> tailMap(K fromKey); // 返回此映射的部分视图,其键大于等于 fromKey。 default NavigableMap<K, V> reversed()// 返回此映射的逆序视图。
Map实现类
HashMap:
- 哈希表,无序,线程不安全的,允许key,value为null
- HashMap():构造一个新的空HashMap。此构造函数创建的HashMap具有默认的初始容量(16)和默认的加载因子(0.75)
- HashMap(int initialCapacity):构造一个新的空HashMap,具有指定的初始容量和默认的加载因子(0.75)。
- HashMap(int initialCapacity, float loadFactor):构造一个新的空HashMap,具有指定的初始容量和加载因子。
- HashMap(Map<? extends K, ? extends V> m):构造一个新的HashMap,其映射关系与指定的Map相同。HashMap实例创建后的容量足以容纳指定Map中的所有映射关系。
- 哈希表,无序,线程不安全的,允许key,value为null
TreeMap:
- 红黑树,可以实现key的排序(自然顺序,也可以指定)
- TreeMap():构造一个新的,空的树映射,根据其键的自然顺序进行排序。
- TreeMap(Comparator<? super K> comparator):构造一个新的,空的树映射,根据给定的比较器进行排序。
- TreeMap(Map<? extends K, ? extends V> m):构造一个新的树映射,其映射关系与指定映射相同。
- TreeMap(SortedMap<K, ? extends V> m):构造一个新的树映射,其映射关系与指定有序映射相同。
- 红黑树,可以实现key的排序(自然顺序,也可以指定)
LinkedHashMap:
- 是HashMap的子类,可以维护添加顺序,通过双重链表维护。
- LinkedHashMap():构造一个新的空链接哈希映射,具有默认的初始容量(16)和加载因子(0.75)。
- LinkedHashMap(int initialCapacity):构造一个新的空链接哈希映射,具有指定的初始容量和默认的加载因子(0.75)。
- LinkedHashMap(int initialCapacity, float loadFactor):构造一个新的空链接哈希映射,具有指定的初始容量和指定的加载因子。
- LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder):构造一个新的空链接哈希映射,具有指定的初始容量、加载因子和排序模式。
- LinkedHashMap(Map<? extends K, ? extends V> m):构造一个新的链接哈希映射,其映射关系与指定映射相同。
- 是HashMap的子类,可以维护添加顺序,通过双重链表维护。
Hashtable:
- 哈希表,无序,早期的Hashtable,线程安全的,不允许key,value为null
- Hashtable():构造一个新的空哈希表。
- Hashtable(int initialCapacity):构造一个新的空哈希表,具有指定的初始容量。
- Hashtable(int initialCapacity, float loadFactor):构造一个新的空哈希表,具有指定的初始容量和指定的加载因子。
- Hashtable(Map<? extends K, ? extends V> t):构造一个新的哈希表,其映射关系与指定映射相同。
- 哈希表,无序,早期的Hashtable,线程安全的,不允许key,value为null
Properties:
Properties类是Hashtable的子类,key和value都是String。可保存在流中或从流中加载。存取数据时,使用setProperty(String key,String value)方法和getProperty(String key)方法。
Properties不仅可以读取.properties类型文件,只要是文本文件,且每一行格式均为 key=value都可以被读取,如TXT文件
java//properties文件不支持中文,使用TXT文件,需要用字符流写入,而且中文注释写入会转化/u………字符 properties.store(new FileWriter("src/main/resources/config.txt"),"store");
load(InputStream inStream) load(Reader reader): 从字符或者字节流输入流中加载属性文件。
javaProperties prop = new Properties(); prop.load(new FileInputStream("config.properties"));loadFromXML(InputStream in): 从XML文档中加载属性。store(OutputStream out, String comments): 将此属性列表(键和元素对)写入此Properties表中,以适当的格式写入输出流。store(Writer writer, String comments): 将此属性列表(键和元素对)写入此Properties表中,以适当的格式写入输出字符流。java// 保存属性到文件,第一个参数为输出流,第二个参数为说明字符串 Properties properties = new Properties(); properties.load(new FileReader(path)); properties.setProperty(key,value); properties.store(new FileWriter(path), null);storeToXML(OutputStream os, String comment): 以简单的XML格式,将此属性列表(键和元素对)写入输出字节流。storeToXML(OutputStream os, String comment, String encoding): 以简单的XML格式,将此属性列表(键和元素对)写入输出字节流。getProperty(String key): 搜索属性列表中指定键的属性。getProperty(String key, String defaultValue): 搜索属性列表中指定键的属性。如果找不到该键,则返回默认值。setProperty(String key, String value): 调用Hashtable的方法put。stringPropertyNames(): 返回一个不可修改的键集,其中键和对应的值是字符串,包括默认属性列表中的键,如果有的话。
这些方法使得
Properties类可以方便地读取和写入属性文件,特别是在处理配置信息时非常有用。
Map和Set关系
所有Set底层都是Map。因为Map和Set有一共共同特点:set不允许元素重复,map的key不允许重复。所以Set其实就是取map的key。底层map的value是一个PRESENT常量对象,因为PRESENT是同一个,所以就多了一个对象而已,但是通过再次封装,产生了新的一组集合。
Collections工具类
作用:Collections 是一个操作 Set、List 和 Map 等集合的工具类。
方法:
public static <T> boolean addAll(Collection<? super T> c,T... elements):将所有指定元素添加到指定 collection 中。
public static <T> int binarySearch(List<? extends Comparable<? super T>> list,T key):在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且必须是可比较大小的,即支持自然排序的。而且集合也事先必须是有序的,否则结果不确定。
java//在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且集合也事先必须是按照c比较器规则进行排序过的,否则结果不确定。 public static <T> int binarySearch(List<? extends T> list,T key,Comparator<? super T> c)public static void swap(List<?> list,int i,int j):将指定 list 集合中的 i 处元素和 j 处元素进行交换
public static int frequency(Collection<?> c,Object o):返回指定集合中指定元素的出现次数
public static <T> void copy(List<? super T> dest,List<? extends T> src):将src中的内容复制到dest中,会覆盖
public static <T> boolean replaceAll(List<T> list,T oldVal,T newVal):使用新值替换 List 对象的所有旧值
public static <T> void fill(List<? super T> list, T obj):将指定列表的所有元素替换为指定的元素。
public static void rotate(List<?> list, int distance) :如果distance为正数,元素将向右(列表的末尾方向)移动;如果distance为负数,元素将向左(列表的开始方向)移动。distance的绝对值可以大于列表的大小,因为实际的移动距离是distance mod list.size()。
public static int indexOfSubList(List<?> source, List<?> target) :在指定的源列表中查找指定目标列表的第一次出现的位置。
public static int lastIndexOfSubList(List<?> source, List<?> target) :在指定的源列表中查找指定目标列表的最后一次出现的位置。
public static boolean disjoint(Collection<?> c1, Collection<?> c2):如果两个指定的 collection 中没有相同的元素,则返回
true。顺序相关:
java//在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,而且支持自然排序【Object的作用是在泛型擦除是发挥作用】 public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll): //在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,按照比较器comp找出最大者 public static <T> T max(Collection<? extends T> coll,Comparator<? super T> comp) //找出最小值 public static <T extends Object & Comparable<? super T>> T min(Collection<? extends T> coll) public static <T> T min(Collection<? extends T> coll, Comparator<? super T> comp) //反转指定列表List中元素的顺序。 public static void reverse(List<?> list) // 返回一个比较器,该比较器强行反转实现了 `Comparable` 接口的对象集合的自然顺序。 public static <T> Comparator<T> reverseOrder() // 返回一个比较器,该比较器通过使用指定比较器的相反顺序来强行反转顺序。 public static <T> Comparator<T> reverseOrder(Comparator<T> cmp) //List 集合元素进行随机排序,类似洗牌 public static void shuffle(List<?> list) //RandomGenerator,Java 9中引入的一个新随机数接口,相对于Random,它提供了一些额外的方法 public static void shuffle(List<?> list, RandomGenerator rnd) public static void shuffle(List<?> list, Random rnd) //根据元素的自然顺序对指定 List 集合元素按升序排序 public static <T extends Comparable<? super T>> void sort(List<T> list) //根据指定的 Comparator 产生的顺序对 List 集合元素进行排序 public static <T> void sort(List<T> list,Comparator<? super T> c)得到不可修改集合:返回的集合将无法修改,调用修改方法将会排除异常
java// 返回一个不可以修改的集合,要求参数是Collection的子类。 public static <T> Collection<T> unmodifiableCollection(Collection<? extends T> c) // 返回一个不可以修改的集合 ,要求参数是SequencedCollection的子类 public static <T> SequencedCollection<T> unmodifiableSequencedCollection(SequencedCollection<? extends T> c) // 返回一个不可修改的List public static <T> List<T> unmodifiableList(List<? extends T> list) // 返回一个不可修改的set public static <T> Set<T> unmodifiableSet(Set<? extends T> s) // 返回一个不可以修改的Set集合 ,要求参数是SequencedSet的子类。 public static <T> SequencedSet<T> unmodifiableSequencedSet(SequencedSet<? extends T> s) // 返回指定有序集合的不可修改视图。 public static <T> SortedSet<T> unmodifiableSortedSet(SortedSet<T> s) // 返回指定可导航集合的不可修改视图 public static <T> NavigableSet<T> unmodifiableNavigableSet(NavigableSet<T> s) // 返回一个不可修改的Map public static <K,V> Map<K,V> unmodifiableMap(Map<? extends K, ? extends V> m) // 返回一个不可修改的SequencedMap public static <K,V> SequencedMap<K,V> unmodifiableSequencedMap(SequencedMap<? extends K, ? extends V> m) // 返回一个不可修改的SortedMap public static <K,V> SortedMap<K,V> unmodifiableSortedMap(SortedMap<K, ? extends V> m) // 返回一个不可修改的NavigableMap public static <K,V> NavigableMap<K,V> unmodifiableNavigableMap(NavigableMap<K, ? extends V> m)多线程集合:用来创建多线程下的安全集合,其内部方法添加了synchronized
java// 公共静态方法,返回由指定集合支持的同步(线程安全)集合 public static <T> Collection<T> synchronizedCollection(Collection<T> c) // 公共静态方法,返回由指定集合支持的同步(线程安全)集合 public static <T> Set<T> synchronizedSet(Set<T> s) // 公共静态方法,返回由指定排序集支持的同步(线程安全)排序集 public static <T> SortedSet<T> synchronizedSortedSet(SortedSet<T> s) // 公共静态方法,返回由指定导航集支持的同步(线程安全)导航集 public static <T> NavigableSet<T> synchronizedNavigableSet(NavigableSet<T> s) // 公共静态方法,返回由指定列表支持的同步(线程安全)列表 public static <T> List<T> synchronizedList(List<T> list) // 公共静态方法,返回由指定映射支持的同步(线程安全)映射 public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) // 公共静态方法,返回由指定排序映射支持的同步(线程安全)排序映射 public static <K,V> SortedMap<K,V> synchronizedSortedMap(SortedMap<K,V> m) // 公共静态方法,返回由指定导航映射支持的同步(线程安全)导航映射 public static <K,V> NavigableMap<K,V> synchronizedNavigableMap(NavigableMap<K,V> m)得到严格类型集合:用来创建类型安全的集合。这个方法在运行时检查集合中添加的元素是否符合预期的类型,如果不符合,就会抛出 ClassCastException。
java// 公共静态方法,返回由指定集合支持的类型安全(在运行时检查类型)的集合 public static <E> Collection<E> checkedCollection(Collection<E> c,Class<E> type) // 公共静态方法,返回由指定队列支持的类型安全(在运行时检查类型)的队列 public static <E> Queue<E> checkedQueue(Queue<E> queue, Class<E> type) // 公共静态方法,返回由指定集合支持的类型安全(在运行时检查类型)的集合 public static <E> Set<E> checkedSet(Set<E> s, Class<E> type) // 公共静态方法,返回由指定排序集支持的类型安全(在运行时检查类型)的排序集 public static <E> SortedSet<E> checkedSortedSet(SortedSet<E> s,Class<E> type) // 公共静态方法,返回由指定导航集支持的类型安全(在运行时检查类型)的导航集 public static <E> NavigableSet<E> checkedNavigableSet(NavigableSet<E> s,Class<E> type) // 公共静态方法,返回由指定列表支持的类型安全(在运行时检查类型)的列表 public static <E> List<E> checkedList(List<E> list, Class<E> type) // 公共静态方法,返回由指定映射支持的类型安全(在运行时检查类型)的映射 public static <K, V> Map<K, V> checkedMap(Map<K, V> m,Class<K> keyType,Class<V> valueType) // 公共静态方法,返回由指定排序映射支持的类型安全(在运行时检查类型)的排序映射 public static <K,V> SortedMap<K,V> checkedSortedMap(SortedMap<K, V> m,Class<K> keyType, Class<V> valueType) // 公共静态方法,返回由指定导航映射支持的类型安全(在运行时检查类型)的导航映射 public static <K,V> NavigableMap<K,V> checkedNavigableMap(NavigableMap<K, V> m,Class<K> keyType,Class<V> valueType)返回一个空集合或迭代器:没有数据时返回一个值,避免空指针
java// 返回一个空的迭代器。此迭代器不包含任何元素,hasNext 方法总是返回 false。 public static <T> Iterator<T> emptyIterator() // 返回一个空的列表迭代器。此迭代器不包含任何元素,hasNext 和 hasPrevious 方法总是返回 false。 public static <T> ListIterator<T> emptyListIterator() // 返回一个空的枚举。此枚举不包含任何元素,hasMoreElements 方法总是返回 false。 public static <T> Enumeration<T> emptyEnumeration() // 返回一个空的、不可变的集合。此集合不包含任何元素,size 方法总是返回 0。 public static final Set EMPTY_SET = new EmptySet<>(); // 返回一个空的、不可变的集合。此集合不包含任何元素,size 方法总是返回 0。 public static final <T> Set<T> emptySet() // 返回一个空的、不可变的排序集。此集合不包含任何元素,size 方法总是返回 0。 public static <E> SortedSet<E> emptySortedSet() // 返回一个空的、不可变的导航集。此集合不包含任何元素,size 方法总是返回 0。 public static <E> NavigableSet<E> emptyNavigableSet() // 返回一个空的、不可变的列表。此列表不包含任何元素,size 方法总是返回 0。 public static final List EMPTY_LIST = new EmptyList<>(); // 返回一个空的、不可变的映射。此映射不包含任何键值对,size 方法总是返回 0。 public static final <K,V> Map<K,V> emptyMap() // 返回一个空的、不可变的排序映射。此映射不包含任何键值对,size 方法总是返回 0。 public static final <K,V> SortedMap<K,V> emptySortedMap() // 返回一个空的、不可变的导航映射。此映射不包含任何键值对,size 方法总是返回 0。 public static final <K,V> NavigableMap<K,V> emptyNavigableMap()返回只有一个元素的不可变集合:
java// 返回一个只包含指定对象的不可变集合。尝试添加或删除元素都会抛出 UnsupportedOperationException。 public static <T> Set<T> singleton(T o) // 返回一个只包含指定对象的不可变列表。尝试添加或删除元素都会抛出 UnsupportedOperationException。 public static <T> List<T> singletonList(T o) // 返回一个只包含指定键值对的不可变映射。尝试添加或删除键值对都会抛出 UnsupportedOperationException。 public static <K,V> Map<K,V> singletonMap(K key, V value) // 返回一个不可变列表,该列表由指定对象的n个副本组成。 public static <T> List<T> nCopies(int n, T o)集合转换
java// 返回指定 collection 的枚举。用于遍历数据集合,类似于现在的Iterator接口。然而,与Iterator相比,Enumeration的功能更为简单,只提供了遍历(nextElement)和检查是否有更多元素(hasMoreElements)的方法。这个方法主要用于向后兼容,因为一些早期的API使用Enumeration作为返回类型 public static <T> Enumeration<T> enumeration(final Collection<T> c) // 返回一个由指定枚举的元素组成的 ArrayList。 public static <T> ArrayList<T> list(Enumeration<T> e) // 返回由指定映射支持的 set。传入一个空的map,得到拥有该map性质的Set。如Map<String, Boolean> map = new IdentityHashMap<>();Set<String> set = Collections.newSetFromMap(map);或者Currentmap(没有对应Set) public static <E> Set<E> newSetFromMap(Map<E, Boolean> map) public static <E> SequencedSet<E> newSequencedSetFromMap(SequencedMap<E, Boolean> map) // 返回指定双端队列支持的后进先出(LIFO)队列。在这个方法返回的队列中,add方法映射到push,remove方法映射到pop等。这个视图在你需要使用一个需要Queue的方法,但你需要LIFO顺序时会很有用。 public static <T> Queue<T> asLifoQueue(Deque<T> deque)
哈希表分析
hashCode在哈希表中使用
如果数组可以足够大,那么就可以直接用 hashCode值当下标。但是实际中数组不可能足够大,那么会用hashCode值,通过某种公式 计算出一个合理的hash值作为数组下标:下标 = hash值 & (数组的长度-1)
hash计算公式:即高16位按位异或低16位 static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }- hash冲突概率降低,但是无法避免
- 数组的每一种下标都有可能,,尽量让(key,value)均匀存放到HashMap中,但是不能保证绝对均匀。而且不能保证按顺序存储,中间可能有空位。
hash冲突:
- 两个对象的hashCode值相同
- 两个对象的hashCode不同,但是经过计算 index相同
hash冲突的解决:
hash冲突意味着数组的某个位置需要存储多个元素。需要重新设计这个元素的类型,不能直接存储元素的值,而是要把元素用“结点”封装起来,这个结点可以是链表的结点,也可以是“树”的结点。JDK1.7:使用纯链表结点封装。JDK1.8:既有链表结点又有树结点(而且还是红黑树结点)
树的好处,就是提高了查询效率。但是红黑树比较复杂,而且每次添加和删除的时候,都要调整,会使得效率降低。当链表的结点个数没有那么多的时候,使用链表反而更快。所以就存在了链表和树的转换。
什么时候需要从链表变成树? (1)数组的长度>=64 static final int MIN_TREEIFY_CAPACITY = 64; (2)链表结点的个数>8 static final int TREEIFY_THRESHOLD = 8; 什么时候会从树变回链表? (1)一直删除时,如果树的结点个数少于UNTREEIFY_THRESHOLD(6)个时,会考虑变会链表(称为反树化)。 同时还要考虑:删除过程中发现 当树的根结点的左或右结点为NULL时,就会考虑反树化。 或者当树的根结点的左左结点为NULL时,也会考虑反树化。 (2)添加操作引起了扩容,扩容过程中,因为移动位置导致树的结点个数少于6个,会考虑把树变为链表。 什么时候扩容? (1)当map的元素个数size > threshold时,就会扩容 扩容为原来的2倍。 第一次:threshold(阈值)= DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY 后面:threshold(阈值)= loadFactor(默认值是0.75) * table.length(最开始是16) = 原来的threshold * 2; 假设:table.length是64,threshold = 64*0.75=48 (2)节点达到8个,但是数组长度不够64。 数组的长度变大了(扩容为2倍),就要重新计算下标。变了就会导致(key,value)换一个位置存储,原来链表有8个节点,可能换位置之后可能没有8个了 跟踪源码发现,HashMap的Entry实现类,不管是JDK1.7的Entry类,还是JDK1.8类的Node类 都会存储hash值。为什么要存储? 因为我们每一次查询,添加、删除等操作。 以查询为例: (key,value)在不在map中。 用要查询的对象的key的hash值与原有的(key,value)的key的hash值做比较, hash值相同的情况下,才会比较equals方法。 如果hash不存起来,每一次比较的时候都要重新计算,这就会影响效率
遍历和迭代
- 概念:用来遍历集合元素的对象/工具。获取迭代器,需要实现java.util.Iterator接口。
- Iterable接口:实现这个接口允许对象成为 "foreach" 语句的目标。 (JDK1.5增加)数组默认都是实现了这个接口。所有Collection系列的集合实现类都实现了Iterable接口。其有一个抽象方法Iterator iterator(),可以说明foreach本质上依赖于java.util.Iterator接口
- 方法:集合.iterator():获取当前集合的迭代器对象,通过迭代器调用下方方法
- boolean hasNext():判断集合当前指向位置是否为空
- Object next():取出当前元素,并且迭代器【指针】往后移动
- void remove() :用于删除刚刚迭代的元素
- 注意,迭代器对象必须要用时在创建,因为迭代器内部的expectedModCount在创建时由集合modCount赋值,集合增删时会改变modCount,进而出现expectedModCount!=modCount,报异常。
public class TestIterator {
@Test
public void test02() {
Collection coll = new ArrayList();
coll.add("hello");
coll.add("world");
coll.add("html");
coll.add("mysql");
coll.add("bigdata");
//获取迭代器对象
Iterator iterator = coll.iterator();
while(iterator.hasNext()){
String s = (String) iterator.next();
if(s.contains("o")){
iterator.remove();//删除刚刚next方法取出的元素
}
}
System.out.println(coll);
}常用类及API
Object类
在Java中,所有类都有一个公共的父类,那就是java.lang.Object类。被称为Java的根父类。
Object类型的变量,可以和任意类型的对象构成“多态引用”。
基本数据类型使用Object接受,会自动转换为对应包装类
