Sharding-Sphere
官方文档:概览 :: ShardingSphere (apache.org)
Sharding-JDBC
项目构建
pom.xml
<!--整合SpringBoot3.X版本-->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
<version>8.0.26</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/druid-spring-boot-starter -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.20</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.shardingsphere/shardingsphere-jdbc-core -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.4.1</version>
</dependency>
<!--解决java.lang.NoSuchMethodError: org.yaml.snakeyaml.representer.Representer: method 'void <init>()' not found,5.4.1版本存在此问题-->
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
<version>2.3.8</version>
</dependency>
<!--解决javax.xml.bind.JAXBException: Implementation of JAXB-API has not been found on module path or classpath.,5.4.1版本存在此问题-->
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.33</version>
</dependency>
</dependencies>application.properties
# 指定配置文件的位置是:sharding.yaml
spring.datasource.driver-class-name=org.apache.shardingsphere.driver.ShardingSphereDriver
spring.datasource.url=jdbc:shardingsphere:classpath:sharding.yamljava
// pojo类
@TableName("user")
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String username;
}
//mapper层
@Mapper
public interface UserMapper extends BaseMapper<User>{
}
//启动类
@SpringBootApplication
@MapperScan("com.fjut.shardingsphere.mapper")
public class ShardingSphereApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingSphereApplication.class, args);
}
}inline表达式
actual-data-nodes: ds$->{0..1}.shoping_0$->{0..1}
# 释义:
ds$->{0..1}则表示:ds0、ds1
# 也可以这样写:
ds$->{['0','1']}