javaObject obj=1;
Object[]数组,可以接收任意类型的对象数组,所有“对象”都可以调用Object类中声明的方法。
Object有一个无参构造,所有类对象的创建都会直接会间接的调用这个构造器。
toString方法:public String toString()
- 调用方式:
- 通过对象.toString()调用
- System.out.println方法在打印对象时自动调用toString
- 在对象与字符串进行“+”拼接时自动调用
- 注意:如果子类没有重写,继承的Object类中的toString,默认返回包.类名@对象的hashCode值的十六进制值
- 调用方式:
getClass:public final Class<?> getClass()
返回此对象的运行时类(class +包名.类名),不能子类重写
javaList<String> list =new ArrayList<>(); System.out.println(list.getClass()); //输出 class java.util.ArrayList
equals:public boolean equals (Object obj)
作用:用于比较两个对象是否 “相等”。如果子类没有重写Object类的equals方法,等价于 “==”。(java中==比较,基本类型比较值,引用类型可以认为比较地址)
注意:判断对象属性之前,还需要判断是否为同一个对象,是否为空,类型是否相同
@Override
public boolean equals(Object o) {
if (this == o)//如果地址值相同,标明这是一个对象,自己和自己相同返回true
return true;
if (o == null || getClass() != o.getClass())//如果要比较的为空,或者两个对象的类型不同返回false
return false;//getClass()等价于this.getClass()
Student student = (Student) o;//将类进行向下转化,转换为运行时内存才可以访问其成员变量
return age == student.age && sex == student.sex && Objects.equals(name, student.name);
//比较两个字符串使用Objects.equals(name, student.name)
//"Aa".equals("Aa")
}hashCode:public native int hashCode()
作用:返回该对象的哈希码值,int类型。
组成:如果没有重写hashCode方法,则对象的hashCode值是通过地址计算得出;若是重写后则不一定。String、包装类等均重写了hashCode方法。
bigDecimal的hashCode
javapublic int hashCode() { if (this.intCompact != -9223372036854775808L) { long val2 = this.intCompact < 0L ? -this.intCompact : this.intCompact; int temp = (int)((long)((int)(val2 >>> 32) * 31) + (val2 & 4294967295L)); return 31 * (this.intCompact < 0L ? -temp : temp) + this.scale; } else { return 31 * this.intVal.hashCode() + this.scale; } }Interger
javapublic static int hashCode(int value) { return value; }- Object
java调用本地方,通过地址计算得出 public native int hashCode();equals方法和hashCode方法关系:
- 如果两个对象equals返回true,那么这两个的hashCode一定要相同。
- 如果两个对象hashCode值不相同,那么这两个对象equals也一定要不相等。
- 如果两个对象的hashCode相同的,那么这个两个对象equals不一定相同。//"Aa"和"BB"
存在上述关系的原因:
在hash系列的集合之中,value对象的下标是通过key对象的hashCode的值计算出来的,因为未重写前是通过地址得出的hashCode值,那么就会出现相同的key对象,hashCode值不同,即下标不同,则无法访问正确的位置,在使用时就会出现逻辑错误。
所以上述关系存在的前提是:需要使用HashMap,HashSet等Java集合。用不到哈希表的话,其实仅仅重写equals()方法也可以。
对象下标与其key的hashCode值关系 【下标】 = 对象的hashCode值 & (数组的长度 - 1)。计算的结果范围[0, 数组的长度-1]
finalize:protected void finalize() throws Throwable
作用:当垃圾回收器(GC)确定某个对象是垃圾对象时,由GC调用此方法。子类重写 finalize 方法,以配置系统资源或执行其他清除(系统资源:IO流、数据库连接、在内存中开辟的空间等【new的空间是属于java虚拟机中会自动释放,但是调用c的代码可能会在虚拟机外内存开辟空间,目的是释放这一部分】)。
注意:每一个对象的finalize方法仅会被调用一次。就算对象在finalize方法中被复活了(即在finalize方法中意外的又有某个引用指向了当前对象),下次GC就不调用它的finalize方法了。
只调用一次原因: 性能问题:如果在每次GC时都调用对象的finalize方法,那么有可能会导致无限循环地调用finalize方法并不断地复活对象,从而影响垃圾回收的效率。 避免程序员滥用:finalize方法的初衷是为了在对象被回收之前执行一些清理操作,而不是用于故意阻止对象被回收。如果允许多次调用finalize方法并反复复活对象,那么程序员可能会滥用这一特性,导致垃圾回收机制变得不稳定。

在java9中已经被废弃了,且之后可能会被移出
clone:protected native Object clone() throws CloneNotSupportedException: 创建并返回此对象的一个副本。
notify:public final native void notify(): 唤醒在此对象监视器上等待的单个线程。
notifyAll:public final native void notifyAll(): 唤醒在此对象监视器上等待的所有线程。
wait:使当前线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者超过某个指定的时间量。
javapublic final void wait() throws InterruptedException public final void wait(long timeoutMillis) throws InterruptedException public final void wait(long timeoutMillis, int nanos) throws InterruptedException
Object工具类
在比较两个对象的时候,Object的equals方法容易抛出空指针异常,而Objects类中的equals方法就优化了这个问题。方法如下:
public static boolean equals(Object a, Object b):判断两个对象是否相等。
javaObjects.equals(new int[]{1, 2, 3}, new int[]{1, 2, 3}); // 返回false,因为比较的是数组的引用public static boolean deepEquals(Object a, Object b) :检查两个对象是否深度相等。这个方法主要用于数组的深度比较。内部调用的就是Arrays的方法
public static String toIdentityString(Object o):生成一个对象的标识字符串。这个字符串由对象的类名和对象的哈希码组成,中间用"@"符号连接。
o.getClass().getName() + "@" + Integer.toHexString(System.identityHashCode(o));
包装类
概述
- 定义:将基本数据类型包装为对象,使其可以使用java中为对象增加的新特性。
| 序号 | 基本数据类型 | 包装类(java.lang包) |
|---|---|---|
| 1 | byte | Byte |
| 2 | short | Short |
| 3 | int | Integer |
| 4 | long | Long |
| 5 | float | Float |
| 6 | double | Double |
| 7 | char | Character |
| 8 | boolean | Boolean |
| 9 | void | Void |
装箱拆箱:jdk1.5后才有自动拆装,只支持对应类型之间
基本数据类型 -> 包装类对象:装箱
java//手动装箱 Integer objNum = new Integer(num); Integer objNum2 = Integer.valueOf(num); //自动装箱 Integer obj = 5;//左边是包装类型,右边是int包装类对象->基本数据类型:拆箱
java//手动拆箱 int i = objNum.intValue(); //自动拆箱 Integer i=5 int j=i;
包装类缓存
部分包装类有缓存对象
Byte:-128~127 Short:-128~127 Integer:-128~127 Long:-128~127 Character: 0-127 最原始的ASCII表范围字符串 Boolean:true,false Float和Double不缓存缓存对象存在的原因
- 如果每一次自动装箱,都产生新对象的话,就会导致包装类对象泛滥,内存紧张。而-128~127范围内的数字在程序中出现的概率非常高,就可以将这些对象被缓存起来,重复使用。(缓存对象是针对自动装箱的,new出来的不是缓存对象。包装类.valueOf()也使用缓存对象。)
- 包装类重写了Object的equals方法,比较两个包装对象里面的值
javaInteger obj1 = 1; //自动装箱,把int值转为包装类的对象 Integer obj2 = 1; //自动装箱,把int值转为包装类的对象 System.out.println(obj1 == obj2);//true。比较两个对象地址值,因为指向的是同一个对象,所以true。 System.out.println(obj1.equals(obj2));//true。包装类重写了Object的equals方法,比较两个包装对象里面的值。
包装类对象:
包装类数值一旦修改,就是指向新对象。
包装类的比较:
- 如果是包装类和基本数据类型之间(无论它们是否对应)都是先把包装类拆箱后,按照基本数据类型的比较规则进行。
- 如果都是包装类比较,必须是同一种类型之间比较,不同类型报错。且不包装类之间无法转换
javaInteger p = 1000;//包装类 double q = 1000;//基本数据类型 System.out.println(p==q);//p拆箱为int,int自动转化为double,比较相同,true。
Integer
静态成员和构造函数
java//最大值 Integer.MAX_VALUE //最小值 Integer.MIN_VALUE public Integer(String s) public Integer(int value)值转换
javapublic byte byteValue() public short shortValue() public int intValue() public long longValue() public float floatValue() public double doubleValue() // 通过无符号转换将参数转换为long。 public static long toUnsignedLong(int x);进制转换
java//转换十六进制 public static String toHexString(int i) //转换为八进制 public static String toOctalString(int i) //转换为二进制 public static String toBinaryString(int i)转换为字符串
java//转换为字符串 public static String toString(int i) //将数字识别为无符号,转换为字符串 public static String toUnsignedString(int i) //radix作为基数,当基数为2时,表示二进制;当基数为10时,表示十进制;当基数为36时,表示使用了所有的0-9和a-z的字符。因为在Java中,数字到字符串的转换使用了一组字符来表示数字,这组字符包括0-9的十个阿拉伯数字和26个英文字母,总共36个字符,所以radix范围为2到36。如果不在2到36,默认使用10作为基数。 public static String toString(int i, int radix) //转换为无符号的字符串,radix作为基数,2-36 public static String toUnsignedString(int i, int radix)字符串转换为值
java//转换为int public static int parseInt(String s) public static int parseUnsignedInt(String s)//无符号 //字符串转换为int,radix作为基数,2-36 public static int parseInt(String s, int radix) public static int parseUnsignedInt(String s, int radix)//无符号 //截取字符串beginIndex(包括)到endIndex(不包括),转换为radix作为基数(2-36)的数字 public static int parseInt(CharSequence s, int beginIndex, int endIndex, int radix) public static int parseUnsignedInt(CharSequence s, int beginIndex, int endIndex, int radix)//无符号 //转换为值,与parseInt(返回int)的区别是返回值返回Integr public static Integer valueOf(String s, int radix) public static Integer valueOf(String s) public static Integer valueOf(int i) //将字符串解码为Integer对象。字符串可以表示为十进制、十六进制或八进制数。 public static Integer decode(String nm) throws NumberFormatException;位运算
java// 返回指定int值的二进制补码表示中最高位(最左边)的一个位的值。 public static int highestOneBit(int i); // 返回指定int值的二进制补码表示中最低位(最右边)的一个位的值。 public static int lowestOneBit(int i); // 返回输入整数的二进制表示中前导零的数量 public static int numberOfLeadingZeros(int i); // 返回输入整数的二进制表示中尾部零的数量 public static int numberOfTrailingZeros(int i); // 返回输入整数的二进制表示中1的数量 public static int bitCount(int i); // 将输入整数的二进制表示向左旋转指定的距离 public static int rotateLeft(int i, int distance); // 将输入整数的二进制表示向右旋转指定的距离 public static int rotateRight(int i, int distance); // 返回一个整数,该整数是通过反转输入整数的二进制表示得到的 public static int reverse(int i); //i中与mask中1对应的位保留,与mask中0对应的位删除,并将保留的位向右移动以填充删除的位的空位。 //mask的二进制表示中的1对应于i的第2、3、6、7位(从右向左计数,从0开始)。保留i这些位,并将它们向右移动以填充被删除的位的空位。 //int i = 0b10101010; //int mask = 0b11001100; //1010 public static int compress(int i, int mask); //compress方法的逆操作。将i中的位插入到mask中为0的位置,而mask中为1的位置则保持不变。即返回压缩前的i public static int expand(int i, int mask);其他函数
java//得到系统变量,nm为key,val为默认值 public static Integer getInteger(String nm, int val) public static Integer getInteger(String nm) public static Integer getInteger(String nm, int val) // 比较两个Integer对象的数值大小。 public int compareTo(Integer anotherInteger); // 比较两个int值的大小。 public static int compare(int x, int y); // 以无符号方式比较两个int值的大小。 @IntrinsicCandidate//标记某个方法可能会被JVM的即时编译器(JIT)替换为一种更高效的机器码实现 public static int compareUnsigned(int x, int y); // 返回将第一个参数除以第二个参数的无符号商,其中每个参数和结果都被解释为无符号值。 @IntrinsicCandidate public static int divideUnsigned(int dividend, int divisor); // 返回将第一个参数除以第二个参数的无符号余数,其中每个参数和结果都被解释为无符号值。 @IntrinsicCandidate public static int remainderUnsigned(int dividend, int divisor); // 返回输入整数的符号函数,如果i为负则返回-1,如果i为正则返回1,如果i为0则返回0 public static int signum(int i); // 返回一个整数,该整数是通过反转输入整数的字节顺序得到的 public static int reverseBytes(int i); //返回一个包含该实例的 Optional。 public Optional<Integer> describeConstable(); //在Integer中返回自身,传null就好 public Integer resolveConstantDesc(MethodHandles.Lookup lookup);
Long
public static String toHexString(long i)
public static String toOctalString(long i)
public static String toBinaryString(long i)
public static String toUnsignedString(long i)
public static long parseLong(String s, int radix)
public static long parseLong(CharSequence s, int beginIndex, int endIndex, int radix)
public static long parseLong(String s)
public static long parseUnsignedLong(String s)
public static long parseUnsignedLong(String s, int radix)
public static long parseUnsignedLong(CharSequence s, int beginIndex, int endIndex, int radix)
public byte byteValue()//其他类型同理
public static Long decode(String nm)
public static Long valueOf(String s, int radix)
public static Long getLong(String nm)
public static Long getLong(String nm, Long val)
public static int compareUnsigned(long x, long y)
public static long divideUnsigned(long dividend, long divisor)
public static long highestOneBit(long i)
public static long lowestOneBit(long i)
public static long highestOneBit(long i)
public static long lowestOneBit(long i)
public static int numberOfLeadingZeros(long i)
public static int numberOfTrailingZeros(long i)
public static int bitCount(long i)
public static int bitCount(long i)
public static long rotateLeft(long i, int distanc
public static long rotateRight(long i, int distance)
public static long reverse(long i)
public static long compress(long i, long mask)
public static long expand(long i, long mask)
public static int signum(long i)
public static long reverseBytes(long i) Float
public static String toHexString(float f)
public static float parseFloat(String s)
public static float valueOf(String s)
// 如果指定的数是一个 Not-a-Number (NaN) 值,则返回 true,否则返回 false。
public static boolean isNaN(float v)
// 如果指定的数在数量上是无穷大的,则返回 true,否则返回 false。
public static boolean isInfinite(float v)
// 如果参数是一个有限的浮点值,则返回 true;否则(对于 NaN 和无穷大的参数)返回 false。
public static boolean isFinite(float d)
//将float的二进制识别为int,所有NaN值映射到一个特定的long值
public static int floatToIntBits(float value)
//将float的二进制识别为int,不同NaN值映射到不同的long值
public static native int floatToRawIntBits(float value)
//将int二进制识别为float
public static native float intBitsToFloat(int bits);
//将Short二进制识别为float
public static float float16ToFloat(short floatBinary16)
//将float二进制识别为Short
public static short floatToFloat16(float f)
// 比较两个 Double 对象的数值大小
public int compareTo(Float anotherDouble);
// 比较两个指定的 double 值的大小
public static int compare(float d1, float d2);
// 将两个 double 值相加
public static float sum(float a, float b);
// 返回两个 double 值中的较大值
public static float max(float a, float b);
// 返回两个 double 值中的较小值
public static float min(float a, float b);
// 返回包含此实例的名义描述符的 Optional,该实例就是此实例本身
@Override
public Optional<Float> describeConstable();
// 将此实例解析为 ConstantDesc,其结果就是此实例本身
@Override
public Float resolveConstantDesc(MethodHandles.Lookup lookup);Double
// 返回double参数的十六进制字符串表示形式
public static String toHexString(double d)
// 返回一个表示指定的 double 值的 Double 实例。
public static Double valueOf(double d)
// 返回一个新的 double,初始化为由指定的 String 表示的值,如同由类 Double 的 valueOf 方法执行的那样。
public static double parseDouble(String s)
// 如果指定的数是一个 Not-a-Number (NaN) 值,则返回 true,否则返回 false。
public static boolean isNaN(double v)
// 如果指定的数在数量上是无穷大的,则返回 true,否则返回 false。
public static boolean isInfinite(double v)
// 如果参数是一个有限的浮点值,则返回 true;否则(对于 NaN 和无穷大的参数)返回 false。
public static boolean isFinite(double d)
// 返回此 Double 的 double 值。(同理还有其他类型的值)
public double doubleValue()
// 将此对象与指定的对象进行比较(Double或其子类)。使用doubleToLongBits方法将浮点数转换为长整数表示,这个方法将所有NaN值映射到一个特定的long值,将正负无穷大映射到特定的long值。这样,当比较两个NaN或无穷大的Double对象时,equals方法将返回true
public boolean equals(Object obj)
// 返回根据 IEEE 754 浮点“双精度格式”位布局,将64位double识别为Long,所有NaN值映射到一个特定的long值。
public static long doubleToLongBits(double value)
// 返回根据 IEEE 754 浮点“双精度格式”位布局,将64位double识别为Long,保留了NaN值的所有可能的表示。
public static native long doubleToRawLongBits(double value);
// 将 long 类型的 bits 转换为 double 类型
public static native double longBitsToDouble(long bits);
// 比较两个 Double 对象的数值大小
public int compareTo(Double anotherDouble);
// 比较两个指定的 double 值的大小
public static int compare(double d1, double d2);
// 将两个 double 值相加
public static double sum(double a, double b);
// 返回两个 double 值中的较大值
public static double max(double a, double b);
// 返回两个 double 值中的较小值
public static double min(double a, double b);
// 返回包含此实例的名义描述符的 Optional,该实例就是此实例本身
@Override
public Optional<Double> describeConstable();
// 将此实例解析为 ConstantDesc,其结果就是此实例本身
@Override
public Double resolveConstantDesc(MethodHandles.Lookup lookup);Byte
public static byte parseByte(String s, int radix)
public static Byte valueOf(String s, int radix)
public static Byte decode(String nm)
public byte byteValue()//其他类型同理
public static int compareUnsigned(byte x, byte y)
public static int toUnsignedInt(byte x)
public static long toUnsignedLong(byte x)Character
//将指定基数中的字符转换为整数。
Character.digit(char ch,int raidx);
//作用是将指定基数中的整数转换为字符。
Character.forDigit(int digit,int radix);
// 判断字符是否是数字
public static boolean isDigit(char ch);
// 判断字符是否是字母
public static boolean isLetter(char ch);
// 判断字符是否是字母或数字
public static boolean isLetterOrDigit(char ch)
// 判断是否是小写字符
public static boolean isLowerCase(char ch);
// 判断是否是大写字符
public static boolean isUpperCase(char ch);
// 判断是否是空格
public static boolean isWhitespace(char ch);
// 将字符转换为小写
public static char toLowerCase(char ch);
// 将字符转换为大写
public static char toUpperCase(char ch);
// 将字符转换为字符串
public static String toString(char c);Boolean
// 定义一个Boolean对象,表示原始值为true
public static final Boolean TRUE = new Boolean(true);
// 定义一个Boolean对象,表示原始值为false
public static final Boolean FALSE = new Boolean(false);
// 解析字符串参数为boolean。如果字符串参数不为null且等于字符串"true",则返回的boolean表示值为true。否则,返回false值,包括null参数
public static boolean parseBoolean(String s) {
return "true".equalsIgnoreCase(s);
}
// 返回一个由指定字符串表示的值的Boolean。如果字符串参数不为null且等于字符串"true",则返回的Boolean表示真值。否则,返回假值,包括null参数
public static Boolean valueOf(String s) {
return parseBoolean(s) ? TRUE : FALSE;
}
//使用Optional包装
public Optional<DynamicConstantDesc<Boolean>> describeConstable() Short
public static short parseShort(String s, int radix) throws NumberFormatException
public static Short valueOf(String s, int radix)
public static Short decode(String nm) throws NumberFormatException
public static int compareUnsigned(short x, short y)
public static short reverseBytes(short i)
public static int toUnsignedInt(short x)
public static long toUnsignedLong(short x)
public byte byteValue()//其他类型同理经典接口
java.lang.Comparable接口 <a name="Comparable"> </a>
描述:它只有一个唯一的抽象方法: int compareTo(Object o),用于比较两个对象的“大小”关系的。
Integer、String等这些基本类型的JAVA封装类都已经实现了Comparable接口,compareTo方法也被称为自然比较方法。- Comparator要求元素是对象而不是基础数据类型。
this.compareTo(其他对象) 大于:返回正整数 等于:返回0 小于:返回附证书
java.util.Comparator接口 <a name="Comparator"> </a>
描述:有一个抽象方法:int compare(Object o1, Object o2),用于对象比较大小的。这个接口是对Comparable接口的补充。在List集合sort排序时需要传入一个自定义实现Comparator的对象。
实现类.Compare(对象一,对象二) 大于:返回正整数 等于:返回0 小于:返回附证书
java.text.Collator
java//Comparator的子类,可以指定排序的语言环境,如指定按照中文(拼音)排序 Collator instance = Collator.getInstance(Locale.CHINA);java.lang.Cloneable接口
描述:用于对象的克隆,复制,唯一的作用是用于标记该类是可以克隆的(浅克隆,克隆对象内的对象不会重新创建,而是引用原先对象)。
使用:在java.lang.Object根父类中有一个克隆对象的方法:protected Object clone() throws CloneNotSupportedException
- 权限修饰符:protected,所以要跨包【lang包外】使用就要在子类中可以重写这个方法,修改protected为public。
- 类调用的时候,必须在类中实现java.lang.Cloneable接口
javapublic class SupClass implements Cloneable{ @Override public Object clone() throws CloneNotSupportedException { return super.clone(); } } public static void main(String[] args) { SupClass supClass=new SupClass(8); try { Object clone = supClass.clone(); ((SupClass)clone);//此对象除了地址和supClass不同,内部属性均一致 } catch (CloneNotSupportedException e) { e.printStackTrace(); } }
java.lang.Iterable接口:
描述:这个接口有一个抽象方法:Iterator iterator(),实现这个接口允许对象成为 "foreach" 语句的目标。
foreach:是JDK1.5增加的一个新语法,叫做增强for循环。作用是遍历数组和集合容器的元素的。
数组和容器内部均已经实现了该接口。 for(元素的类型 元素临时名称 : 要遍历的对象){ ……………… }
常见包
java.lang.Math
Math.abs():求绝对值
Math.ceil():向上取整
Math.floor():向下取整
Math.round():四舍五入【强制类型转化是直接舍弃小数部分】
Math.pow():返回a的b幂次方法
Math.sqrt():返回a的平方根
Math.max():返回x,y中的最大值
Math.min():返回x,y中的最小值
Math.PI:π的值
Math.random():返回[0,1)的随机值
javaMath.random():产生[0,1)的随机小数 Math.random()*6:产生[0,6)的随机小数 Math.random()*6+1:产生[1,7)的随机小数 int a=(int)(Math.random()*6+1):产生[1,6]的随机整数 int a=(int)Math.random()*6+1:若是不加括号,a的结果永远为0.因为[0,1)的小数强转为int永远为零
java.math包
BigInteger:大整数
- BigInteger的构造方法可以直接传入数字,也可以传入字符串、char数组、byte数组
- 通过对象方法进行运算:add、subtract、multiply、divide、remainder(取模)
BigDecimal:长小数
- 浮点型精度不准确,且数据范围有限,此时可以使用BigDecimal。构造方式支持数字(不精确),字符串(精确),字符数组。
- 通过对象调用方法:add、subtract、multiply、divide、remainder(取模)
- divide若出现除不尽情况会报算数异常,可以选择则保留位数和保留方式。 BigDecimal b1 = new BigDecimal("56693.457821158555557822114445574744555744"); BigDecimal b2 = new BigDecimal("5853.457821158555557822114445574744555744"); System.out.println("b1 / b2 = " + b1.divide(b2,20, RoundingMode.FLOOR));
- RoundingMode枚举类
- CEILING :正向取。
- DOWN :零向取。
- UP:向零两边取
- FLOOR:负向取。
- HALF_DOWN :向最接近数字方向舍入的舍入模式,如果与两个相邻数字的距离相等,则向下舍入。
- HALF_EVEN:向最接近数字方向舍入的舍入模式,如果与两个相邻数字的距离相等,则向相邻的偶数舍入。
- HALF_UP:向最接近数字方向舍入的舍入模式,如果与两个相邻数字的距离相等,则向上舍入。
- UNNECESSARY:用于断言请求的操作具有精确结果的舍入模式,因此不需要舍入。
java.util.Random
- 作用:通过Random对象生成随机数
- 方法
boolean nextBoolean():返回随机boolean 值。
void nextBytes(byte[] bytes):生成随机字节并将其置于用户提供的 byte 数组中。
double nextDouble():返回随机double值,分布于0.0 和 1.0。
float nextFloat():返回随机float值,分布于0.0 和 1.0
double nextGaussian():返回呈高斯(“正态”)分布的 double 值,其平均值是 0.0,标准差是 1.0。
int nextInt():返回随机的 int 值。
int nextInt(int n):返回0到n的随机int值,不包括n
long nextLong():返回随机long值
日期时间
JDK1.8之前
java.util.Date
new Date():当前系统时间
System.out.println(new Date()); 结果:Wed Aug 09 10:59:13 CST 2023long getTime():返回该日期时间对象距离1970-1-1 0.0.0 0毫秒之间的毫秒值
System.out.println(new Date().getTime()); 结果:1691550023209new Date(long 毫秒):把该毫秒值换算成日期时间对象
java.text.SimpleDateFormat
SimpleDateFormat用于日期时间的格式化。
java//将字符串转为Date public void test10() throws ParseException{ String str = "2019年06月06日 16时03分14秒 545毫秒 星期四 +0800"; //y:表示年份,M表示月份,d表示天,H表示24小时制,h表示12小时制,ss表示秒,SSS表示毫秒,E表示星期,Z表示时区 //顺序可调换,但是对应字符不能改变 SimpleDateFormat sf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒 SSS毫秒 E Z"); //将其转化为Date类型 Date d = sf.parse(str); //Thu Jun 06 16:03:14 CST 2019 System.out.println(d); } //将日期格式化为指定类型 public void test9(){ //获得时间 Date d = new Date(); //传入格式化的要求类型 SimpleDateFormat sf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒 SSS毫秒 E Z"); //通过parse方法进行转化 String str = sf.format(d); //2019年06月06日 16时03分14秒 545毫秒 星期四 +0800 System.out.println(str); }
java.util.TimeZone
TimeZone timeZone1 = TimeZone.getDefault();基于程序运行所在的时区创建
TimeZoneTimeZone timeZone2 = TimeZone.getTimeZone("Asia/Shanghai");通过时区 ID 获取
TimeZone常见时区ID:
- Asia/Shanghai
- UTC
- America/New_York
java.util.Calendar
通过Calendar.getInstance()获取一个Calendar对象,对象中包括当前时间的信息,创建时可以指定时区对象,不指定默认当前时区。
time=1691552010558, areFieldsSet=true, areAllFieldsSet=true, lenient=true, zone=sun.util.calendar.ZoneInfo[id="Asia/Shanghai",offset=28800000,dstSavings=0,useDaylight=false,transitions=19,lastRule=null] firstDayOfWeek=1, minimalDaysInFirstWeek=1, ERA=1, YEAR=2023, MONTH=7, WEEK_OF_YEAR=32, WEEK_OF_MONTH=2, DAY_OF_MONTH=9, DAY_OF_YEAR=221, DAY_OF_WEEK=4, DAY_OF_WEEK_IN_MONTH=2, AM_PM=0, HOUR=11, HOUR_OF_DAY=11, MINUTE=33, SECOND=30, MILLISECOND=558, ZONE_OFFSET=28800000, DST_OFFSET=0示例代码:
javapublic class TestCalendar { public void test2(){ TimeZone t = TimeZone.getTimeZone("America/Los_Angeles"); Calendar c = Calendar.getInstance(t); int year = c.get(Calendar.YEAR); int month = c.get(Calendar.MONTH)+1; int day = c.get(Calendar.DATE); int hour = c.get(Calendar.HOUR_OF_DAY); int minute = c.get(Calendar.MINUTE); //2023-8-9 11:33 System.out.println(year + "-" + month + "-" + day + " " + hour + ":" + minute); } }
JDK1.8后
本地日期时间
LocalDate:只有日期,即年月日,不能调用时分秒相关函数,其余函数均相同。
LocalTime:只有时间,即时分秒,不能调用年月日相关函数,其余函数均相同。
LocalDateTime:既有日期,又有时间
注意:
- 三个对象均是单例模式,只能有一个对象,通过now静态方法获取
静态方法:
now() / now(ZoneId zone):静态方法,根据当前时间创建对象/指定时区的对象
javaLocalDate now = LocalDate.now(); System.out.println(now); //输出结果 2023-08-09of():静态方法,根据指定日期/时间创建对象
java//三个形参分别为年、月、日,为int类型 LocalDate of = LocalDate.of(2023, 8, 9); System.out.println(of); //输出结果 2023-08-09 //month还可以为Month枚举类型 LocalDate of = LocalDate.of(2023, JANUARY, 9); 2023-01-09
年月日相关:
时分秒的函数对应,但是由LocalTime调用。
getDayOfMonth():获得距离月初天数(1-31)
getDayOfYear() : 获得距离年初天数(1-366)
getDayOfWeek() :获得星期几对象,返回一个 DayOfWeek 枚举值
getMonth():获得月份对象, 返回一个 Month 枚举值
getMonthValue() :获取月份,返回int值
getYear():获取年份,返回int值
withDayOfMonth():修改当前月份天数,并返回新的对象
withDayOfYear():修改当前年份天数,并返回新的对象
withMonth():修改月份,并返回新的对象
withYear() : 修改年份,返回新的对象
with(TemporalAdjuster t):将当前日期时间设置为校对器指定的日期时间
plus(TemporalAmount t)/minus(TemporalAmount t):添加或减少一个 Duration 或 Period
plusDays():向当前对象添加几天,返回当前对象
plusWeeks():向当前对象添加几周,返回当前对象
plusMonths():向当前对象添加几月,返回当前对象
plusYears():向当前对象添加几年,返回当前对象
minusDays():向当前对象添加几天,返回当前对象
minusWeeks():向当前对象添加几周,返回当前对象
minusMonths():向当前对象添加几月,返回当前对象
minusYears():向当前对象添加几年,返回当前对象
isLeapYear():判断是否是闰年(在LocalDate类中声明)
isBefore()/isAfter():比较两个 LocalDate/LocalTime
java//2023-08-09 System.out.println(now.getDayOfMonth());//9 System.out.println(now.getDayOfYear());//221 System.out.println(now.getDayOfWeek());//WEDNESDAY System.out.println(now.getMonth());//AUGUST System.out.println(now.getYear());//2023 System.out.println(now.getMonthValue());//8
格式化:
parse(Charsequence text):将指定格式的字符串解析为日期、时间
java//将日期字符串解析为LocalDateTime时间,parse默认的是ISO 8601日期格式,即yyyy-MM-dd HH:mm:ss可以直接转换 LocalDateTime date1 = LocalDateTime.parse("2023-11-07 16:45:27"), //如果不是ISO 8601日期格式,需要指定,转换后的格式默认是ISO 8601日期格式 LocalDate.parse("01/01/2021", DateTimeFormatter.ofPattern("dd/MM/yyyy"));format(DateTimeFormatter t):格式化本地日期、时间,返回一个字符串
使用DateTimeFormatter定义好的格式
javaSystem.out.println(now.format(DateTimeFormatter.ISO_DATE));//2023-08-09使用FormatStyle定义好的格式
java//LocalDate类型 System.out.println(now.format(DateTimeFormatter.ofLocalizedDate(FormatStyle.FULL)));//2023年8月9日 星期三 System.out.println(now.format(DateTimeFormatter.ofLocalizedDate(FormatStyle.SHORT)));//23-8-9 System.out.println(now.format(DateTimeFormatter.ofLocalizedDate(FormatStyle.MEDIUM)));//2023-8-9 System.out.println(now.format(DateTimeFormatter.ofLocalizedDate(FormatStyle.LONG)));//2023年8月9日 //LocalTime类型,注意,其FULL类型需要添加上时区 System.out.println(localTime.format(DateTimeFormatter.ofLocalizedTime(FormatStyle.FULL).withZone(ZoneId.systemDefault())));//下午04时26分57秒 CT System.out.println(localTime.format(DateTimeFormatter.ofLocalizedTime(FormatStyle.SHORT)));//下午4:23 System.out.println(localTime.format(DateTimeFormatter.ofLocalizedTime(FormatStyle.MEDIUM)));//16:23:16 System.out.println(localTime.format(DateTimeFormatter.ofLocalizedTime(FormatStyle.LONG)));//下午04时23分16秒自定义类型:ofPattern方法
java//2023年08月09日 System.out.println(now.format(DateTimeFormatter.ofPattern("yyyy年MM月dd日"))); //今天是2024年05月07日 System.out.println(LocalDate.now().format(DateTimeFormatter.ofPattern("今天是yyyy年MM月dd日")))
时区日期时间
ZondId
Set<String> availableZoneIds = ZoneId.getAvailableZoneIds():获取所有时区对象
ZoneId.of("America/New_York"):获取当前时区对象
javaSystem.out.println(ZoneId.of("America/New_York")); //输出结果:America/New_York
ZonedDateTime:
- ZonedDateTime.now():获取当前时区日期时间对象
- ZonedDateTime.now(ZoneId.of("America/New_York")):获取指定时区,时区日期对象
javaZonedDateTime t1 = ZonedDateTime.now(); System.out.println(t1); ZonedDateTime t2 = ZonedDateTime.now(ZoneId.of("America/New_York")); System.out.println(t2);ZoneDateTime是在日期时间上加上了时区,所以其方法中也包括LocalDate、LocalTime等方法,如format。
持续日期/时间
Period:用于计算两个“日期”间隔
Duration:用于计算两个“时间”间隔,可以包含年月日,但是要有时分秒
import org.junit.Test;
import java.time.Duration;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.Period;
public class TestPeriodDuration {
@Test
public void test06(){
LocalDate t1 = LocalDate.now();
LocalDate t2 = LocalDate.of(2018, 12, 31);
Period between = Period.between(t1, t2);
System.out.println(between);//P-4Y-7M-9D
//没有进行换算
System.out.println("相差的年数:"+between.getYears());//相差的年数:-4
System.out.println("相差的月数:"+between.getMonths());//相差的月数:-7
System.out.println("相差的天数:"+between.getDays());//相差的天数:-9
System.out.println("相差的总月数:"+between.toTotalMonths());//相差的总数:-55
}
@Test
public void test02(){
LocalDateTime t1 = LocalDateTime.now();
LocalDateTime t2 = LocalDateTime.of(2017, 8, 29, 0, 0, 0, 0);
Duration between = Duration.between(t1, t2);
System.out.println(between);//PT-52122H-30M-45.257S
//计算的是总的,全部进行了换算
System.out.println("相差的总天数:"+between.toDays());//相差的总天数:-2171
System.out.println("相差的总小时数:"+between.toHours());//相差的总小时数:-52122
System.out.println("相差的总分钟数:"+between.toMinutes());//相差的总分钟数:-3127350
System.out.println("相差的总秒数:"+between.getSeconds());//相差的总秒数:-187641046
System.out.println("相差的总毫秒数:"+between.toMillis());//相差的总毫秒数:-187641045257
System.out.println("相差的总纳秒数:"+between.toNanos());//相差的总纳秒数:-187641045257000000
System.out.println("不够一秒的纳秒数:"+between.getNano());//不够一秒的纳秒数:743000000
}
}系统相关类
System类:
static long currentTimeMillis() :返回当前系统时间距离1970-1-1 0:0:0的毫秒值
static void exit(int status) :退出当前系统【0表示正常,非零表示异常】
static void gc() :运行垃圾回收器。
static String getProperty(String key):获取某个系统属性
javajava.version//JDK版本 user.language//语言环境的语句类型 user.country//语言环境的国家名称 file.encoding//文件的编码 user.name//用户名 os.version//操作系统的版本 os.name//操作系统的名称Properties properties = System.getProperties();:获取系统所有属性
public static void arraycopy(Object src,int srcPos,Object dest,int destPos,int length):数组拷贝
java参数1:原数组 参数2:原数组的起始下标 参数3:目标数组 参数4:目标数组的起始下标 参数5:长度/元素个数 拷贝原数组指定长度个元素到目标数组,可以拷贝自己到自己【从前面开始拷贝和后面开始拷贝,确保拷贝后数据不发生改变,可以用于插入数据和删除数据】
Runtime类:
- Runtime属于单例模式,无法new,只能通过静态方法返回对象,即Runtime runtime = Runtime.getRuntime();
- public static Runtime getRuntime():得到当前java运用程序Runtime对象。
- public long totalMemory():返回 Java 虚拟机中的内存总量【bytes单位】。返回值取决于主机环境。
- public long freeMemory():返回Java 虚拟机中的空闲内存量【bytes单位】。调用 gc 方法可能导致 返回值的增加。
Arrays数组工具类
java.util.Arrays数组工具类提供的方法重载了各种类型,下方以int和Object类型为例
数组元素排序【其他参数类型使用对应的重载函数】
static void sort(int[] a) :将a数组按照从小到大进行排序
static void sort(int[] a, int fromIndex, int toIndex) :将a数组的[fromIndex, toIndex)部分按照升序排列
static void sort(Object[] a)
- 根据元素的自然顺序对指定对象数组按升序进行排序。要求排序的对象实现java.lang.Comparable接口。
static <T> void sort(T[] a, Comparator<? super T> c) :根据指定比较器产生的顺序对指定对象数组进行排序。
sort(T[] a, int fromIndex, int toIndex, Comparator<? super T> c) :根据指定比较器产生的顺序对指定对象数组的指定范围进行排序
String的自然排序使是按照字符的Unicode编码值比较,中文的拼音顺序并不完全符合Unicode编码,所以使用Collator 类执行区分语言环境的 String 比较。
java//Collator是Comparator子类 Collator c=Collator.getInstance(Locale.CHINA); sort(array,c);实现逆序:Comparator比较的元素类型必须是对象
javaInteger[] a={1,2,9,4,5,6}; Arrays.sort(a,new Comparator<Integer>(){ @Override public int compare(Integer o1, Integer o2) { return o1<o2?1:o1==o2?0:-1; } });
public static void parallelSort(byte[] a) :并行排序,利用多核处理器的优势,将数组分成多个部分,然后在不同的处理器核心上同时进行排序,最后再将结果合并。并行排序在大型数组上有优势,但在小型数组上,并行排序可能会因为线程管理的开销而比传统的排序方法更慢。(使用Dual-Pivot Quicksort的排序算法)
数组前缀和【其他参数类型使用对应的重载函数】
public static void parallelPrefix(long[] array, int fromIndex,int toIndex, LongBinaryOperator op):数组中每个元素都被替换为原数组中到该位置为止的所有元素的累积操作结果。具体来说,对于数组中的每个元素array[i],这个方法会将array[i]的值更新为op.apply(array[0], op.apply(array[1], ... op.apply(array[i-1], array[i])...))。其他参数类型使用对应的重载函数
javaInteger[] array = {1, 2, 3, 4, 5}; BinaryOperator<Integer> operator = Integer::sum; Arrays.parallelPrefix(array, operator); System.out.println(Arrays.toString(array)); // 输出:[1, 3, 6, 10, 15]数组元素二分查找【其他参数类型使用对应的重载函数】
- static int binarySearch(int[] a, int key)