# 也可以组合起来用:
ds$->{['0','1']}.shoping_0$->{0..1}
# 也可以写一些函数
user_$->{Math.abs(username.hashCode()) % 2}读写分离
yml配置
# 配置模式,单机模式
mode:
type: Standalone
repository:
type: JDBC
# 数据源配置
dataSources:
# 主数据库配置,名称自定义
master1:
# 数据源类名,这里使用的是阿里巴巴的Druid连接池
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,包括数据库地址、端口、数据库名以及连接参数
url: jdbc:mysql://192.168.6.136:3306/user
username: remote
password: fujianz123
# 从数据库1配置,名称自定义
slave1:
# 数据源类名,与主数据库相同
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名,与主数据库相同
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,与主数据库类似,但端口不同
url: jdbc:mysql://192.168.6.135:3306/user
username: remote
password: fujianz123
rules:
# 配置读写分离
- !READWRITE_SPLITTING
dataSources:
# 名称自定义
readwrite_ds:
# 用于读数据源的名称
writeDataSourceName: master1
# 用于写数据源的名称
readDataSourceNames:
- slave1
transactionalReadQueryStrategy: PRIMARY
# 负载均衡策略
loadBalancerName: random
loadBalancers:
#随机负载均衡,名称自定义
random:
type: RANDOM
# 轮询负载均衡,名称自定义
robin:
type: ROUND_ROBIN
#按照权重负载均衡 ,名称自定义
weight:
type: WEIGHT
props:
slave1: 1
slave2: 2
# 用于指定哪些单表需要被 ShardingSphere 管理,如果使用的表不被其包含,就会报错
- !SINGLE
tables:
#- ds_0.t_single # 加载指定单表
#- ds_1.* # 加载指定数据源中的全部单表
- "*.*" # 加载全部单表
# 属性配置
props:
# 是否显示执行的SQL语句
sql-show: true事务模型
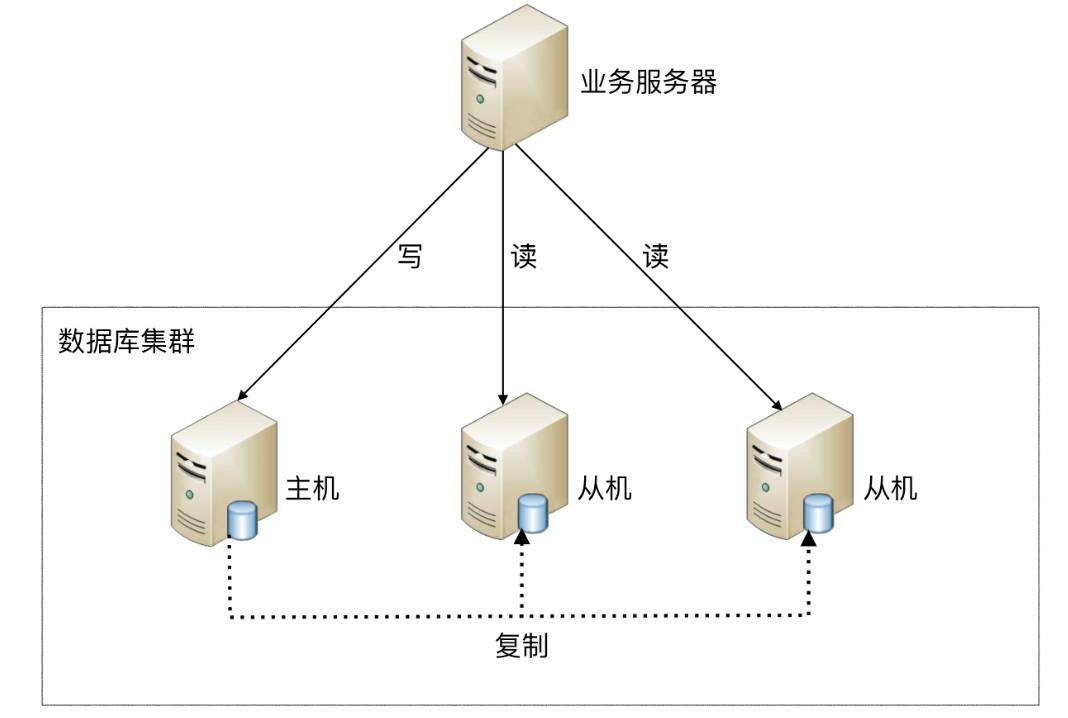
为了保证主从库间的事务一致性,避免跨服务的分布式事务,ShardingSphere-JDBC的主从模型中,事务中的数据读写均用主库。
- 不添加@Transactional:insert对主库操作,select对从库操作
- 添加@Transactional:则insert和select均对主库操作
- 注意:在JUnit环境下的@Transactional注解,默认情况下就会对事务进行回滚(即使在没加注解@Rollback,也会对事务回滚)
分库分表
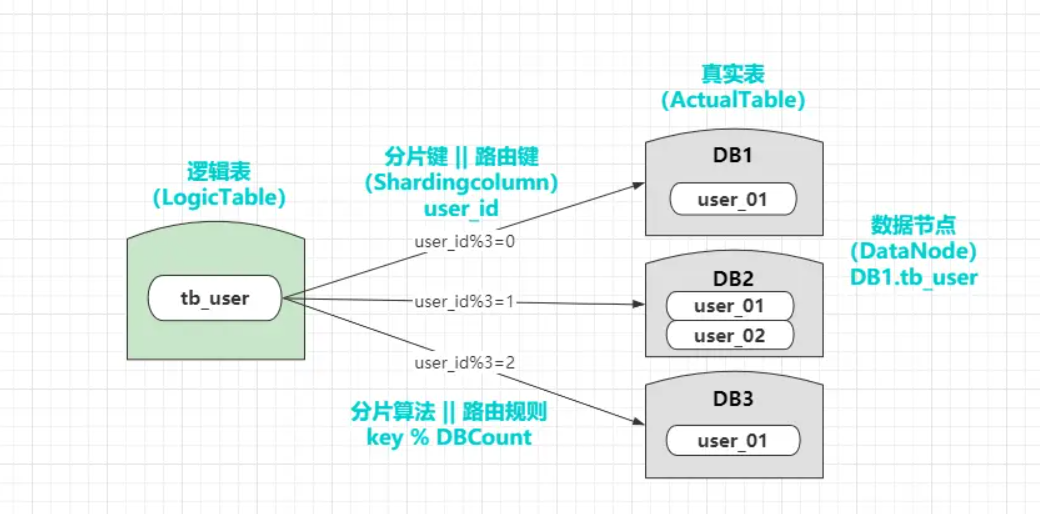
逻辑表:提供给应用程序操作的表名,程序可以像操作原本的单表一样,灵活的操作逻辑表。
真实表:在各个数据库节点上真实存在的物理表,但表名一般都会和逻辑表存在偏差。
数据节点:主要是用于定位具体真实表的库表名称,如DB1.tb_user1、DB2.tb_user2.....
- 均匀分布:指一张表的数量在每个数据源中都是一致的。
- 自定义分布:指一张表在每个数据源中,具体的数量由自己来定义,下图就是一种自定义分布。
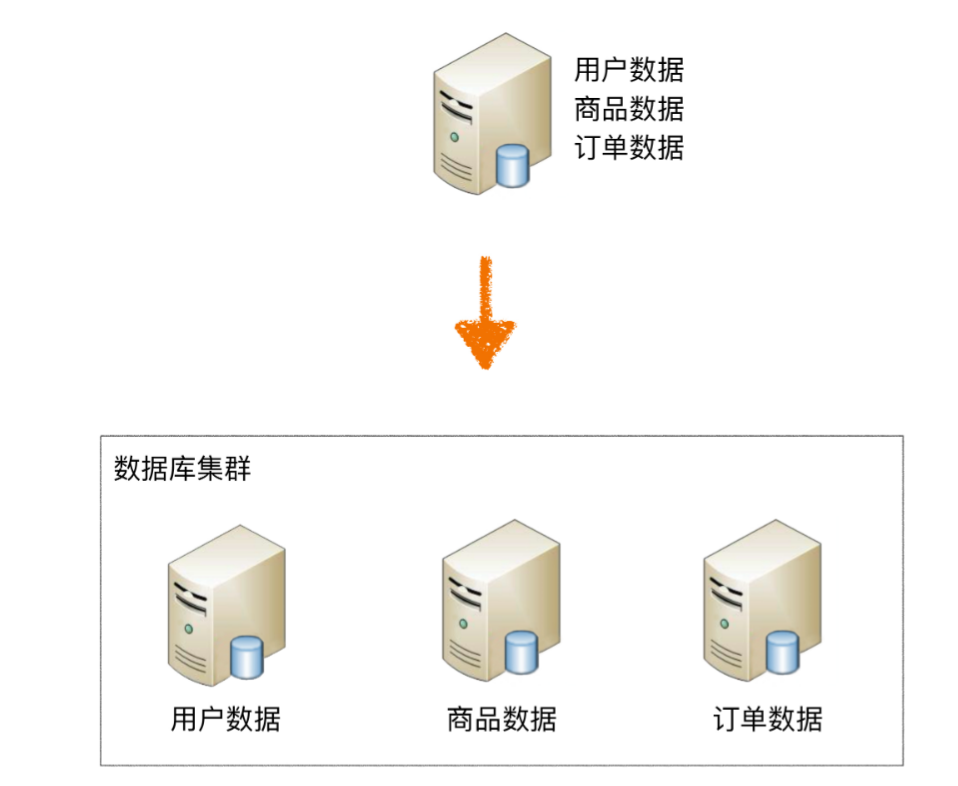
垂直分片
专库专用。 按照业务将表进行归类,分布到不同的数据库中。一般而言,分布式架构的系统默认都有独享库的概念,所以不需要通过shardingsphere来实现。
# 配置模式,单机模式
mode:
type: Standalone
repository:
type: JDBC
# 数据源配置
dataSources:
# 主数据库配置
master1:
# 数据源类名,这里使用的是阿里巴巴的Druid连接池
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,包括数据库地址、端口、数据库名以及连接参数
url: jdbc:mysql://192.168.6.136:3306/user
username: remote
password: fujianz123
# 从数据库1配置
slave1:
# 数据源类名,与主数据库相同
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名,与主数据库相同
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,与主数据库类似,但端口不同
url: jdbc:mysql://192.168.6.135:3306/user
username: remote
password: fujianz123
rules:
# 对于user表的查询,将会到master1节点下的user表,对于user_info表的查询,将回到slave1节点下的user_info表
- !SHARDING
tables: # 数据分片规则配
# 逻辑表名称
user:
actualDataNodes : master1.user # 由数据源名 + 表名组成(参考 Inline 语法规则)
# 逻辑表名称
user_info:
actualDataNodes: slave1.user_info # 由数据源名 + 表名组成(参考 Inline 语法规则)
- !SINGLE
tables:
#- ds_0.t_single # 加载指定单表
#- ds_1.* # 加载指定数据源中的全部单表
- "*.*" # 加载全部单表
# 属性配置
props:
# 是否显示执行的SQL语句
sql-show: true水平分片
- 对于数据库:id%2,偶数id将会落入0库,奇数id将会落入1库
- 对于数据表:Math.abs(username.hashCode()) % 2,值为偶数将会落入0库,奇数将会落入1库
# 配置模式,单机模式
mode:
type: Standalone
repository:
type: JDBC
# 数据源配置
dataSources:
# 主数据库配置
db_0:
# 数据源类名,这里使用的是阿里巴巴的Druid连接池
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,包括数据库地址、端口、数据库名以及连接参数
url: jdbc:mysql://192.168.6.138:3306/user
username: remote
password: fujianz123
# 从数据库1配置
db_1:
# 数据源类名,与主数据库相同
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名,与主数据库相同
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,与主数据库类似,但端口不同
url: jdbc:mysql://192.168.6.137:3306/user
username: remote
password: fujianz123
rules:
- !SHARDING
# 数据分片规则配置
tables:
# 逻辑表名称
user:
actualDataNodes : db_$->{0..1}.user_$->{0..1} # 由数据源名 + 表名组成(参考 Inline 语法规则)
# 用于指定主键
keyGenerateStrategy:
# 自增列名称,缺省表示不使用自增主键生成器
column: id
# 分布式序列算法名称
keyGeneratorName: snowflake
# mybatisplus需要使用@TableId(type = IdType.AUTO)标注实体类
# 数据库分片策略
databaseStrategy :
standard:
shardingColumn: id
shardingAlgorithmName: database_sharding
# 表分片策略
tableStrategy:
standard:
shardingColumn: username
shardingAlgorithmName: table_sharding
#defaultDatabaseStrategy: # 默认数据库分片策略
#defaultTableStrategy: # 默认表分片策略
#defaultKeyGenerateStrategy: # 默认的分布式序列策略
#defaultShardingColumn: # 默认分片列名称
#主键生成算法
keyGenerators:
snowflake: # 分布式序列算法名称
type: SNOWFLAKE
# 路由分片算法
shardingAlgorithms:
database_sharding:
type: INLINE
props:
algorithm-expression: db_$->{id % 2}
table_sharding:
type: INLINE
props:
algorithm-expression: user_$->{Math.abs(username.hashCode()) % 2}