- static int binarySearch(Object[] a, Object key)
- 注意:
- 要求数组有序
- 在数组中查找key是否存在,如果存在返回第一次找到的下标(即使有多个),不存在返会-(插入下标) - 1。
- 对象数组二分要求实现Comparator
数组的复制【其他参数类型使用对应的重载函数】
static int[] copyOf(int[] original, int newLength) :根据original原数组复制一个长度为newLength的新数组,并返回新数组,newLength小于原始数组的长度,只包含原始数组的前newLength个元素。newLength大于原始数组的长度,只包含原始数组的前newLength个元素,剩余用null填充。
static <T> T[] copyOf(T[] original,int newLength):根据original原数组复制一个长度为newLength的新数组,并返回新数组,newLength小于原始数组的长度,只包含原始数组的前newLength个元素。newLength大于原始数组的长度,只包含原始数组的前newLength个元素,剩余用null填充。
static int[] copyOfRange(int[] original, int from, int to) :复制original原数组的[from,to)构成新数组,并返回新数组
static<T> T[] copyOfRange(T[] original,int from,int to):复制original原数组的[from,to)构成新数组,并返回新数组
填充数组【其他参数类型使用对应的重载函数】
static void fill(int[] a, int val) :用val值填充整个a数组
static void fill(int[] a, int fromIndex, int toIndex, int val):将a数组[fromIndex,toIndex)部分填充为val值
static void fill(Object[] a, int fromIndex, int toIndex, Object val) :将a数组[fromIndex,toIndex)部分填充为val对象
其他函数
hashcode计算:public static int hashCode(float[] a) :根据数组的元素获取数组hash值(直接通过数组获取hash值,得到的值是基于数组对象的内存地址来计算的),其他参数类型使用对应的重载函数
java//对于对象数组,还存在一个方法。 //hashCode(Object[] a) 方法会直接使用数组元素的 hashCode() 方法来计算哈希码,而数组的 hashCode方法并不是基于数组中元素的内容来计算的,而是基于数组对象的内存地址来计算的。如果数组元素本身也是一个数组,那么它将使用这个数组对象的hashCode()方法,而不会深入到这个数组的元素。 //deepHashCode(Object[] a) 方法则会深入到数组的元素,如果元素是一个数组,它会递归地调用 deepHashCode 来计算这个数组元素的哈希码,直到元素不再是数组为止。 public static int deepHashCode(Object[] a)数组判等【其他参数类型使用对应的重载函数】:static boolean equals(int[] a, int[] a2) :比较两个数组的长度、元素是否完全相同
javapublic static boolean equals(Object[] a, Object[] a2) { if (a==a2)//1、先判断是否为同一个数组 return true; if (a==null || a2==null)//2、判断是否为空 return false; /*if(a.getClass().getComponentType()!=a2.getClass().getComponentType())//判断数组元素类型是否相同 return false;*/ int length = a.length;//3、再比较长度 if (a2.length != length) return false; for (int i=0; i<length; i++) {//4、最后在一个个比较 Object o1 = a[i]; Object o2 = a2[i]; if (!(o1==null ? o2==null : o1.equals(o2))) return false; } return true; } //对于对象数组存在额外方法: //equals:如果数组的元素是另一个数组(即多维数组),这个方法会直接比较这两个元素数组,而不会递归地比较元素数组中的元素。 //deepEquals:会递归地比较两个数组中的元素。如果元素是一个数组,它会继续递归地比较这个数组的元素,直到遇到非数组的元素。 public static boolean deepEquals(Object[] a1, Object[] a2)数组元素拼接【其他参数类型使用对应的重载函数】:static String toString(Object[] a) :将对象元素拼接为字符串,对象元素的值通过调用其toString方法获得。形式为:[元素1,元素2,元素3。。。]
java//对于对象数组存在额外方法 //toString(Object[] a) 如果数组元素本身也是数组,那么 toString(Object[] a) 方法会调用该元素数组的 toString() 方法,这将返回该元素数组的身份信息,而不是它的内容。 //deepToString(Object[] a) 方法则会深入到数组的元素,如果元素是一个数组,它会递归地调用 deepToString 来生成这个数组元素的字符串表示,直到元素不再是数组为止。 public static String deepToString(Object[] a)生成器函数初始化数组【其他参数类型使用对应的重载函数】
java//生成器函数的执行时间较长,并且不依赖于元素的顺序,那么 parallelSetAll 方法可能是一个更好的选择。否则,setAll 方法可能更为适合。 //串行 public static <T> void setAll(T[] array, IntFunction<? extends T> generator) //并行 public static <T> void parallelSetAll(T[] array, IntFunction<? extends T> generator)并行切分函数【其他参数类型使用对应的重载函数】
java//创建一个覆盖整个数组的 Spliterator。 public static <T> Spliterator<T> spliterator(T[] array) //创建一个覆盖数组中指定范围的元素的 Spliterator。这个范围从 startInclusive(包含)开始,到 endExclusive(不包含)结束。如果 startInclusive 和 endExclusive 相等,那么创建的 Spliterator 将不覆盖任何元素。 public static spliterator(T[] array, int startInclusive, int endExclusive)创建流【其他参数类型使用对应的重载函数】
java//创建一个覆盖整个数组的流。 stream(T[] array) //创建一个覆盖数组中指定范围的元素的流。这个范围从 startInclusive(包含)开始,到 endExclusive(不包含)结束。如果 startInclusive 和 endExclusive 相等,那么创建的流将不包含任何元素。 stream(T[] array, int startInclusive, int endExclusive)数组比较【其他参数类型使用对应的重载函数】
java//如果两个数组在长度和所有对应位置的元素都相等,那么这两个数组被认为是相等的,方法返回 0。如果在某个位置,数组 a 的元素小于数组 b 的元素,那么方法返回一个负数;如果数组 a 的元素大于数组 b 的元素,那么方法返回一个正数。 public static <T extends Comparable<? super T>> int compare(T[] a, T[] b) //比较两个数组中指定范围的元素。这个范围从 aFromIndex(包含)开始,到 aToIndex(不包含)结束,以及从 bFromIndex(包含)开始,到 bToIndex(不包含)结束。如果在指定范围内,两个数组的所有对应位置的元素都相等,那么这两个数组被认为是相等的,方法返回 0。如果在某个位置,数组 a 的元素小于数组 b 的元素,那么方法返回一个负数;如果数组 a 的元素大于数组 b 的元素,那么方法返回一个正数。 public static <T extends Comparable<? super T>> int compare(T[] a, int aFromIndex, int aToIndex,T[] b,int bFromIndex, int bToIndex) public static int compareUnsigned(short[] a, int aFromIndex, int aToIndex,short[] b, int bFromIndex, int bToIndex) public static int compareUnsigned(short[] a, short[] b) public static <T> int compare(T[] a, int aFromIndex, int aToIndex,T[] b, int bFromIndex, int bToIndex,Comparator<? super T> cmp) public static <T> int compare(T[] a, T[] b,Comparator<? super T> cmp) public static <T> int compare(T[] a, int aFromIndex, int aToIndex,T[] b, int bFromIndex, int bToIndex,Comparator<? super T> cmp) //从 aFromIndex(包含)开始,到 aToIndex(不包含)结束,以及从 bFromIndex(包含)开始,到 bToIndex(不包含)结束。如果在指定范围内,两个数组的所有对应位置的元素都相等,那么返回 -1。否则,返回第一个不匹配的元素的索引。 public static <T> int mismatch(T[] a, int aFromIndex, int aToIndex,T[] b, int bFromIndex, int bToIndex,Comparator<? super T> cmp) public static <T> int mismatch(T[] a, T[] b, Comparator<? super T> cmp)
String
特点:
String类的对象是不可变的。
字符串的任何修改都会返回新对象。
为什么设计为不可变
1、线程安全。同一个字符串实例可以被多个线程共享,因为字符串不可变,本身就是线程安全的。 2、支持hash映射和缓存。因为String的hash值经常会使用到,比如作为 Map 的键,不可变的特性使得 hash 值也不会变,不需要重新计算。 3、出于安全考虑。网络地址URL、文件路径path、密码通常情况下都是以String类型保存,假若String不是固定不变的,将会引起各种安全隐患。比如将密码用String的类型保存,那么它将一直留在内存中,直到垃圾收集器把它清除。假如String类不是固定不变的,那么这个密码可能会被改变的,导致出现安全隐患。 4、字符串常量池优化。String对象创建之后,会缓存到字符串常量池中,下次需要创建同样的对象时,可以直接返回缓存的引用。
字符串共享:字符串常量对象【""直接表示的对象】可以实现共享。即相同字符串常量的地址是相同的。
new String时,在堆中创建一个String对象,其数组指向常量区的一个char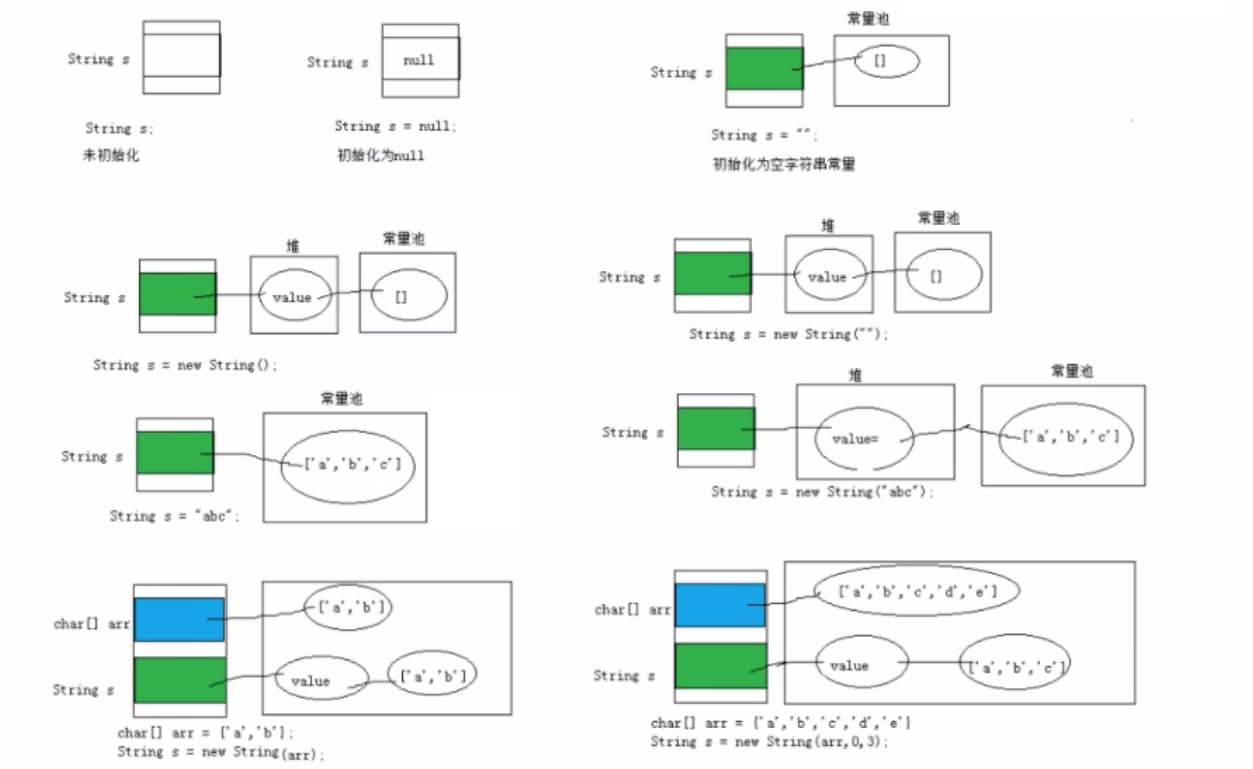
字符串不可变的原因:
- private final char value[]; final修饰意味着value数组不能指向新数组
- String类是final修饰的,不可以改变
- String类中所有方法的设计,只要涉及到字符串内容的修改的,都会返回一个新对象
底层实现:
- JDK1.9之前:char[],
- JDK1.9之后:byte[]。若仅有Latin-1字符【0-256】,就按照1字节的规格进行分配内存,反之,就按照2字节/字符的规格进行分配。
字符串创建
- String s=" ":字符串常量
- String s= new String();new字符串对象
- 支持无参,int[],byte[],char[],StringBuffer,StringBuild
- String.valueOf(); 将其它类型转化为字符串 。
- 支持基本数据,char[],不支持byte,StringBuffer,StringBuild
字符串比较
比较地址值: == , 只有两个字符串常量池中的字符串==比较才会返回true,其他的都是false
比较是否相等:
- boolean equals(另一个字符串) :String类重写的Object类的equals,严格区分大小写
- boolean equalsIgnoreCase(另一个字符串):忽略大小写的比较内容
比较大小:String实现了java.lang.Comparable,支持自然排序
- int compareTo(Object obj):严格区分大小写,按照字符的Unicode编码值比较大小
- int compareToIgnoreCase(另一个字符串):忽略大小写的比较大小
使用中文拼音比较
- Collator.getInstance(Locale.CHINA).compare(s1, s2)
和其他比较
- public boolean contentEquals(StringBuffer sb)
- public boolean contentEquals(CharSequence cs)
指定比较范围
public boolean regionMatches(int toffset, String other, int ooffset, int len)
java//比较此字符串从 toffset 索引开始的 len 个字符与另一个字符串 other 从 ooffset 索引开始的 len 个字符是否相等。 toffset:此字符串中子区域的起始索引。 other:另一个字符串。 ooffset:另一个字符串中子区域的起始索引。 len:要比较的字符数量。public boolean regionMatches(boolean ignoreCase, int toffset,String other, int ooffset, int len)
ignoreCase:是否忽略大小写
字符串拼接
+:和任意类型进行拼接,结果为字符串
concat(String s):限定字符串
拼接后位置:
- 常量池中的字符串拼接,结果还是在常量池。若有一方不是,则结果在堆中。
- intern():将字符串结果放进常量池
public static String join(CharSequence delimiter,Iterable<? extends CharSequence> elements) :使用
JavaList<String> list = Arrays.asList("Java", "Python", "C++"); String result = String.join(", ", list); // result = "Java, Python, C++"
常用方法
boolean isEmpty():字符串是否为空
int length():返回字符串的长度
String concat(xx):拼接,等价于+
boolean equals(Object obj):比较字符串是否相等,区分大小写
boolean equalsIgnoreCase(Object obj):比较字符串是否相等,不区分大小写
int compareTo(String other):比较字符串大小,区分大小写,按照Unicode编码值比较大小
int compareToIgnoreCase(String other):比较字符串大小,不区分大小写
String toLowerCase():将字符串中大写字母转为小写
String toUpperCase():将字符串中小写字母转为大写
String trim():去掉字符串前后空白符
public String strip() :去掉字符串前后所有空白符(包括trim无法去除的部分)
public String intern():结果在常量池中共享
public String stripLeading() :去除字符串前面的空白字符
public String stripTrailing():去除字符串后面的字符
public boolean isBlank():判断字符串是否为空白字符串,""也是空白字符
查找方法
- boolean contains(xx):是否包含xx
- int indexOf(xx):从前往后找当前字符串中xx,即如果有返回第一次出现的下标,要是没有返回-1
- int lastIndexOf(xx):从后往前找当前字符串中xx,即如果有返回最后一次出现的下标,要是没有返回-1
截取方法
- String substring(int beginIndex) :返回一个新的字符串,它是此字符串的从beginIndex开始截取到最后的一个子字符串
- String substring(int beginIndex, int endIndex) :返回一个新字符串,从beginIndex(包含)开始截取到endIndex(不包含)
- public CharSequence subSequence(int beginIndex, int endIndex) :返回一个新字符串,从beginIndex(包含)开始截取到endIndex(不包含)
编码与解码
- 概念:当字符串不仅仅是在内存中使用时,需要把它写到文件,或者发送到网络中,这个时候就要把字符串转为字节数组处理。
- 编码:把字符串转为字节数组
- 解码:把字节数组翻译为字符串
- byte[] getBytes():编码,把字符串变为字节数组,按照平台默认的字符编码方式进行编码
- byte[] getBytes(字符编码方式):按照指定的编码方式进行编码
- new String(byte[] ):解码,按照平台默认的字符编码进行解码
- new String(byte[], int offset, int length) :从offset开始,往后length长度
- new String(byte[],字符编码方式 ) :指定编码
- new String(byte[],int offset, int length,字符编码方式):从offset开始,往后length长度
- 概念:当字符串不仅仅是在内存中使用时,需要把它写到文件,或者发送到网络中,这个时候就要把字符串转为字节数组处理。
字符串转换
char charAt(index):返回[index]位置的字符
public int codePointAt(int index):返回[index]位置的字符对应的码
char[] toCharArray(): 返回字符数组,new了一个新的字符数组拷贝返回,因为String对象不变。
String(char[] value):字符数组转化为String。
String(char[] value, int offset, int count):字符数组指定范围转化为String。
static String copyValueOf(char[] data): 返回指定数组中表示该字符序列的 String
static String copyValueOf(char[] data, int offset, int count):返回指定数组中表示该字符序列的 String
static String valueOf(char[] data, int offset, int count) : 返回指定数组中表示该字符序列的 String
static String valueOf(char[] data) :返回指定数组中表示该字符序列的 String
字符串开头与结尾
- boolean startsWith(xx):是否以xx开头
- boolean endsWith(xx):是否以xx结尾
字符串替换
String replace(xx,xx):不支持正则
String replaceFirst(正则,value):替换第一个匹配部分
String repalceAll(正则, value):替换所有匹配部分
str.replaceAll("\\s", "");:替换所有空白字符public boolean matches(String regex):是否满足正则
字符串拆分
String[] split(正则):按照某种规则进行拆分,返回一个字符串数组,每个String储存一个拆分的部分
javapublic static void main(String[] args) { String s1="41hello278word378"; s1=s1.replaceAll("^\\d+|\\d+$","");//开头被拆分会出现空串"",所以要提前使用replaceAll替换, //^\\d+表示开头一位或多位数字,\\d+$表示末尾一位或者多位数字,|表示或,多出来的\表示防止转义 String[] arr=s1.split("\\d+"); for (String s : arr) { System.out.println(s); } } //将字符串分隔为对象 public static void main(String[] args) { String str="张三.23|李四.24|王五.25"; String[] student=str.split("\\|");//先分隔为一个个对象,|在正则表达式中也有含义,所以\\转义 for (String s : student) { String[]tmp=s.split("\\.");//对象内部在进行数据分隔,.在正则表达式中也有含义,所以\\转义 System.out.println(new Student(tmp[0],Integer.parseInt(tmp[1])).toString()); } }public String[] splitWithDelimiters(String regex, int limit):regex为切分正则,limit为限制切分次数
java1、会将匹配的分隔符(也就是 ":::")包含在返回的结果数组中。 2、会根据正则切分limit-1次(例如limit为1,就会返回原数组),如果limit为0或者负数,则会切割所有。如果没有可以切割的,返回的即原数组 String str = "boo:::and:::foo"; String[] result = str.splitWithDelimiters(":::", 2); // result = { "boo", ":::", "and:::foo" }
StringBuilder和StringBuffer
StringBuffer:最早的字符串缓冲区类,是线程安全的。
StringBuilder:JDK1.5之后引入,线程不安全。因为大多数时候,StringBuffer和StringBuilder的对象都是被单个线程使用,而不是多线程。单线程不存在安全问题,就没必要加同步锁,加锁反而降低性能。
与String区别:String是不可变的字符串对象,StringBuffer和StringBuilder是可变的字符串对象。
常用API:StringBuilder、StringBuffer的API是完全一致的
- StringBuffer append(xx):拼接,追加,其同样支持+
- StringBuffer insert(int index, xx):在[index]位置插入xx
- StringBuffer delete(int start, int end):删除[start,end)之间字符
- StringBuffer deleteCharAt(int index):删除[index]位置字符
- void setCharAt(int index, xx):替换[index]位置字符
- StringBuffer reverse():反转
- void setLength(int newLength) :设置当前字符序列长度为newLength
- StringBuffer replace(int start, int end, String str):替换[start,end)范围的字符序列为str
- int indexOf(String str):在当前字符序列中查询str的第一次出现下标,未找到返回-1.
- int indexOf(String str, int fromIndex):在当前字符序列[fromIndex,最后]中查询str的第一次出现下标,未找到返回-1.
- int lastIndexOf(String str):在当前字符序列中查询str的最后一次出现下标
- int lastIndexOf(String str, int fromIndex):在当前字符序列[fromIndex,最后]中查询str的最后一次出现下标
- String substring(int start):截取当前字符序列[start,最后]
- String substring(int start, int end):截取当前字符序列[start,end)
- String toString():返回此序列中数据的字符串表示形式
- StringBuilder s1=new StringBUilder(s);//s是String类型,将String类型转换为StringBuilder类型,StringBuffer同理
内部value数组:
所有修改的方法,是直接在value数组上进行修改的,如果涉及到扩容,也是会new新的数组。
java无参构造:16 public StringBuilder() { super(16); } 有参构造 public StringBuilder(String str) { super(str.length() + 16); append(str); } 扩容机制:原来的长度*2+2【防止初始传入容量为0】
网络编程
软件结构
C/S结构 :全称为Client/Server结构,是指客户端和服务器结构。常见程序有QQ、红蜘蛛、飞秋等软件。
B/S结构 :全称为Browser/Server结构,是指浏览器和服务器结构。常见浏览器有IE、谷歌、火狐等。
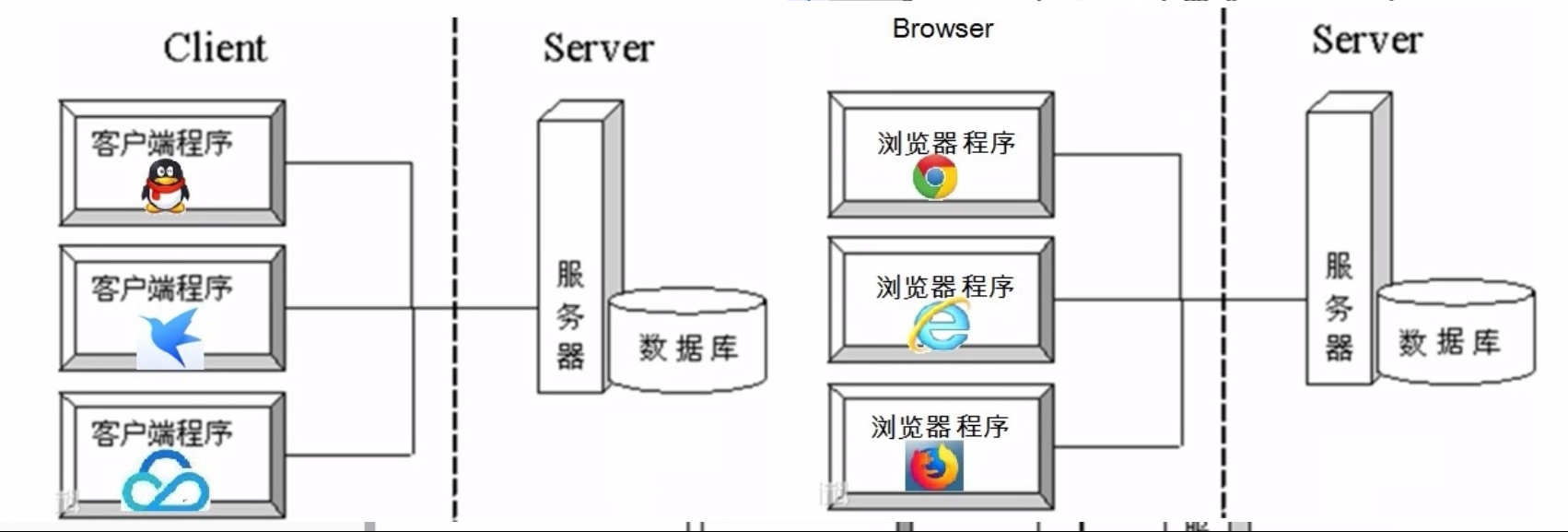
网络编程三要素
Ip地址和域名
IP
作用:IP地址用来给一个网络中的计算机设备做唯一的编号,唯一标识网络中的设备。
IPv4和Ipv6
- IPv4:是一个32位的二进制数。每八个二进制位为一组,分成四组十进制。
- IPv6:128位地址长度,每16个字节一组,分成8组十六进制数
公网和私网IP:公网地址( 万维网使用,可以被他人访问)和 私有地址( 局域网使用,不可以被他人)。192.168.开头的就是私有址址,范围即为192.168.0.0--192.168.255.255,专门为组织机构内部使用
常用命令:
- 查看本机IP地址,在控制台输入:ipconfig
- 检查网络是否连通,在控制台输入:ping 空格 IP地址,如ping 220.181.57.216
特殊的IP地址:
本地回环地址(hostAddress):
127.0.0.1主机名(hostName):
localhost
域名
- 因为IP地址数字不便于记忆,因此出现了域名,当在连接网络时输入域名后,域名服务器(DNS)负责将域名转化成IP地址【域名解析】,并进行访问
端口号
- 作用:网络通信,本质上是两个进程(应用程序)的通信。每台计算机都有很多的进程,在网络通信时,通过端口号就可以唯一标识设备中的进程(应用程序)了
- 注意:
- 组成:用两个字节表示的整数,它的取值范围是0~65535。
- 端口号组成:
- 公认端口:0~1023。被预先定义的服务通信占用,如:HTTP(80),FTP(21),Telnet(23)
- 注册端口:1024~49151。分配给用户进程或应用程序。如:Tomcat(8080),MySQL(3306),Oracle(1521)。
- 动态/ 私有端口:49152~65535。临时分配给客户端应用程序的一组端口号。
- 如果端口号被另外一个服务或应用所占用,会导致当前程序启动失败。
网络通信协议
概念:通过计算机网络可以使多台计算机实现连接,位于同一个网络中的计算机在进行连接和通信时需要遵守一定的规则
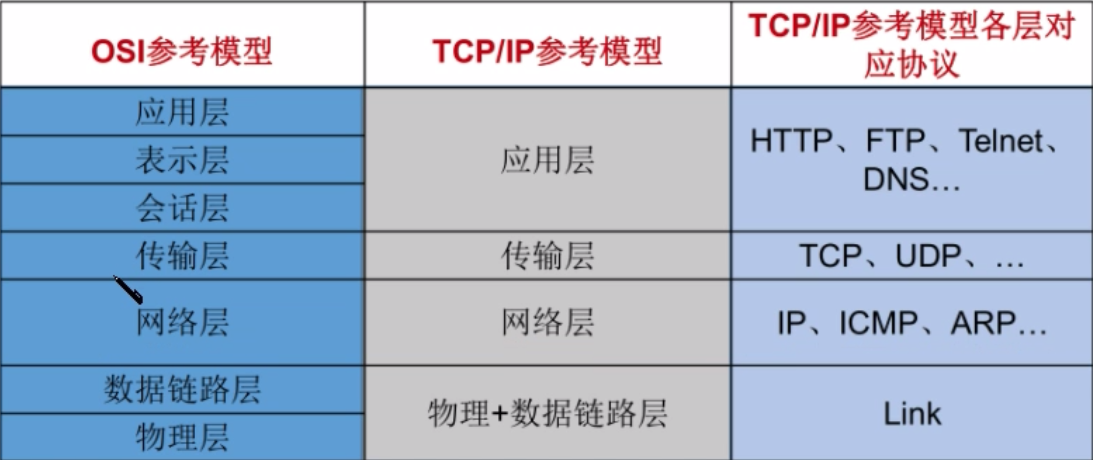
TCP和UDP协议:位于运输层的协议。
UDP协议:用户数据报协议(User Datagram Protocol),它是不面向链接,不可靠的无连接通信协议,在数据传输时,数据的发送端和接收端不建立逻辑连接。即发送端不会确认接收端是否存在,就会发出数据,同样接收端在收到数据时,也不会向发送端反馈是否收到数据。由于使用UDP协议消耗资源小,通信效率高,所以通常都会用于音频、视频和普通数据的传输例如视频会议都使用UDP协议,因为这种情况即使偶尔丢失一两个数据包,也不会对接收结果产生太大影响。但是在使用UDP协议传送数据时,由于UDP的面向无连接性,不能保证数据的完整性,因此在传输重要数据时不建议使用UDP协议。而且其一次发送数据被限制在64kb以内,超出这个范围就不能发送了。
TCP协议:传输控制协议 (Transmission Control Protocol)。它是面向连接的,可靠的通信协议,即传输数据之前,在发送端和接收端建立逻辑连接,然后再传输数据,它提供了两台计算机之间可靠无差错的数据传输。是一种面向连接的、可靠的、基于字节流的传输层的通信协议,可以连续传输大量的数据。类似于打电话的效果。
TCP三次握手与四次挥手:
当一台计算机需要与另一台远程计算机连接时,TCP协议会采用“三次握手”方式让它们建立一个连接,用于发送和接收数据的虚拟链路。数据传输完毕TCP协议会采用“四次挥手”方式断开连接。
三次握手: 第一次握手:建立连接时,客户端发送syn包(seq=j)到服务器,并进入SYN_SENT状态,等待服务器确认; 第二次握手:服务器收到syn包,必须确认客户端的SYN(ack=j+1),同时自己也发送一个SYN包(seq=k),即SYN+ACK包,此时服务器进入SYN_RECV状态。 [3] 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态 四次挥手 (1) TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送。 (2) 服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。 (3) 服务器关闭客户端的连接,发送一个FIN给客户端。 (4) 客户端发回ACK报文确认,并将确认序号设置为收到序号加1。TCP协议使用重发机制,当一个通信实体发送一个消息给另一个通信实体后,需要收到另一个通信实体确认信息,如果没有收到另一个通信实体确认信息,则会再次重复刚才发送的消息。
两种协议一般是共同使用的,如微信的视频电话,在接通时通过TCP协议进行,在接通后通过UDP进行【因为丢失几个数据包无大影响】