- !SINGLE
tables:
#- ds_0.t_single # 加载指定单表
#- ds_1.* # 加载指定数据源中的全部单表
- "*.*" # 加载全部单表
# 属性配置
props:
# 是否显示执行的SQL语句
sql-show: true详细配置
表
逻辑表
相同结构的水平拆分数据库(表)的逻辑名称。 例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order。
真实表
在水平拆分的数据库中真实存在的物理表。 即 t_order_0 到 t_order_9。
绑定表
为了避免跨库关联查询,如一笔订单记录中,多笔订单详情记录被分发到不同的节点中存储,联表查询时需要访问多个节点。可以使用绑定表,通过分片键关联查询,关联的表必须使用相同的分片键和分配策略。
- 不使用绑定表,联表查询将会是关联库的笛卡尔积
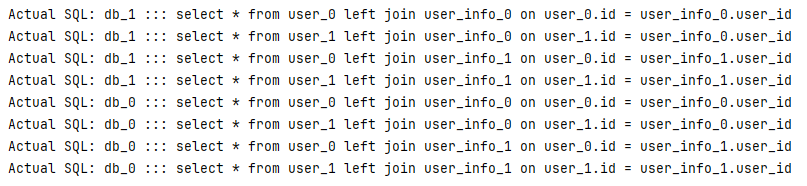
- 使用绑定表,根据分片键联查,只会关联绑定的表

# 数据源配置
dataSources:
# 主数据库配置
db_0:
# 数据源类名,这里使用的是阿里巴巴的Druid连接池
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,包括数据库地址、端口、数据库名以及连接参数
url: jdbc:mysql://192.168.6.140:3306/user
username: remote
password: fujianz123
# 从数据库1配置
db_1:
# 数据源类名,与主数据库相同
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名,与主数据库相同
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,与主数据库类似,但端口不同
url: jdbc:mysql://192.168.6.139:3306/user
username: remote
password: fujianz123
rules:
- !SHARDING
tables:
# user表
user:
actualDataNodes: db_$->{0..1}.user_$->{0..1}
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
databaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: user_database_sharding
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: user_table_sharding
# user_info表
user_info:
actualDataNodes: db_$->{0..1}.user_info_$->{0..1}
keyGenerateStrategy:
column: user_id
keyGeneratorName: snowflake
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: userInfo_database_sharding
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: userInfo_table_sharding
# 绑定表user和user_info
bindingTables:
- user,user_info
keyGenerators:
snowflake:
type: SNOWFLAKE
shardingAlgorithms:
user_database_sharding:
type: INLINE
props:
algorithm-expression: db_$->{id % 2}
userInfo_database_sharding:
type: INLINE
props:
algorithm-expression: db_$->{user_id % 2}
user_table_sharding:
type: INLINE
props:
algorithm-expression: user_$->{Math.abs(id.hashCode()) % 2}
userInfo_table_sharding:
type: INLINE
props:
algorithm-expression: user_info_$->{Math.abs(user_id.hashCode()) % 2}
- !SINGLE
tables:
#- ds_0.t_single # 加载指定单表
#- ds_1.* # 加载指定数据源中的全部单表
- "*.*" # 加载全部单表
# 属性配置
props:
# 是否显示执行的SQL语句
sql-show: true广播表
所有的分片数据源中都存在的表,单表查询时只会到一个数据库查询,关联查询时仅会在自己数据库内查询,插入会向所有数据库的广播表插入,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
# 配置模式,单机模式
mode:
type: Standalone
repository:
type: JDBC
# 数据源配置
dataSources:
# 主数据库配置
db_0:
# 数据源类名,这里使用的是阿里巴巴的Druid连接池
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,包括数据库地址、端口、数据库名以及连接参数
url: jdbc:mysql://192.168.6.141:3306/user
username: remote
password: fujianz123
# 从数据库1配置
db_1:
# 数据源类名,与主数据库相同
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名,与主数据库相同