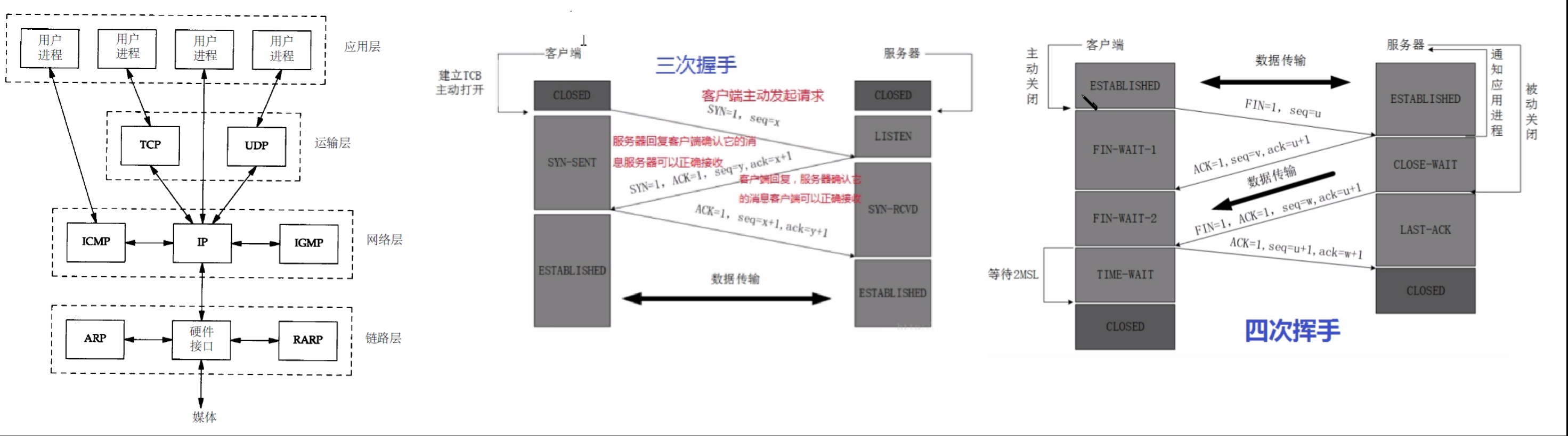
网络编程API
在Java Web开发中,InetAddress 和 Socket 相关的类通常不会直接使用。这是因为在Web开发中,我们通常使用的是更高级的抽象,如Servlets、JSPs、Spring MVC等,这些技术已经封装了底层的网络通信细节。
InetAddress类
概述:InetAddress类主要表示IP地址,存在两个子类:Inet4Address、Inet6Address。
表示主机地址:
域名(hostName):www.atguigu.com
IP 地址(hostAddress):202.108.35.210
获取实例:InetAddress 类没有提供公共的构造器,而是提供了如下几个 静态方法来获取InetAddress 实例
public static InetAddress getLocalHost()//得到当地的构造器
public static InetAddress getByName(String host)//通过域名得到构造器
public static InetAddress getByAddress(byte[] addr)//通过IP得到构造器
javaeg: byte[] arr={(byte) 183,(byte)194,(byte)238,117};//因为byte的数据类型为-127-128.所以超过的需要强转【小于256不截断】 InetAddress allByName = InetAddress.getByAddress(arr); System.out.println(allByName);
常用方法:
- public String getHostAddress() :返回IP 地址字符串(以文本表现形式)。
- public String getHostName() :获取此 IP 地址的主机名
Socket相关类API
TCP协议:ServerSocket类【接受Socket的链接,返回一个Socket】+Sokcet类
ServerSocket类构造方法:ServerSocket(int port) :创建绑定到特定端口的服务器套接字【可以理解传输字节的管道】,端口由自己设置。
ServerSocket类常用方法:Socket accept():侦听并接受到此套接字的连接,返回Socket,即查看是否有其他程序连接了这个管道并传输数据。
Sokcet类构造方法:
- public Socket(InetAddress address,int port):创建一个流套接字并接到指定 IP 地址的指定端口号。即链接ServerSocket创建的传输字节管道
- public Socket(String host,int port):创建一个流套接字并将其连接到指定主机上的指定端口号。
Socket类常用方法:
public InputStream getInputStream():返回此套接字的输入流,可以用于接收消息
public OutputStream getOutputStream():返回此套接字的输出流,可以用于发送消息
public InetAddress getInetAddress():返回此套接字连接到的远程 IP 地址;如果套接字是未连接的,则返回 null。
public InetAddress getLocalAddress():获取套接字绑定的本地地址。
public int getPort():此套接字连接到的远程端口号;如果尚未连接套接字,则返回 0。
public int getLocalPort():返回此套接字绑定到的本地端口。如果尚未绑定套接字,则返回 -1。
public void close():关闭此套接字。套接字被关闭后,便不可在以后的网络连接中使用(即无法重新连接或重新绑定)。需要创建新的套接字对象。 关闭此套接字也将会关闭该套接字的 InputStream 和 OutputStream。
public void shutdownInput():如果在套接字上调用 shutdownInput() 后从套接字输入流读取内容,则流将返回 EOF(文件结束符)。 即不能在从此套接字的输入流中接收任何数据。
public void shutdownOutput():禁用此套接字的输出流。对于 TCP 套接字,任何以前写入的数据都将被发送,并且后跟 TCP 的正常连接终止序列。 如果在套接字上调用 shutdownOutput() 后写入套接字输出流,则该流将抛出 IOException。 即不能通过此套接字的输出流发送任何数据。
注意:先后调用Socket的shutdownInput()和shutdownOutput()方法,仅仅关闭了输入流和输出流,并不等于调用Socket的close()方法。在通信结束后,仍然要调用Scoket的close()方法,因为只有该方法才会释放Socket占用的资源,比如占用的本地端口号等。
代码:
java需求: (1)开启一个TCP协议的服务,在8888端口号监听客户端的连接。 (2)接收一个客户端的连接 (3)接收客户端发过来的单词或词语,然后我把它“反转” 例如:客户端发过来“hello",反转"olleh" (4)把反转后的单词或词语,返回给客户端 (5)直到客户端发过来"bye"为止 ()同时接收多个客户端连接 package exer3; import java.io.*; import java.net.InetAddress; import java.net.Socket; import java.util.Scanner; public class User3 { public static void main(String[] args) throws Exception{ Socket socket = new Socket(InetAddress.getLocalHost(), 9999); InputStream inputStream = socket.getInputStream(); OutputStream outputStream = socket.getOutputStream(); InputStreamReader inputStreamReader = new InputStreamReader(inputStream); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); PrintStream printStream = new PrintStream(outputStream); Scanner input=new Scanner(System.in); String str; while(true){ str=input.nextLine(); printStream.println(str); if(str.equals("bye")){ break; } System.out.println(bufferedReader.readLine()); } input.close(); printStream.close(); bufferedReader.close(); inputStream.close(); outputStream.close(); inputStream.close(); socket.close(); } } package exer3; import java.io.*; import java.net.ServerSocket; import java.net.Socket; public class Server3 { public static void main(String[] args) throws Exception { ServerSocket server = new ServerSocket(9999); int count = 0; while(true){ // 2、监听一个客户端的连接 Socket socket = server.accept(); System.out.println("第" + ++count + "个客户端"+socket.getInetAddress().getHostAddress()+"连接成功!!"); ServerThread ct = new ServerThread(socket); ct.start(); } } } class SeverThread extends Thread { public SeverThread(Socket accept) { this.accept = accept; } private Socket accept; @Override public void run() { System.out.println(accept.getInetAddress().getHostAddress() + "连接成功"); try (InputStream inputStream = accept.getInputStream(); OutputStream outputStream = accept.getOutputStream(); InputStreamReader inputStreamReader = new InputStreamReader(inputStream); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); PrintStream printStream = new PrintStream(outputStream);) { String str; while (true) { str = bufferedReader.readLine(); if (str.equals("bye")) break; StringBuilder stringBuilder = new StringBuilder(str); stringBuilder.reverse(); printStream.println(stringBuilder.toString()); } } catch (IOException e) { e.printStackTrace(); } } }
UDP协议:DataGramSocket类【发送和接受数据包】+DataGramPacket类【将数据打包】
DatagramSocket 类:
- public DatagramSocket(int port)创建数据报套接字并将其绑定到本地主机上的指定端口。套接字将被绑定到通配符地址,IP 地址由内核来选择。
- public DatagramSocket(int port,InetAddress laddr)创建数据报套接字,将其绑定到指定的本地地址。本地端口必须在 0 到 65535 之间(包括两者)。如果 IP 地址为 0.0.0.0,套接字将被绑定到通配符地址,IP 地址由内核选择。
- public void close()关闭此数据报套接字。
- public void send(DatagramPacket p)从此套接字发送数据报包。DatagramPacket 包含的信息指示:将要发送的数据、其长度、远程主机的 IP 地址和远程主机的端口号。
- public void receive(DatagramPacket p)从此套接字接收数据报包。当此方法返回时,DatagramPacket 的缓冲区填充了接收的数据。数据报包也包含发送方的 IP 地址和发送方机器上的端口号。 此方法在接收到数据报前一直阻塞。数据报包对象的 length 字段包含所接收信息的长度。如果信息比包的长度长,该信息将被截短。
DatagramPacket类的常用方法:
- public DatagramPacket(byte[] buf,int length)构造 DatagramPacket,用来接收长度为 length 的数据包。 length 参数必须小于等于 buf.length。
- public DatagramPacket(byte[] buf,int length,InetAddress address,int port)构造数据报包,用来将长度为 length 的包发送到指定主机上的指定端口号。length 参数必须小于等于 buf.length。
- public int getLength()返回将要发送或接收到的数据的长度。
练习1
使用UDP方式向接收方发送hello world
javapublic class Receiver { public static void main(String[] args) throws Exception{ //创建一个Socket,监听8999端口,在使用其receive方法时,会自动接受该端口的包 DatagramSocket s1=new DatagramSocket(8999); byte[] bytes = new byte[1024]; //创建一个包,准备接受数据 DatagramPacket s2=new DatagramPacket(bytes,bytes.length); //接受数据 s1.receive(s2); //getLength():得到数据包实际接受了实际接收了几个字节 System.out.println(new String(bytes,0,s2.getLength())); s1.close(); } } public class Send { public static void main(String[] args) throws Exception{ //没有指定IP和端口号,ip地址默认本机,端口随机分配,现在不关心发送方的IP和端口号 DatagramSocket s1=new DatagramSocket(); String str="hello world"; byte[] bytes = str.getBytes(); //构造数据报包,长度为 length,数据内容为byttes,在调用send发送时,包会发送到指定主机上的指定端口号。 // length 参数必须小于等于 bytes.length。 DatagramPacket packet=new DatagramPacket(bytes,bytes.length, InetAddress.getLocalHost(),8999); //发送该包 s1.send(packet); s1.close(); } }
练习2
java需求:每一个客户端启动后都可以给服务器上传一个文件;服务器接收到文件后保存到一个upload目录中,可以同时接收多个客户端的文件上传。 思考分析: (1)服务器端要“同时”处理多个客户端的请求,那么必须使用多线程,每一个客户端的通信需要单独的线程来处理。 (2)服务器保存上传文件的目录只有一个upload,而每个客户端给服务器发送的文件可能重名,所以需要保证文件名的唯一。我们可以使用“时间戳”作为文件名,而后缀名不变 (3)客户端需要给服务器上传文件名(含后缀名)以及文件内容。而文件名是字符串,文件内容不一定是纯文本的,因此选择ObjectOutputStream和ObjectInputStream。 public class Server { public static void main(String[] args)throws Exception { ServerSocket server = new ServerSocket(8888); while(true) { Socket socket = server.accept(); new FileUploadThread(socket).start(); } } } class FileUploadThread extends Thread{ private Socket socket; public FileUploadThread(Socket socket) { this.socket = socket; } public void run(){ /* 1、从客户端接收什么? (1)文件内容 (2)文件名? 关键时文件的“后缀名”,用于标识文件的类型。是图片还是视频还是xx。 文件名本身可以保留,也可以不要。如果直接使用原文件名,因为大家上传的文件都保持在同一个文件夹中upload,就会“重名”问题,互相覆盖。 2、那么如何避免文件重名呢? (1)方案一:每个用户有单独的文件夹(比较高级),必须有用户、会员机制 (2)方案二:把文件名用一些时间戳+IP等来唯一标识一个文件 3、文件名是字符串类型,而文件内容不一定,可能纯文本文件,可能是其他任意类型的文件, 那么如何区分接收的数据,是文件名还是文件的内容。 可以使用DataInputStream或ObjectInputStream 因为它们有 String readUTF(),也支持 int read(byte[] data) */ BufferedOutputStream bos = null; ObjectInputStream dis = null; PrintStream ps = null; try { dis = new ObjectInputStream(socket.getInputStream()); ps = new PrintStream(socket.getOutputStream()); //接收文件名 String fileName = dis.readUTF(); // String ext = fileName.substring(fileName.lastIndexOf(".")); String newFileName = System.currentTimeMillis() + "&" + socket.getInetAddress().getHostAddress() + "&" + fileName; bos = new BufferedOutputStream(new FileOutputStream(new File("upload", newFileName))); //接收文件内容 byte[] data = new byte[1024]; int len; while((len=dis.read(data)) != -1){//只有客户端关闭才会发送-1,因为下面服务端还需要向客户端发送数据,所以只能在客户端通过shutdownOutput关闭输出通道,保留输入通道。因此这个流的打开就不能写在try()括号中,因为其是在代码执行完后自动关闭的,而TCP协议需要执行“四次挥手”,而此时流已经被自动关闭,所以会报错。 bos.write(data,0,len); } bos.flush(); //也可以给客户端反馈消息,说接收完毕 ps.println(fileName + "接收完毕"); }catch (Exception e){ e.printStackTrace(); }finally{ try { bos.close(); dis.close(); ps.close(); socket.close(); } catch (IOException e) {//粗糙一点关闭 e.printStackTrace(); } } } } public class Client { public static void main(String[] args) { Socket socket = null; ObjectOutputStream oos = null; BufferedReader br = null; BufferedInputStream bis = null; try { socket = new Socket(InetAddress.getLocalHost(),8888); //给服务器发送文件名和文件内容 oos = new ObjectOutputStream(socket.getOutputStream()); //接收服务器反馈的结果 br = new BufferedReader(new InputStreamReader(socket.getInputStream())); //指定要上传的文件 Scanner input = new Scanner(System.in); System.out.print("请输入要上传的文件路径:"); String filePath = input.nextLine(); File file = new File(filePath); //从本地文件读取文件内容 bis = new BufferedInputStream( new FileInputStream(file)); //分开发送文件名和文件内容 //先发送文件名 oos.writeUTF(file.getName()); //发送文件内容 byte[] data = new byte[1024]; int len; while ((len = bis.read(data)) != -1) { oos.write(data, 0, len); } oos.flush();//刷新缓冲区,因为要关闭输出通道了,关闭之后close时,无法刷新 socket.shutdownOutput();//关闭输出通道,对方才能读取到-1标识 System.out.println(br.readLine()); }catch(Exception e){ e.printStackTrace(); }finally{ try { bis.close(); oos.close(); br.close(); socket.close(); } catch (IOException e) {//粗糙一点关闭 e.printStackTrace(); } } } }
java8新特性
Lambda表达式
- 面向对象与函数式编程思想:
面向对象的思想:做一件事情,找一个能解决这个事情的对象,调用对象的方法,完成事情。
- 函数式编程思想:只要能获取到结果,谁去做的,怎么做的都不重要,重视的是结果,不重视过程。
函数接口(SAM)
概念:Single Abstract Method,即接口中只有一个抽象方法需要实现,使用@FunctionalInterface注解来规范接口。若一个方法的形参是SAM类型,那么传递对应形式匹配的lambda表达式即可。
java常见的SAM接口 (1)java.util.Comparator<T> int compare(T t1 ,T t2) (2)java.lang.Runnable void run() (3)java.util.function.Predicate boolean test()(这个其实也是新的) (4)java.io.FileFilter boolean accept(File pathname)函数式接口分类
消费型接口: 有一个参数,无返回值。有去无回,纯消费行为。
接口名 抽象方法 描述 Consumer<T> void accept(T t) 接收一个对象用于完成功能 BiConsumer<T,U> void accept(T t, U u) 接收两个对象用于完成功能 DoubleConsumer void accept(double value) 接收一个double值 IntConsumer void accept(int value) 接收一个int值 LongConsumer void accept(long value) 接收一个long值 ObjDoubleConsumer<T> void accept(T t, double value) 接收一个对象和一个double值 ObjIntConsumer<T> void accept(T t, int value) 接收一个对象和一个int值 ObjLongConsumer<T> void accept(T t, long value) 接收一个对象和一个long值 JDK1.8 java.lang.Iterable接口增加了一个默认方法:public default void forEach(Consumer<? super T> action) 而Collection接口继承了Iterable接口,意味着所有的Collection系列的集合都有这个方法。即其foreach都可以通过lambda表达式完成。
javaeg: @Test public void test02(){ ArrayList<String> arr1=new ArrayList<>(); arr1.add("hello"); arr1.add("world"); arr1.add("hello"); arr1.add("java"); arr1.forEach(s-> System.out.println(s)); }
供给型接口代表/奉献型接口代表:没有参数,有返回值。无去有回,纯供给行为。
接口名 抽象方法 描述 Supplier<T> T get() 返回一个对象 BooleanSupplier boolean getAsBoolean() 返回一个boolean值 DoubleSupplier double getAsDouble() 返回一个double值 IntSupplier int getAsInt() 返回一个int值 LongSupplier long getAsLong() 返回一个long值 javaeg1:()->""返回的是supplier类型,通过get方法,可以得到其内部的值 public void test03(){ Supplier<String> s1=()->"张三"; System.out.println(s1.get()); } eg2:generate:产生无限个数,该数由supplier提供,因为返回类型为supplier,所以使用foreach遍历 @Test public void test04(){ Stream.generate(()-> Math.random()).forEach(d-> System.out.println(d)); }判断型接口,断定型接口代表: 有一个参数,返回值类型是固定的boolean。
接口名 抽象方法 描述 Predicate<T> boolean test(T t) 接收一个对象 BiPredicate<T,U> boolean test(T t, U u) 接收两个对象 DoublePredicate boolean test(double value) 接收一个double值 IntPredicate boolean test(int value) 接收一个int值 LongPredicate boolean test(long value) 接收一个long值 java@Test public void test02(){ ArrayList<String> arr1=new ArrayList<>(); arr1.add("hello"); arr1.add("world"); arr1.add("hello"); arr1.add("java"); arr1.removeIf((String s1)->{return s1.contains("o");}); arr1.forEach((s1)-> System.out.println(s1)); arr1.removeIf(s1->s1.contains("o")); arr1.forEach((s1)-> System.out.println(s1)); }功能型接口代表:有一个参数,有一个返回值。相当于礼尚往来
接口名 抽象方法 描述 Function<T,R> R apply(T t) 接收一个T类型对象,返回一个R类型对象结果 UnaryOperator<T> T apply(T t) 接收一个T类型对象,返回一个T类型对象结果 DoubleFunction<R> R apply(double value) 接收一个double值,返回一个R类型对象 IntFunction<R> R apply(int value) 接收一个int值,返回一个R类型对象 LongFunction<R> R apply(long value) 接收一个long值,返回一个R类型对象 ToDoubleFunction<T> double applyAsDouble(T value) 接收一个T类型对象,返回一个double ToIntFunction<T> int applyAsInt(T value) 接收一个T类型对象,返回一个int ToLongFunction<T> long applyAsLong(T value) 接收一个T类型对象,返回一个long DoubleToIntFunction int applyAsInt(double value) 接收一个double值,返回一个int结果 DoubleToLongFunction long applyAsLong(double value) 接收一个double值,返回一个long结果 IntToDoubleFunction double applyAsDouble(int value) 接收一个int值,返回一个double结果 IntToLongFunction long applyAsLong(int value) 接收一个int值,返回一个long结果 LongToDoubleFunction double applyAsDouble(long value) 接收一个long值,返回一个double结果 LongToIntFunction int applyAsInt(long value) 接收一个long值,返回一个int结果 DoubleUnaryOperator double applyAsDouble(double operand) 接收一个double值,返回一个double IntUnaryOperator int applyAsInt(int operand) 接收一个int值,返回一个int结果 LongUnaryOperator long applyAsLong(long operand) 接收一个long值,返回一个long结果 BiFunction<T,U,R> R apply(T t, U u) 接收一个T类型和一个U类型对象,返回一个R类型对象结果 BinaryOperator<T> T apply(T t, T u) 接收两个T类型对象,返回一个T类型对象结果 ToDoubleBiFunction<T,U> double applyAsDouble(T t, U u) 接收一个T类型和一个U类型对象,返回一个double ToIntBiFunction<T,U> int applyAsInt(T t, U u) 接收一个T类型和一个U类型对象,返回一个int ToLongBiFunction<T,U> long applyAsLong(T t, U u) 接收一个T类型和一个U类型对象,返回一个long DoubleBinaryOperator double applyAsDouble(double left, double right) 接收两个double值,返回一个double结果 IntBinaryOperator int applyAsInt(int left, int right) 接收两个int值,返回一个int结果 LongBinaryOperator long applyAsLong(long left, long right) 接收两个long值,返回一个long结果 java使用Lambda表达式,给一个Function接口的变量赋值,完成给某个字符串的首字母转为大写。 (1) 把字符串的首字母拿出来,转为大写 (2) 把转换后的首字母 拼接上原来字符串除了首字母的部分【java字符串替换 一般使用substring() 和replace()方法组合使用达到精确替换的目的】 @Test public void test05(){ //Function<String,String> fun=(String s)->Character.toUpperCase(s.charAt(0))+s.substring(1); Function<String,String> fun=s->Character.toUpperCase(s.charAt(0))+s.substring(1); System.out.println(fun.apply("hello")); } /* JDK1.8中Map接口新增了一个方法:default void replaceAll(BiFunction<? super K,? super V,? extends V> function) BiFunction<T,U,R>函数式接口, 它的抽象方法 R apply(T t, U u) 有2个参数,一个返回值。 */ @Test public void test06(){ Map<Integer,String> s1=new HashMap<>(); s1.put(5,"Hello"); s1.put(6,"world"); s1.replaceAll((Integer a1,String a2)->a2.toUpperCase()); System.out.println(s1); } IntBinaryOperator intBinaryOperator = (int o1, int o2) -> o1 + o2; System.out.println(intBinaryOperator.applyAsInt(7, 8));
lambda达式的使用
语法格式:(形参列表) -> {Lambda体}
- (形参列表) :是函数式接口的抽象方法的形参列表
- ->:称为Lambda操作符,中间不能有空格
- {Lambda体}:就是函数式接口的抽象方法的方法体。
语法简化:
当{Lambda体}里面只有一个语句时,那么可以省略{},同时省略{}里面的;如果此时这个语句是一个return语句,那么要连同return一起省略。
当(形参列表)的形参类型是已知的,或者可以自动推断的,那么形参列表的类型可以省略,如果此时省略了形参的数据类型之后,只剩下一个形参,它是这样的(形参名),那么此时()也可以省略。
javaeg:Arrays.sort(arr, (o1, o2) -> o1.compareToIgnoreCase(o2)); list.removeIf(s -> s.contains("o")); Arrays.sort(arr,String::compareToIgnoreCase);
练习
1、案例:创建一个ArrayList,并添加26个小写字母到list中,并使用forEach遍历输出
void forEach(Consumer<? super E> action)
Consumer接口的抽象方法:它是一个函数式接口,就可以使用lambda表达式
抽象方法:void accept(T t),对于函数式接口的抽象方法,用lambda表达式给他赋值时,不关心方法名,关心形参列表和返回值类型
java@Test public void test07(){ ArrayList<Character> arr=new ArrayList<>(); for(char i='a';i<='z';i++){ arr.add(i); } arr.forEach(ch-> System.out.println(ch)); }
方法引用
作用:用于简化Lambda表达式的语法,编译器可以智能辅助lambda表达式化简为方法引用方式。
语法格式:类名 :: 方法名或者对象名 :: 方法名。
化简要求:
Lambda体只有一个语句,并且这个语句是通过调用一个现有的类或对象的方法来完成的。并且在调用方法时,所使用的实参正好是Lambda表达式的形参,整个使用过程中,没有额外的数据出现。
java//调用静态类的方法 list.forEach(System.out::println);//方法引用 Stream.generate(Math::random).forEach(System.out::println); //调用对象的方法 Person person=new Person(); list.foreach(person::toString); //此处的String替代的是第一个参数 Arrays.sort((o1,o2)->o1.compareTo(o2)); Arrays.sort(arr,String::compareToIgnoreCase);//会自动匹配所需的参数
构造器引用
java当Lambda体是一个new表达式,而且 所有构造器的实参,都是Lambda表达式的形参,那么此时就可以使用构造器引用。 public static void main(String[] args) { //Function<String,Student> fun=s->new Student(s); Function<String,Student> fun=Student::new; Student stu=fun.apply("张三"); System.out.println(stu.toString()); }数组构造引用
java/*当Lambda表达式是创建一个数组对象,并且满足Lambda表达式形参,正好是给创建这个数组对象的长度,就可以数组构造引用:*/ public void test01(){ //Function<Integer,String[]> fun=(s)->new String[s]; Function<Integer,String[]> fun=String[]::new; String[] apply = fun.apply(5); System.out.println(apply.length); }
Stream类
概述:
- 定义:指用于数据“加工”的一套流程。例如:数据的过滤、数据的统计、数据的迭代、数据的修改、删除、查询筛选等。stream本身是不存储数据的,存储数据的是数组、集合这样的容器。
- 特点:
- stream本身是不存储数据的
- stream每一次加工处理都会产生一个新的stream对象
- stream的中间处理/加工操作会被延迟,一直要到最后取结果的“终结操作”才会执行。
- stream的加工处理不会改变的数据源(集合和数组的元素个数等)
- 使用步骤:
- 创建Stream。
- 中间加工处理:【返回值结果仍然是stream类型】
- 终结操作。【返回值结果就不再是stream类型。表示之后无法再进行流处理】
方法:
创建方法
集合对象.stream
获得对应集合的流,JDK1.8在Collection系列集合中增加了方法:default Stream<E> stream()
javaStream<String> stream = list.stream();
数组工具类Arrays.stream方法
获取对应的数组流,需要传入数组参数
javaint[] arr = {1,2,3,4,5}; IntStream stream = Arrays.stream(arr);
通过Stream流自带的方法
static<T> Stream<T> of(T... values):有限流
static <T> Stream<T> generate(Supplier<T> s):无限流,产生数据
static <T> Stream<T> iterate(T seed, UnaryOperator<T> f):无限流,迭代数据
javaUnaryOperator:public interface UnaryOperator<T> extends Function<T, T> ,说明它是功能型的函数式接口的变形。参数的类型和返回值的是一样的。 作用:对每一个元素,进行迭代处理,从第一个元素开始,每次迭代都+2,然后一直在上一次的基础上,不断迭代。流中的数据,第一个是seed(种子),它的值是1 eg:Stream<Integer> stream = Stream.iterate(1, t -> t + 2); stream = stream.peek(t->{ try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } }); stream.forEach(System.out::println);
加工处理方法:存在:Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6, 7,2,3,5, 8);
filter(Predicate p):接收 Lambda,从流中排除某些元素,满足条件保留
java//integerStream.filter(s->s%2==0).forEach(s-> System.out.println(s)); //2 4 6 2 8distinct() 筛选:通过流所生成元素的equals() 方法去除重复元素
java//integerStream.distinct().forEach(s-> System.out.println(s)); //1 2 3 4 5 6 7 8limit(long maxSize) 截断流:使其元素不超过给定数量
skip(long n) 跳过元素:返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补
java//integerStream.skip(3).limit(5).forEach(System.out::println); //输出结果: 4, 5, 6, 7,2peek(Consumer action) :接收Lambda,对流中的每个数据执行Lambda体操作
java//integerStream.peek(s->s=s+2).forEach(System.out::println); //输出结果不会发生改变,因为传过去的是包装类,包装类值发生改变就指向了新地址,而原地址数据不会发生改变。String同理sorted()排序:产生一个新流,其中按自然顺序排序
java//integerStream.sorted().forEach(System.out::println); //1 2 2 3 3 4 5 5 6 7 8sorted(Comparator com) 产生一个新流,其中按比较器顺序排序
javaStream<String> str = Stream.of("张三", "李四", "王五"); str.sorted((x,y)->{ return Collator.getInstance(Locale.CHINA).compare(x,y); }).forEach(System.out::println); 李四、王五、张三map(Function f) :接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。和peek不一样,map中接受的是函数,有返回值,故会改变包装类;而peek是消费型接口,无返回值,故不会改变包装类。
java//integerStream.map(s->s+=2).forEach(System.out::println); //3 4 5 6 7 8 9 4 5 7 10mapToDouble(ToDoubleFunction f) 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream
mapToInt(ToIntFunction f) 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream
mapToLong(ToLongFunction f) 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream
flatMap(Function f):接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个
java//每一个元素都会换成一个新的流,最终输出结果为每行一个字母 public void test12(){ Stream.of("hello", "world", "java") //.flatMap(t -> t.toCharArray())//错误,因为toCharArray方法的结果是char[],不是一个Stream .flatMap(t -> { char[] chars = t.toCharArray(); Character[] arr = new Character[chars.length]; for(int i=0; i<chars.length; i++){ arr[i] = chars[i]; } return Arrays.stream(arr);//将元素之一arr当做一个新的流返回 }) .forEach(System.out::println); }
终结方法
boolean allMatch(Predicate p) :检查是否匹配所有元素
boolean anyMatch(Predicate p):检查是否至少匹配一个元素
boolean noneMatch(Predicate p):检查是否没有匹配所有元素
Optional<T> findFirst():返回第一个元素
Optional<T> findAny() :返回当前流中的任意元素
long count():返回流中元素总数
Optional<T> max(Comparator c):返回流中最大值
Optional<T> min(Comparator c):返回流中最小值
void forEach(Consumer c):迭代
T reduce(T iden, BinaryOperator b):可以将流中元素反复结合起来,得到一个值。返回 T ,iden是初始值
Optional<T> reduce(BinaryOperator b):可以将流中元素反复结合起来,得到一个值。返回 Optional<T>
java/*Optional<Integer> result = Stream.of(1, 2, 3, 4, 5,0) .reduce((t1, t2) -> t1>t2?t1:t2);//对于t1和t2两个元素,按规则一个元素,一次类推,直到只剩下一个 System.out.println("result = " + result);*/ 1和2比,剩2 2和3比,剩3 3和4比,剩4 4和5比,剩5 result的值为5R collect(Collector c) : 将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
javaCollector 接口中方法的实现决定了如何对流执行收集的操作(如收集到 List、Set、Map)。 另外, Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例。 //转化为集合,to系列 public static <T, C extends Collection<T>>Collector<T, ?, C> toCollection(Supplier<C> collectionFactory) //字符串拼接,join系列 //delimiter:拼接字符串中间的分隔符,prefix:拼接完后添加的前缀,suffix:拼接完后添加的后缀。 public static Collector<CharSequence, ?, String> joining() //joining(CharSequence delimiter,CharSequence prefix,CharSequence suffix) //joining(CharSequence delimiter) //对于每一个输入元素,它首先使用mapper进行映射,然后将映射的结果提供给downstream收集器进行收集 Collector<T, ?, R> mapping(Function<? super T, ? extends U> mapper,Collector<? super U, A, R> downstream) /*将每个字符串转换为大写,然后收集到一个新的列表中 List<String> words = Arrays.asList("Hello", "World", "Java"); List<String> upperCaseWords = words.stream().collect(Collectors.mapping(String::toUpperCase, Collectors.toList())); */ //这个方法与mapping类似,但是它的映射函数mapper生成的是一个Stream,而不是一个单一的值。这个Stream中的每一个元素都会被提供给downstream收集器进行收集。 flatMapping(Function<? super T, ? extends Stream<? extends U>> mapper, Collector<? super U, A, R> downstream) /*将每个字符串分割成单词,然后收集所有的单词到一个新的列表中 List<String> lines = Arrays.asList("Hello,World", "Java,Stream"); List<String> words = lines.stream() .collect(Collectors.flatMapping(line -> Arrays.stream(line.split(",")), Collectors.toList())); */ //只有当测试结果为true时,才会将元素提供给downstream收集器进行收集。这个方法通常用于在收集元素之前对元素进行过滤。 filtering(Predicate<? super T> predicate, Collector<? super T, A, R> downstream) //使用downstream收集器对输入元素进行收集,然后将收集的结果提供给finisher进行最后的转换。这个方法通常用于在收集完元素之后对结果进行一些额外的处理。 collectingAndThen(Collector<T,A,R> downstream, Function<R,RR> finisher) /*计算这些整数的和,然后将结果乘以2 List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); int doubleSum = numbers.stream() .collect(Collectors.collectingAndThen(Collectors.summingInt(Integer::intValue), sum -> sum * 2)); */ //接收一个ToLongFunction类型的参数mapper,这个函数会被应用到输入元素上,生成一个长整型值。然后,这个Collector会计算这些值的和。 summingLong(ToLongFunction<? super T> mapper) //这个方法返回的是一个收集器,该收集器将输入元素映射为 long,然后计算这些 long 值的统计信息,包括总和、平均值、最大值、最小值和数量。返回的结果是一个 LongSummaryStatistics 对象,该对象包含了这些统计信息。 summarizingLong(ToLongFunction<? super T> mapper) //接收一个ToIntFunction类型的参数mapper,这个函数会被应用到输入元素上,生成一个长整型值。然后,这个Collector会计算这些值的平均值。 averagingInt(ToIntFunction<? super T> mapper) //找出最大、最小元素 minBy/maxBy(Comparator<? super T> comparator) //迭代二元操作,identity为初始值,map为映射函数,接受一个值,返回一个值,op为迭代操作 reducing(BinaryOperator<T> op) reducing(T identity, BinaryOperator<T> op) reducing(U identity,Function<? super T, ? extends U> mapper,BinaryOperator<U> op) /* 获取Person的年龄之和 int totalAge = people.collect(Collectors.reducing( 0, Person::getAge, Integer::sum )); */ //将输入元素映射到某个键类型K。收集器产生一个Map<K, List<T>>,其键是将分类函数应用于输入元素得到的值,对应的值是将输入元素映射到关联键下的List。 groupingByConcurrent/groupingBy(Function<? super T, ? extends K> classifier) //在第一种方法的基础上,增加了一个下游收集器,用于对每个分组的元素进行进一步的归约操作。收集器产生一个Map<K, D>,其键是将分类函数应用于输入元素得到的值,对应的值是将下游收集器应用于每个分组得到的结果。 groupingByConcurrent/groupingBy(Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream) //增加了一个mapFactory,用于提供一个新的空Map,结果将插入其中。这允许用户控制结果Map的类型。 groupingByConcurrent/groupingBy(Function<? super T, ? extends K> classifier, Supplier<M> mapFactory, Collector<? super T, A, D> downstream) /* 根据getCity分组,结果存入TreeMap,summingInt对分组后的结果进行求和 TreeMap<City, Integer> populationByCity = people.collect(Collectors.groupingBy( Person::getCity, TreeMap::new, Collectors.summingInt(Person::getPopulation) )); */ //将输入元素映射到一个布尔值。收集器产生一个Map<Boolean, List<T>>,其键是将谓词函数应用于输入元素得到的值(true或false),对应的值是将输入元素映射到关联键下的List。 partitioningBy(Predicate<? super T> predicate) //在第一种方法的基础上,增加了一个下游收集器,用于对每个分区的元素进行进一步的归约操作。收集器产生一个Map<Boolean, D>,其键是将谓词函数应用于输入元素得到的值,对应的值是将下游收集器应用于每个分区得到的结果。 partitioningBy(Predicate<? super T> predicate, Collector<? super T, A, D> downstream) /* 谓词函数是Person::isAdult(将每个人映射到他们是否成年),下游收集器是Collectors.summingInt(Person::getPopulation)(计算每个分区的人口总数) Map<Boolean, Integer> populationByAge = people.collect(Collectors.partitioningBy( Person::isAdult, Collectors.summingInt(Person::getPopulation) )); */
Optional类
作用:Java很多方法的返回值或形参是引用数据类型时,返回null。引入了Optional类来尽量的降低空指针异常的风险,又可以简化判空代码。
特点:它是一个只包含一个对象的容器
创建:
- static <T> Optional<T> empty():得到一个空的容器对象,里面没有元素,容器对象有。
- static <T> Optional<T> of(T value) :得到一个包含元素的容器对象,里面一定有元素,而且非null。
- static <T> Optional<T> ofNullable(T value) :得到一个包含元素的容器对象,里面一定有元素,元素可以是非null。可以是null。
使用:
T get():要求容器中必须有一个非空对象,并获取该对象
T orElse(T other) :如果容器中有非空对象,就取容器中非空对象,如果没有,就用other备胎。
T orElseGet(Supplier<? extends T> other):如果容器中有非空对象,就取容器中非空对象,如果没有,就用Supplier供给型接口提供的对象代替。
<X extends Throwable> T orElseThrow(Supplier<? extends X> exceptionSupplier) :如果容器中有非空对象,就取容器中非空对象,如果没有,就报一个你定义的异常
boolean isPresent() :判断容器中有没有元素
void ifPresent(Consumer<? super T> consumer) :如果存在就执行xx代码
<U> Optional<U> map(Function<? super T,? extends U> mapper) :判断Optional容器中的值是否存在,如果有值,则对其执行调用映射函数得到返回值。如果返回值不为 null,则创建包含映射返回值的Optional作为map方法返回值,否则返回空Optional。
flatMap(Function<? super T, Optional<U>> mapper):这个方法也接受一个 Function 参数,这个函数对 Optional 实例的值进行计算,并返回一个 Optional 实例。flatMap 方法的不同之处在于,它会“平铺”函数的返回值,也就是说,它会移除结果中的 Optional 层次。这对于避免嵌套的 Optional 实例非常有用
javaOptional<String> optional = Optional.of("Hello"); Optional<Optional<Integer>> nestedOptional = optional.map(s -> Optional.of(s.length())); Optional<Integer> flatOptional = optional.flatMap(s -> Optional.of(s.length()));public Optional<T> filter(Predicate<? super T> predicate):如果值存在,并且这个值匹配给定的 predicate,返回一个Optional用以描述这个值,否则返回一个空的Optional。
javaos1.filter(p -> p.getName().equals("张三")).ifPresent(x -> System.out.println("OK"));使用方式
javaOptional.ofNullable(comp) // 使用map方法对Optional对象中的comp对象进行操作,获取其结果,如果comp为null,则返回一个空的Optional对象 .map(Competition::getResult) // 相当于c -> c.getResult(),如果Competition对象为空,返回空Optional,否则返回包含结果的Optional // 对上一步返回的Optional对象进行操作,获取其冠军信息,如果上一步返回的Optional对象为空,则返回一个空的Optional对象 .map(CompResult::getChampion) // 如果CompResult对象为空,返回空Optional,否则返回包含冠军信息的Optional // 对上一步返回的Optional对象进行操作,获取冠军的名字,如果上一步返回的Optional对象为空,则返回一个空的Optional对象 .map(User::getName) // 如果User对象为空,返回空Optional,否则返回包含冠军名字的Optional // 如果最终的Optional对象为空,即没有获取到冠军的名字,那么抛出一个异常,否则返回冠军的名字 .orElseThrow(()->new IllegalArgumentException("The value of param comp isn't available.")); //类型转换 //如果x存在返回map转换的值,如果x不存在,返回orElse中的值 int timeout = Optional.ofNullable(redisProperties.getTimeout()) .map(x -> Long.valueOf(x.toMillis()).intValue()) .orElse(10000); Boolean isLogin = Optional.ofNullable(authentication) .map(auth -> !authentication.getPrincipal().equals("anonymousUser") && authentication.isAuthenticated()) .orElse(false);
JVM
概述
结构图
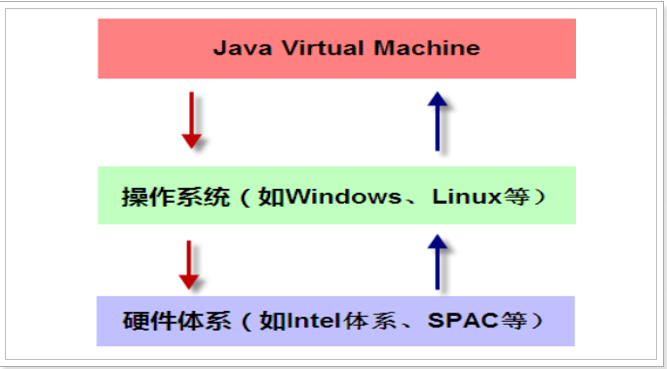
方法区:存储已被虚拟机加载的类元数据信息(元空间)
堆:存放对象实例,几乎所有的对象实例都在这里分配内存
虚拟机栈(java栈):虚拟机栈描述的是Java方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等信息
程序计数器:当前线程所执行的字节码的行号指示器
本地方法栈:本地方法栈则是为虚拟机使用到的Native方法服务。
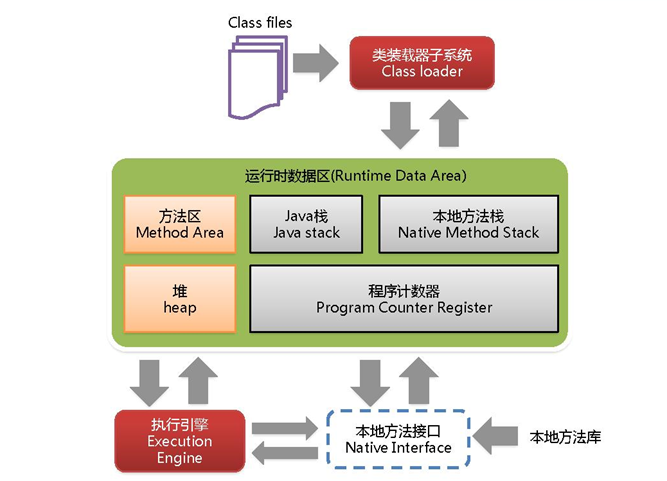
类加载器ClassLoader
负责加载class文件,class文件在文件开头有特定的文件标示,并且ClassLoader只负责class文件的加载,至于它是否可以运行,则由Execution Engine决定。
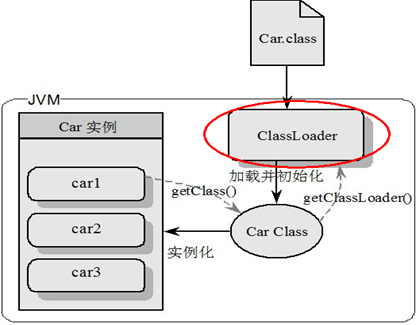
类加载器分为四种:前三种为虚拟机自带的加载器。
启动类加载器(Bootstrap)C++
负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类
扩展类加载器(Extension)Java
负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的jar包
应用程序类加载器(AppClassLoader)Java
也叫系统类加载器,负责加载classpath(java.class.path)中指定的jar包及目录中class
用户自定义加载器 Java.lang.ClassLoader的子类,用户可以定制类的加载方式
工作过程:
- 1、当AppClassLoader加载一个class时,它首先不会自己去尝试加载这个类,而是把类加载请求委派给父类加载器ExtClassLoader去完成。
- 2、当ExtClassLoader加载一个class时,它首先也不会自己去尝试加载这个类,而是把类加载请求委派给BootStrapClassLoader去完成。
- 3、如果BootStrapClassLoader加载失败(例如在$JAVA_HOME/jre/lib里未查找到该class),会使用ExtClassLoader来尝试加载;
- 4、若ExtClassLoader也加载失败,则会使用AppClassLoader来加载
- 5、如果AppClassLoader也加载失败,则会报出异常ClassNotFoundException
其实这就是所谓的双亲委派模型。简单来说:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把请求委托给父加载器去完成,依次向上。
为什么要设计双亲委派机制?
沙箱安全机制:自己写的java.lang.String.class类不会被加载,这样便可以防止核心API库被随意篡改
避免类的重复加载:当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次,保证被加载类的唯一性
AppClassLoader加载类的双亲委派机制源码:
//AppClassLoader的loadClass方法,里面实现了双亲委派机制
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 检查当前类加载器是否已经加载了该类
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
//如果当前加载器父加载器不为空则委托父加载器加载该类
if (parent != null) {
c = parent.loadClass(name, false);
} else {
//如果当前加载器父加载器为空则委托引导类加载器加载该类
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non‐null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
//都会调用URLClassLoader的findClass方法在加载器的类路径里查找并加载该类
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 ‐ t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}执行引擎Execution Engine
Execution Engine执行引擎负责解释命令,提交操作系统执行。
本地接口Native Interface
本地接口的作用是融合不同的编程语言为 Java 所用,它的初衷是融合 C/C++程序,Java 诞生的时候是 C/C++横行的时候,要想立足,必须有调用 C/C++程序,于是就在内存中专门开辟了一块区域处理标记为native的代码,它的具体做法是 Native Method Stack中登记 native方法,在Execution Engine 执行时加载native libraies。
目前该方法使用的越来越少了,除非是与硬件有关的应用,比如通过Java程序驱动打印机或者Java系统管理生产设备,在企业级应用中已经比较少见。因为现在的异构领域间的通信很发达,比如可以使用 Socket通信,也可以使用Web Service等等,不多做介绍。
Native Method Stack
它的具体做法是Native Method Stack中登记native方法,在Execution Engine 执行时加载本地方法库。
PC寄存器(程序计数器)
每个线程都有一个程序计数器,是线程私有的,就是一个指针,指向方法区中的方法字节码(用来存储指向下一条指令的地址,即 将要执行的指令代码),由执行引擎读取下一条指令,是一个非常小的内存空间,几乎可以忽略不记。
Method Area方法区
方法区是被所有线程共享,所有字段和方法字节码,以及一些特殊方法如构造函数,接口代码也在此定义。简单说,所有定义的方法的信息都保存在该区域,此区属于共享区间。
静态变量+常量+类信息(构造方法/接口定义)+运行时常量池存在方法区中。而实例变量存在堆内存中,和方法区无关
stack栈
概述
栈也叫栈内存,主管Java程序的运行,是在线程创建时创建,它的生命期是跟随线程的生命期,线程结束栈内存也就释放,对于栈来说不存在垃圾回收问题,只要线程一结束该栈就Over,生命周期和线程一致,是线程私有的。8种基本类型的变量+对象的引用变量+实例方法都是在函数的栈内存中分配。(JDK1.5以后每个线程栈默认大小1M)
栈存储内容
栈中的数据都是以栈帧(Stack Frame)的格式存在,栈帧是一个内存区块,是一个数据集,是一个有关方法(Method)和运行期数据的数据集。
栈帧中主要保存3 类数据:
本地变量(Local Variables):输入参数和输出参数以及方法内的变量。
栈操作(Operand Stack):记录出栈、入栈的操作。
栈帧数据(Frame Data):包括类文件、方法等等。
栈运行原理:
当一个方法A被调用时就产生了一个栈帧 F1,并被压入到栈中,
A方法又调用了 B方法,于是产生栈帧 F2 也被压入栈,
B方法又调用了 C方法,于是产生栈帧 F3 也被压入栈,
……
执行完毕后,先弹出F3栈帧,再弹出F2栈帧,再弹出F1栈帧……
遵循“先进后出”或者“后进先出”原则。每执行一个方法都会产生一个栈帧,保存到栈(后进先出)的顶部,顶部栈就是当前的方法,该方法执行完毕后会自动将此栈帧出栈。
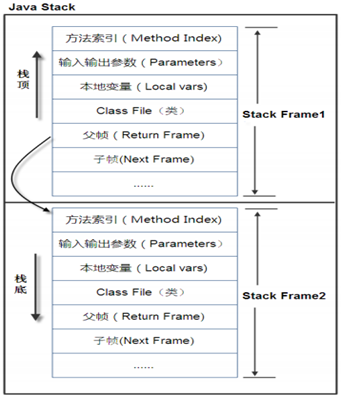
堆
HotSpot是使用指针的方式来访问对象:
Java堆中会存放访问类元数据的地址
reference存储的就是对象的地址
三种JVM:
•Sun公司的HotSpot
•BEA公司的JRockit
•IBM公司的J9 VM
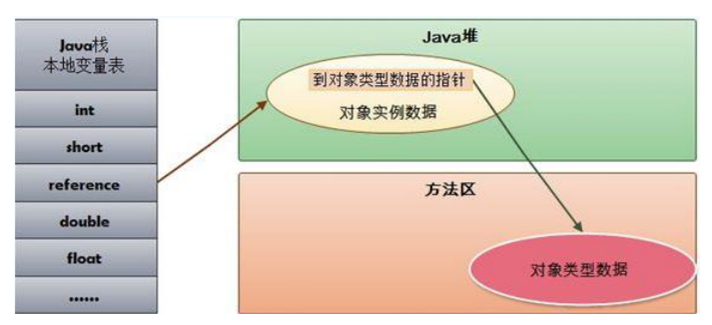
堆体系概述
Heap 堆:一个JVM实例只存在一个堆内存,堆内存的大小是可以调节的。类加载器读取了类文件后,需要把类、方法、常变量放到堆内存中,保存所有引用类型的真实信息,以方便执行器执行,堆内存逻辑上分为三部分:
Young Generation Space 新生区 Young/New
Tenure generation space 养老区 Old/Tenure
Permanent Space 永久区 Perm
也称为:新生代(年轻代)、老年代、永久代(持久代)。
其中JVM堆分为新生代和老年代
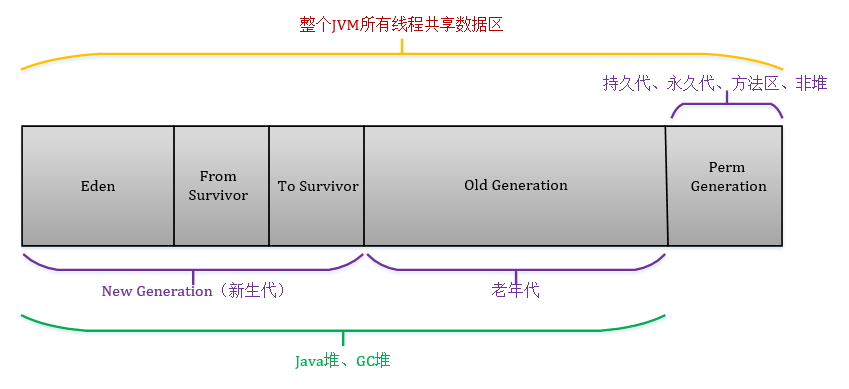
新生区
新生区是对象的诞生、成长、消亡的区域,一个对象在这里产生,应用,最后被垃圾回收器收集,结束生命。新生区又分为两部分: 伊甸区(Eden space)和幸存者区(Survivor pace) ,所有的对象都是在伊甸区被new出来的。幸存区有两个: 0区(Survivor 0 space)和1区(Survivor 1 space)。当伊甸园的空间用完时,程序又需要创建对象,JVM的垃圾回收器将对伊甸园区进行垃圾回收(Minor GC),将伊甸园区中的不再被其他对象所引用的对象进行销毁。然后将伊甸园中的剩余对象移动到幸存 0区。若幸存 0区也满了,再对该区进行垃圾回收,然后移动到 1 区。那如果1 区也满了呢?再次垃圾回收,满足条件后再移动到养老区。若养老区也满了,那么这个时候将产生MajorGC(FullGC),进行养老区的内存清理。<font color='red'>若养老区执行了Full GC之后发现依然无法进行对象的保存,就会产生OOM异常“OutOfMemoryError”。</font>
如果出现<font color='red'>java.lang.OutOfMemoryError: Java heap space</font>异常,说明Java虚拟机的堆内存不够。原因有二:
(1)Java虚拟机的堆内存设置不够,可以通过参数-Xms、-Xmx来调整。
(2)代码中创建了大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)。
老年代
经历多次GC仍然存在的对象(默认是15次),老年代的对象比较稳定,不会频繁的GC
永久代
永久存储区是一个常驻内存区域,用于存放JDK自身所携带的 Class,Interface 的元数据,也就是说它存储的是运行环境必须的类信息,被装载进此区域的数据是不会被垃圾回收器回收掉的,关闭 JVM 才会释放此区域所占用的内存。
如果出现<font color='red'>java.lang.OutOfMemoryError: PermGen space</font>,说明是Java虚拟机对永久代Perm内存设置不够。一般出现这种情况,都是程序启动需要加载大量的第三方jar包。例如:在一个Tomcat下部署了太多的应用。或者大量动态反射生成的类不断被加载,最终导致Perm区被占满。
Jdk1.6及之前: 有永久代,常量池1.6在方法区
Jdk1.7: 有永久代,但已经逐步“去永久代”,常量池1.7在堆
Jdk1.8及之后: 无永久代,常量池1.8在元空间(Metaspace)
实际而言,方法区(Method Area)和堆一样,是各个线程共享的内存区域,它用于存储虚拟机加载的:类信息+普通常量+静态常量+编译器编译后的代码等等,虽然JVM规范将方法区描述为堆的一个逻辑部分,但它却还有一个别名叫做Non-Heap(非堆),目的就是要和堆分开。
对于HotSpot虚拟机,很多开发者习惯将方法区称之为“永久代(Parmanent Gen)” ,但严格本质上说两者不同,或者说使用永久代来实现方法区而已,永久代是方法区(相当于是一个接口interface)的一个实现,jdk1.7的版本中,已经将原本放在永久代的字符串常量池移走。
常量池(Constant Pool)是方法区的一部分,Class文件除了有类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池,这部分内容将在类加载后进入方法区的运行时常量池中存放。
堆参数调优
均以JDK1.8+HotSpot为例
jdk1.7:
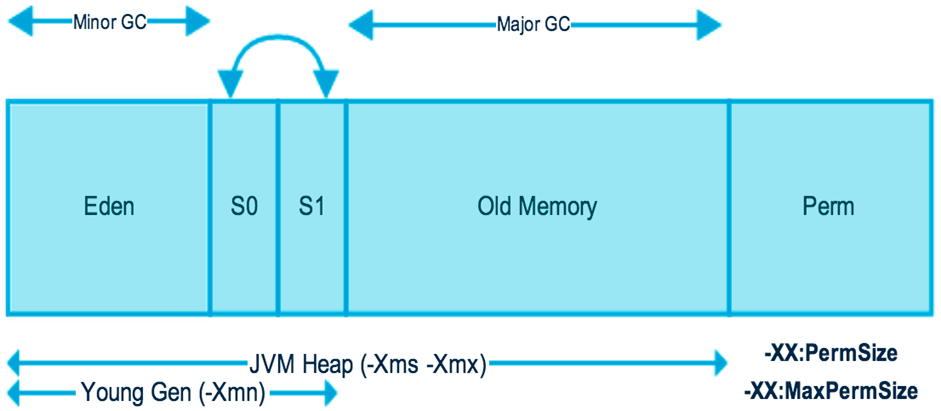
jdk1.8:
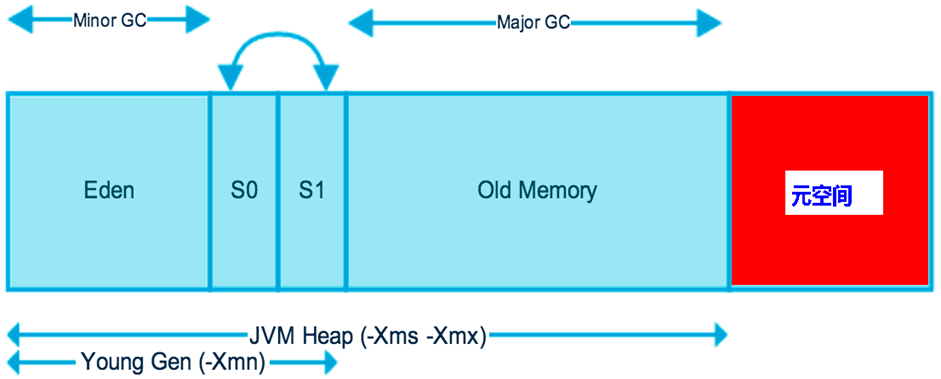
-XX:MetaspaceSize 这个参数是初始化的Metaspace大小
-XX:MaxMetaspceSize 指定元数据区域最大的大小。
常用JVM参数
| 参数 | 备注 |
|---|---|
| -Xms | 初始堆大小。只要启动,就占用的堆大小,默认是内存的1/64 |
| -Xmx | 最大堆大小。默认是内存的1/4 |
| -Xmn | 新生区堆大小 |
| -XX:+PrintGCDetails | 输出详细的GC处理日志 |
java代码查看jvm堆的默认值大小:
Runtime.getRuntime().maxMemory() // 堆的最大值,默认是内存的1/4
Runtime.getRuntime().totalMemory() // 堆的当前总大小,默认是内存的1/64设置JVM参数
命令行运行
java -Xmx50m -Xms10m 项目名idea运行
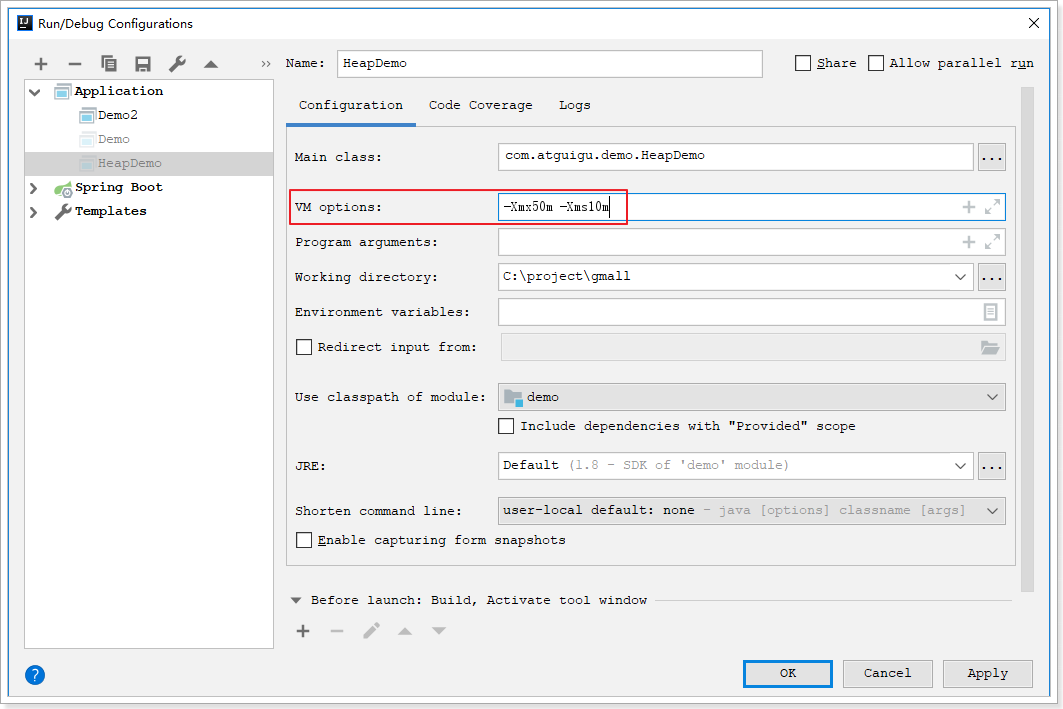
查看堆内存详情
public class Demo2 {
public static void main(String[] args) {
System.out.print("最大堆大小:");
System.out.println(Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M");
System.out.print("当前堆大小:");
System.out.println(Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M");
System.out.println("==================================================");
byte[] b = null;
for (int i = 0; i < 10; i++) {
b = new byte[1 * 1024 * 1024];
}
}
}执行前配置参数:-Xmx50m -Xms30m -XX:+PrintGCDetails
执行:看到如下信息
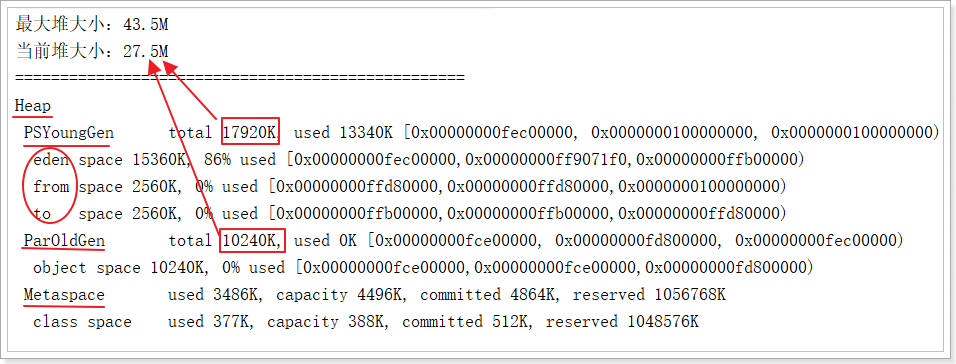
新生代和老年代的堆大小之和是Runtime.getRuntime().totalMemory()
MAT工具
把上例中运行参数改成:
-Xmx50m -Xms10m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=D:\tmp -XX:HeapDumpPath:生成dump文件路径。
再次执行:生成C:\tmp\java_pid20328.hprof文件
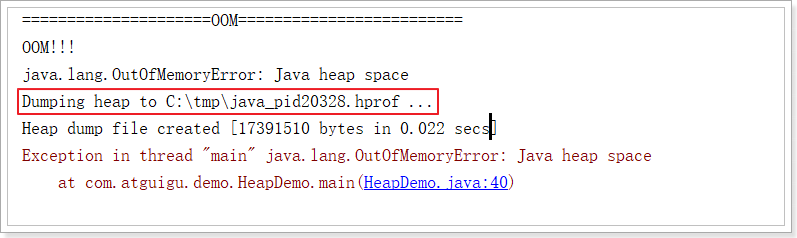
生成的这个文件怎么打开?jdk自带了该类型文件的解读工具:jvisualvm.exe
双击打开:
文件-->装入-->选择要打开的文件即可
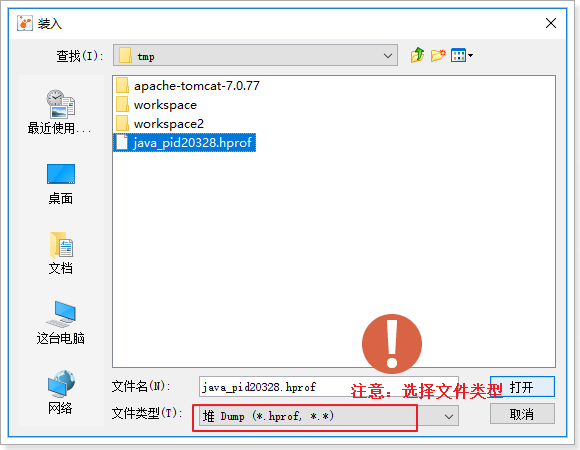
装入后:
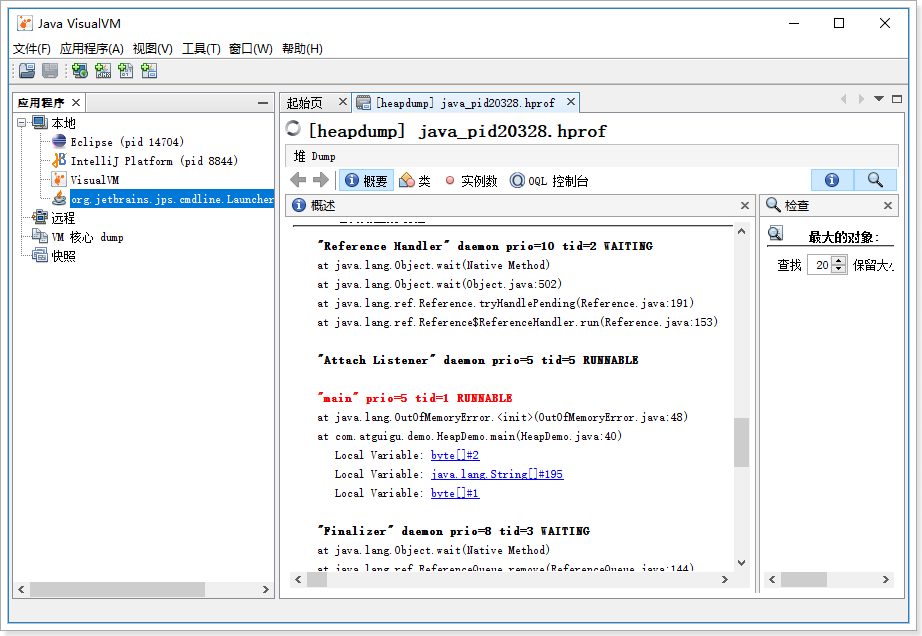
常用命令行(了解)
查看java进程:jps -l
查看某个java进程所有参数:jinfo 进程号
查看某个java进程总结性垃圾回收统计:jstat -gc 进程号
S0C:幸存者0区的大小
S1C:幸存者1区的大小
S0U:幸存者0区的使用大小
S1U:幸存者1区的使用大小
EC:伊甸区的大小
EU:伊甸区的使用大小
OC:老年代大小
OU:老年代使用大小
MC:方法区大小
MU:方法区使用大小
CCSC:压缩类空间大小
CCSU:压缩类空间使用大小
YGC:年轻代垃圾回收次数
YGCT:年轻代垃圾回收消耗时间
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间GC垃圾回收
垃圾判定
引用计数法(Reference-Counting)
引用计数算法是通过判断对象的引用数量来决定对象是否可以被回收。
给对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的。
优点:
- 简单,高效,现在的objective-c、python等用的就是这种算法。
缺点:
引用和去引用伴随着加减算法,影响性能
很难处理循环引用,相互引用的两个对象则无法释放。
因此目前主流的Java虚拟机都摒弃掉了这种算法。
可达性分析算法
这个算法的实质在于将一系列GC Roots作为初始的存活对象合集(live set),然后从该合集出发,探索所有能够被该合集引用到的对象,并将其加入到该和集中,这个过程称之为标记(mark)。 最终,未被探索到的对象便是死亡的,是可以回收的。
在Java语言中,可以作为GC Roots的对象包括下面几种:
- 虚拟机栈(栈帧中的本地变量表)中的引用对象。
- 方法区中的类静态属性引用的对象。
- 方法区中的常量引用的对象。
- 本地方法栈中JNI(Native方法)的引用对象
真正标记以为对象为可回收状态至少要标记两次。
第一次:没有与GC ROOTS相连接。finalize方法被覆盖并且没有调用过,则进入F-Queue队列。这个是在优先级低的finalizer线程执行,不保证等待线程结束。如果其中一个运行太久,其他对象的finalize会一直等待。
第二次:判断第一次标记的对象中,是否还是没有与GC ROOTS连接。如归是则回收,并且不会执行finalize(要么已经在第一次标记时执行,要么没有覆写)
四种引用
平时只会用到强引用和软引用。
强引用:
类似于 Object obj = new Object(); 只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象。
软引用:
SoftReference 类实现软引用。在系统要发生内存溢出异常之前,才会将这些对象列进回收范围之中进行二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。软引用可用来实现内存敏感的高速缓存。
弱引用:
WeakReference 类实现弱引用。对象只能生存到下一次垃圾收集之前。在垃圾收集器工作时,无论内存是否足够都会回收掉只被弱引用关联的对象。
虚引用:
PhantomReference 类实现虚引用。无法通过虚引用获取一个对象的实例,为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。
垃圾回收算法
Stop-the-world意味着 JVM由于要执行GC而停止了应用程序的执行,并且这种情形会在任何一种GC算法中发生。当Stop-the-world发生时,除了GC所需的线程以外,所有线程都处于等待状态直到GC任务完成。事实上,GC优化很多时候就是指减少Stop-the-world发生的时间,从而使系统具有高吞吐 、低停顿的特点。
复制算法(Copying)
该算法将内存平均分成两部分,然后每次只使用其中的一部分,当这部分内存满的时候,将内存中所有存活的对象复制到另一个内存中,然后将之前的内存清空,只使用这部分内存,循环下去。
优点:
- 实现简单
- 不产生内存碎片
缺点:
将内存缩小为原来的一半,浪费了一半的内存空间,代价太高;如果不想浪费一半的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
如果对象的存活率很高,我们可以极端一点,假设是100%存活,那么我们需要将所有对象都复制一遍,并将所有引用地址重置一遍。复制这一工作所花费的时间,在对象存活率达到一定程度时,将会变的不可忽视。 所以从以上描述不难看出,复制算法要想使用,最起码对象的存活率要非常低才行,而且最重要的是,我们必须要克服50%内存的浪费。
年轻代中使用的是Minor GC,这种GC算法采用的是复制算法(Copying)。
HotSpot JVM把年轻代分为了三部分:1个Eden区和2个Survivor区(分别叫from和to)。默认比例为8:1:1,一般情况下,新创建的对象都会被分配到Eden区。因为年轻代中的对象基本都是朝生夕死的(90%以上),所以在年轻代的垃圾回收算法使用的是复制算法。
在GC开始的时候,对象只会存在于Eden区和名为“From”的Survivor区,Survivor区“To”是空的。紧接着进行GC,Eden区中所有存活的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的年龄值来决定去向。对象在Survivor区中每熬过一次Minor GC,年龄就会增加1岁。年龄达到一定值(年龄阈值,可以通过-XX:MaxTenuringThreshold来设置)的对象会被移动到年老代中,没有达到阈值的对象会被复制到“To”区域。<font color='red'>经过这次GC后,Eden区和From区已经被清空。这个时候,“From”和“To”会交换他们的角色,也就是新的“To”就是上次GC前的“From”,新的“From”就是上次GC前的“To”。</font>不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到“To”区被填满,“To”区被填满之后,会将所有对象移动到年老代中。
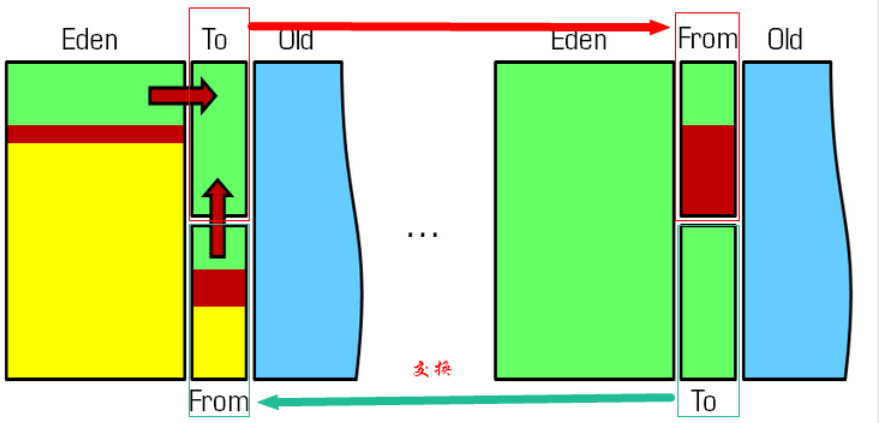
因为Eden区对象一般存活率较低,一般的,使用两块10%的内存作为空闲和活动区间,而另外80%的内存,则是用来给新建对象分配内存的。一旦发生GC,将10%的from活动区间与另外80%中存活的eden对象转移到10%的to空闲区间,接下来,将之前90%的内存全部释放,以此类推。
标记清除(Mark-Sweep)
“标记-清除”(Mark Sweep)算法是几种GC算法中最基础的算法,是因为后续的收集算法都是基于这种思路并对其不足进行改进而得到的。正如名字一样,算法分为2个阶段:
标记出需要回收的对象,使用的标记算法均为可达性分析算法。
回收被标记的对象。
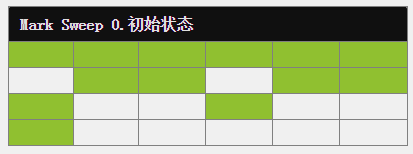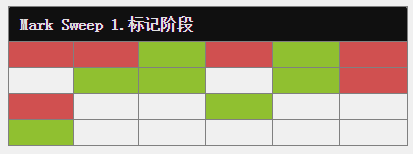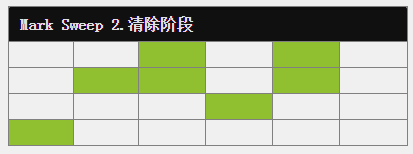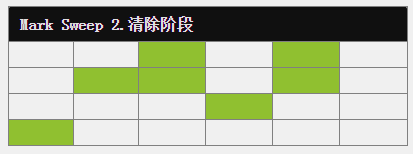
缺点:
效率问题(两次遍历)
空间问题(标记清除后会产生大量不连续的碎片。JVM就不得不维持一个内存的空闲列表,这又是一种开销。而且在分配数组对象的时候,寻找连续的内存空间会不太好找。)
标记压缩(Mark-Compact)
标记-整理法是标记-清除法的一个改进版。同样,在标记阶段,该算法也将所有对象标记为存活和死亡两种状态;不同的是,在第二个阶段,该算法并没有直接对死亡的对象进行清理,而是通过所有存活对像都向一端移动,然后直接清除边界以外的内存。
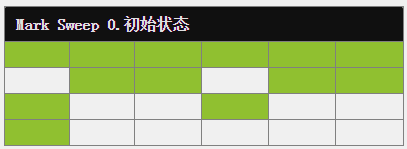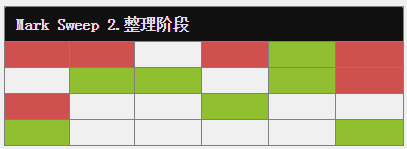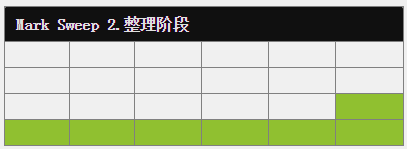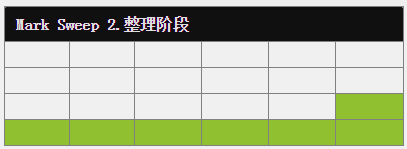
优点:
标记/整理算法不仅可以弥补标记/清除算法当中,内存区域分散的缺点,也消除了复制算法当中,内存减半的高额代价。
缺点:
如果存活的对象过多,整理阶段将会执行较多复制操作,导致算法效率降低。
老年代一般是由标记清除或者是标记清除与标记整理的混合实现。

分代收集算法(Generational-Collection)
内存效率:复制算法>标记清除算法>标记整理算法(此处的效率只是简单的对比时间复杂度,实际情况不一定如此)。 内存整齐度:复制算法>标记整理算法>标记清除算法。 内存利用率:标记整理算法>标记清除算法>复制算法。
可以看出,效率上来说,复制算法是当之无愧的老大,但是却浪费了太多内存,而为了尽量兼顾上面所提到的三个指标,标记/整理算法相对来说更平滑一些,但效率上依然不尽如人意,它比复制算法多了一个标记的阶段,又比标记/清除多了一个整理内存的过程
分代回收算法实际上是把复制算法和标记整理法的结合,并不是真正一个新的算法,一般分为:老年代(Old Generation)和新生代(Young Generation),老年代就是很少垃圾需要进行回收的,新生代就是有很多的内存空间需要回收,所以不同代就采用不同的回收算法,以此来达到高效的回收算法。
年轻代(Young Gen)
年轻代特点是区域相对老年代较小,对像存活率低。
这种情况复制算法的回收整理,速度是最快的。复制算法的效率只和当前存活对像大小有关,因而很适用于年轻代的回收。而复制算法内存利用率不高的问题,通过hotspot中的两个survivor的设计得到缓解。
老年代(Tenure Gen)
老年代的特点是区域较大,对像存活率高。
这种情况,存在大量存活率高的对像,复制算法明显变得不合适。一般是由标记清除或者是标记清除与标记整理的混合实现。
垃圾收集器
Serial/Serial Old收集器
串行收集器是最古老,最稳定以及效率高的收集器,可能会产生较长的停顿,只使用一个线程去回收。新生代、老年代使用串行回收;新生代复制算法、老年代标记-压缩;垃圾收集的过程中会Stop The World(服务暂停)
它还有对应老年代的版本:Serial Old
参数控制: -XX:+UseSerialGC 串行收集器
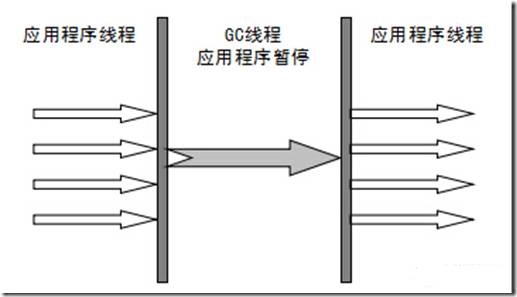
ParNew 收集器
ParNew收集器收集器其实就是Serial收集器的多线程版本,除了使用多线程进行垃圾收集之外,其余行为包括Serial收集器可用的所有控制参数、收集算法、Stop The world、对象分配规则、回收策略等都与Serial收集器完全一样,实现上这两种收集器也共用了相当多的代码。ParNew收集器的工作过程如下图所示。
新生代并行,老年代串行;新生代复制算法、老年代标记-压缩
参数控制:
-XX:+UseParNewGC ParNew收集器 -XX:ParallelGCThreads 限制线程数量
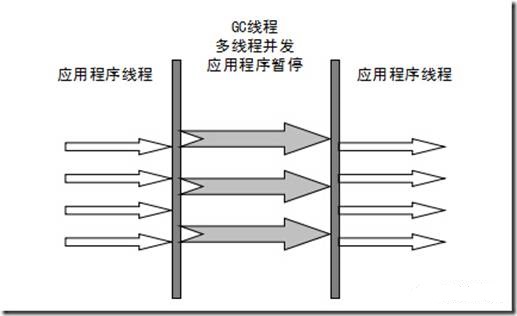
Parallel / Parallel Old 收集器
Parallel Scavenge收集器类似ParNew收集器,Parallel收集器更关注系统的吞吐量。可以通过参数来打开自适应调节策略,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或最大的吞吐量;也可以通过参数控制GC的时间不大于多少毫秒或者比例;新生代复制算法、老年代标记-压缩
参数控制: -XX:+UseParallelGC 使用Parallel收集器+ 老年代串行
Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。这个收集器是在JDK 1.6中才开始提供
参数控制: -XX:+UseParallelOldGC 使用Parallel收集器+ 老年代并行
CMS收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。目前很大一部分的Java应用都集中在互联网站或B/S系统的服务端上,这类应用尤其重视服务的响应速度,希望系统停顿时间最短,以给用户带来较好的体验。
从名字(包含“Mark Sweep”)上就可以看出CMS收集器是基于“标记-清除”算法实现的,它的运作过程相对于前面几种收集器来说要更复杂一些,整个过程分为4个步骤,包括:
- 初始标记(CMS initial mark)
- 并发标记(CMS concurrent mark)
- 重新标记(CMS remark)
- 并发清除(CMS concurrent sweep)
其中初始标记、重新标记这两个步骤仍然需要“Stop The World”。初始标记仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,并发标记阶段就是进行GC Roots Tracing的过程,而重新标记阶段则是为了修正并发标记期间,因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。
由于整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,所以总体上来说,CMS收集器的内存回收过程是与用户线程一起并发地执行。老年代收集器(新生代使用ParNew)
优点: 并发收集、低停顿 缺点: 产生大量空间碎片、并发阶段会降低吞吐量
参数控制:
-XX:+UseConcMarkSweepGC 使用CMS收集器 -XX:+ UseCMSCompactAtFullCollection Full GC后,进行一次碎片整理;整理过程是独占的,会引起停顿时间变长 -XX:+CMSFullGCsBeforeCompaction 设置进行几次Full GC后,进行一次碎片整理 -XX:ParallelCMSThreads 设定CMS的线程数量(一般情况约等于可用CPU数量)
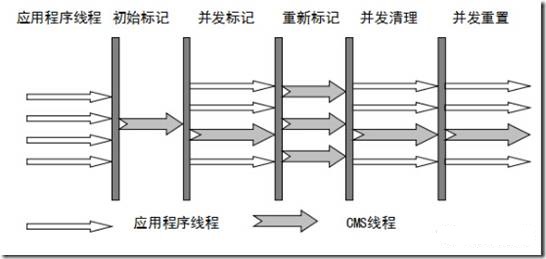
cms是一种预处理垃圾回收器,它不能等到old内存用尽时回收,需要在内存用尽前,完成回收操作,否则会导致并发回收失败
G1收集器
G1**(Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足GC 停顿时间要求的同时,还具备高吞吐量性能特征.** 是目前技术发展的最前沿成果之一,HotSpot开发团队赋予它的使命是未来可以替换掉JDK1.5中发布的CMS收集器。与CMS收集器相比G1收集器有以下特点:
并行与并发:G1能充分利用CPU、多核环境下的硬件优势,使用多个CPU(CPU或者CPU核心)来缩短stop-The-World停顿时间。部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让java程序继续执行。
分代收集:分代概念在G1中依然得以保留。虽然G1可以不需要其它收集器配合就能独立管理整个GC堆,但它能够采用不同的方式去处理新创建的对象和已经存活了一段时间、熬过多次GC的旧对象以获取更好的收集效果。也就是说G1可以自己管理新生代和老年代了。
空间整合:由于G1使用了独立区域(Region)概念,G1从整体来看是基于“标记-整理”算法实现收集,从局部(两个Region)上来看是基于“复制”算法实现的,但无论如何,这两种算法都意味着G1运作期间不会产生内存空间碎片。
可预测的停顿:这是G1相对于CMS的另一大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用这明确指定一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒。
上面提到的垃圾收集器,收集的范围都是整个新生代或者老年代,而G1不再是这样。使用G1收集器时,Java堆的内存布局与其他收集器有很大差别,它将整个Java堆划分为多个大小相等的独立区域(Region),JVM最多可以有2048个Region。 一般Region大小等于堆大小除以2048,比如堆大小为4096M,则Region大小为2M,当然也可以用参数"-
XX:G1HeapRegionSize"手动指定Region大小,但是推荐默认的计算方式。虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔阂了,它们都是一部分(可以不连续)Region的集合。
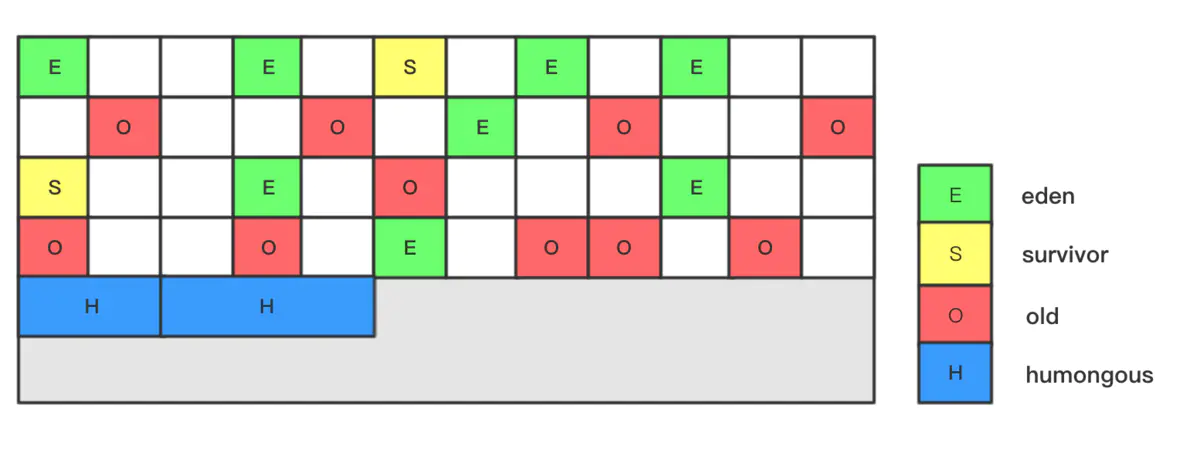
每个Region被标记了E、S、O和H,说明每个Region在运行时都充当了一种角色,其中H是以往算法中没有的,它代表Humongous,这表示这些Region存储的是巨型对象(humongous object,H-obj),当新建对象大小超过Region大小一半时,直接在新的一个或多个连续Region中分配,并标记为H。
为了避免全堆扫描,G1使用了Remembered Set来管理相关的对象引用信息。当进行内存回收时,在GC根节点的枚举范围中加入Remembered Set即可保证不对全堆扫描也不会有遗漏了。
如果不计算维护Remembered Set的操作,G1收集器的运作大致可划分为以下几个步骤:
1、初始标记(Initial Making)
2、并发标记(Concurrent Marking)
3、最终标记(Final Marking)
4、筛选回收(Live Data Counting and Evacuation)
看上去跟CMS收集器的运作过程有几分相似,不过确实也这样。初始阶段仅仅只是标记一下GC Roots能直接关联到的对象,并且修改TAMS(Next Top Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可以用的Region中创建新对象,这个阶段需要停顿线程,但耗时很短。并发标记阶段是从GC Roots开始对堆中对象进行可达性分析,找出存活对象,这一阶段耗时较长但能与用户线程并发运行。而最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中,这阶段需要停顿线程,但可并行执行。最后筛选回收阶段首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划,这一过程同样是需要停顿线程的,但Sun公司透露这个阶段其实也可以做到并发,但考虑到停顿线程将大幅度提高收集效率,所以选择停顿。下图为G1收集器运行示意图:
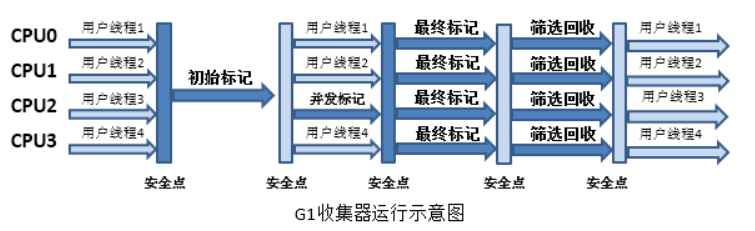
垃圾回收器比较
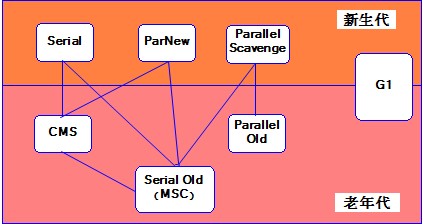
如果两个收集器之间存在连线,则说明它们可以搭配使用。虚拟机所处的区域则表示它是属于新生代还是老年代收集器。
整堆收集器: G1
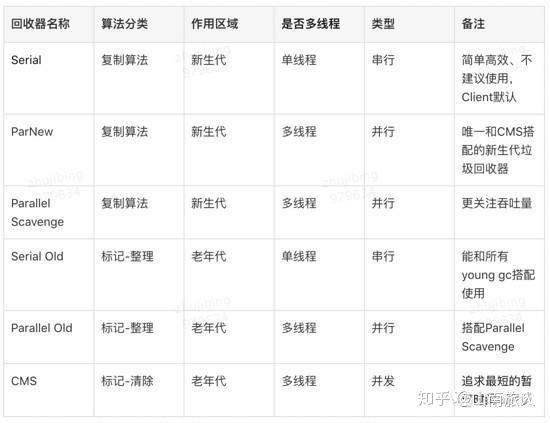
垃圾回收器选择策略 :
客户端程序 : Serial + Serial Old;
吞吐率优先的服务端程序(比如:计算密集型) : Parallel Scavenge + Parallel Old;
响应时间优先的服务端程序 :ParNew + CMS。
G1收集器是基于标记整理算法实现的,不会产生空间碎片,可以精确地控制停顿,将堆划分为多个大小固定的独立区域,并跟踪这些区域的垃圾堆积程度,在后台维护一个优先列表,每次根据允许的收集时间,优先回收垃圾最多的区域(Garbage First)。
ZGC收集器(-XX:+UseZGC)
ZGC是一款JDK 11中新加入的具有实验性质的低延迟垃圾收集器,ZGC是Azul System公司开发的 C4(Concurrent Continuously Compacting Collector)收集器
ZGC的目标主要有4个:
①支持TB量级的堆。
②最大GC停顿时间不超10ms。目前一般线上环境运行良好的JAVA应用Minor GC停顿时间在10ms左右, Major GC一般都需要100ms以上(G1可以调节停顿时间,但是如果调的过低的话,反而会适得其反),之所以能 做到这一点是因为它的停顿时间主要跟Root扫描有关,而Root数量和堆大小是没有任何关系的。
③奠定未来GC特性的基础。
④最糟糕的情况下吞吐量会降低15%。Oracle官方提到了它最大的优点是:它的停顿时间不会随着堆的增大而增长!也就是说,几十G堆的停顿时间是 10ms以下,几百G甚至上T堆的停顿时间也是10ms以下。
不分代(暂时)
单代,即ZGC「没有分代」。我们知道以前的垃圾回收器之所以分代,是因为源于「大部分对象朝生夕死」的假 设,事实上大部分系统的对象分配行为也确实符合这个假设。
ZGC内存布局
ZGC收集器是一款基于Region内存布局的,暂时不设分代的,使用了可并发的标记-整 理算法, 以低延迟为首要目标的一款垃圾收集器。 ZGC的Region可以具有如下图所示的大、 中、 小三类容量:
小型Region(Small Region) : 容量固定为2MB, 用于放置小于256KB的小对象。
中型Region(Medium Region) : 容量固定为32MB, 用于放置大于等于256KB但小于4MB的对象。
大型Region(Large Region) : 容量不固定, 可以动态变化, 但必须为2MB的整数倍, 用于放置4MB或 以上的大对象。 每个大型Region中 只会存放一个大对象, 这也预示着虽然名字叫作“大型Region”, 但它的实际容量完全有可能小于中型 Region, 最小容量可低至4MB。 大型Region在ZGC的实现中是不会被重分配(重分配是ZGC的一种处理动作, 用于复制对象的收集器阶段, 稍后会介绍到)的, 因为复制一个大对象的代价非常高昂。
ZGC运作过程
ZGC的运作过程大致可划分为以下四个大的阶段:
①并发标记(Concurrent Mark):与G1一样,并发标记是遍历对象图做可达性分析的阶段,它的初始标记 (Mark Start)和最终标记(Mark End)也会出现短暂的停顿,与G1不同的是, ZGC的标记是在指针上而不是在对象 上进行的, 标记阶段会更新染色指针中的Marked 0、 Marked 1标志位。
②并发预备重分配(Concurrent Prepare for Relocate):这个阶段需要根据特定的查询条件统计得出本次收 集过程要清理哪些Region,将这些Region组成重分配集(Relocation Set)。ZGC每次回收都会扫描所有的 Region,用范围更大的扫描成本换取省去G1中记忆集的维护成本。
③并发重分配(Concurrent Relocate):重分配是ZGC执行过程中的核心阶段,这个过程要把重分配集中的存 活对象复制到新的Region上,并为重分配集中的每个Region维护一个转发表(Forward Table),记录从旧对象 到新对象的转向关系。ZGC收集器能仅从引用上就明确得知一个对象是否处于重分配集之中,如果用户线程此时并 发访问了位于重分配集中的对象,这次访问将会被预置的内存屏障所截获,然后立即根据Region上的转发表记录将访问转发到新复制的对象上,并同时修正更新该引用的值,使其直接指向新对象,ZGC将这种行为称为指 针的“自愈”(Self-Healing)能力。
④并发重映射(Concurrent Remap):重映射所做的就是修正整个堆中指向重分配集中旧对象的所有引用,但是ZGC中对象引用存在“自愈”功能,所以这个重映射操作并不是很迫切。ZGC很巧妙地把并发重映射阶段要做的工作,合并到了下一次垃圾收集循环中的并发标记阶段里去完成,反正它们都是要遍历所有对象的,这样合并就节 省了一次遍历对象图的开销。一旦所有指针都被修正之后, 原来记录新旧对象关系的转发表就可以释放掉了。
指定使用垃圾回收器(了解)
-XX:+UseSerialGC 年轻代和老年代都用串行收集器
-XX:+UseParNewGC 年轻代使用ParNew,老年代使用 Serial Old
-XX:+UseParallelGC 年轻代使用Paraller Scavenge,老年代使用Serial Old
-XX:+UseParallelOldGC 新生代Paraller Scavenge,老年代使用Paraller Old
-XX:+UseConcMarkSweepGC,表示年轻代使用ParNew,老年代的用CMS + Serial Old
-XX:+UseG1GC 使用G1垃圾回收器
-XX:+UseZGC 使用ZGC垃圾回收器(jdk11以后支持)
JDK 1.8默认使用 Parallel(年轻代和老年代都是)
JDK 1.9默认使用 G1
代码中查看使用的垃圾收集器:
List<GarbageCollectorMXBean> l = ManagementFactory.getGarbageCollectorMXBeans();
for(GarbageCollectorMXBean b : l) {
System.out.println(b.getName());
}