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,与主数据库类似,但端口不同
url: jdbc:mysql://192.168.6.142:3306/user
username: remote
password: fujianz123
- !SINGLE
tables:
#- ds_0.t_single # 加载指定单表
#- ds_1.* # 加载指定数据源中的全部单表
- "*.*" # 加载全部单表
# 配置广播表
- !BROADCAST
tables:
- dict
# 属性配置
props:
# 是否显示执行的SQL语句
sql-show: true单表
并非所有的表都需要做分库分表操作,所以当一张表的数据无需分片到多个数据源中时,就可将其配置为单表,这样所有的读写操作最终都会落入这一张单表中处理。
# 数据源配置
dataSources:
# 从数据库1配置
mysql:
# 数据源类名,与主数据库相同
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名,与主数据库相同
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,与主数据库类似,但端口不同
url: jdbc:mysql://localhost:3306/pratice
username: root
password: fujianz123
rules:
- !SINGLE
tables:
#- ds_0.t_single # 加载指定单表
#- ds_1.* # 加载指定数据源中的全部单表
- "*.*" # 加载全部单表
# 未在规则中配置的单表,查询都会走mysql数据源,也可以在上方指明
defaultDataSource: mysql自定义分片算法
实现StandardShardingAlgorithm接口
- Collection:存放的是所有可路由的数据节点,如果配置的是库级别的分片策略,这里存放的是所有库的名称;如果配置的是表级别的分片策略,这里存放的是所有表的名称
- PreciseShardingValue
- preciseShardingValue.getLogicTableName(); :获取路由的逻辑表名
- preciseShardingValue.getColumnName():获取路由键
- preciseShardingValue.getValue():获取路由键的值
public class ShardingConfig implements StandardShardingAlgorithm {
// 实现精确查询的方法(in、=查询会调用方法)
@Override
public String doSharding(Collection collection, PreciseShardingValue preciseShardingValue) {
}
// 实现范围查询的方法(BETWEEN AND、>、<、>=、<=会调用的方法)
@Override
public Collection<String> doSharding(Collection collection, RangeShardingValue rangeShardingValue) {
}
}
//Complex自定义分片,适用于多路由键的场景,一张表需要通过多个核心字段查询时,可以配置多个路由键,此时就需要自己实现分片路由的算法。
public class Shardingsphere implements ComplexKeysShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection collection, ComplexKeysShardingValue complexKeysShardingValue) {
return null;
}
}
//Hint:当一张表经常需要执行一些较为复杂的SQL语句时,这种SQL语句Sharding-Sphere无法自动解析,就可以自己编写Hint策略的实现类,强制指定这些SQL落入到哪些节点中处理。
public class Shardingsphere implements HintShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection collection, HintShardingValue hintShardingValue) {
return null;
}
}根据地址路由到不同库
public class ShardingConfig implements StandardShardingAlgorithm {
// 实现精确查询的方法(in、=查询会调用方法)
@Override
public String doSharding(Collection collection, PreciseShardingValue preciseShardingValue) {
// 获取本次SQL语句中具体的路由键值
String address = (String)preciseShardingValue.getValue();
String targetTable = "";
//福建则路由到db_0,浙江则路由到db_1
if (address.equals("福建"))
targetTable+= "db_0";
if (address.equals("浙江"))
targetTable+= "db_1";
// 判断计算出的目标表是否在Logic_DB中存在
if (collection.contains(targetTable))
// 如果配置的数据节点中有这张表,则直接返回目标表名
return targetTable;
// 不存在则抛出相应的异常信息
throw new UnsupportedOperationException(targetTable +
"表在逻辑库中不存在,请检查你的SQL语句或数据节点配置...");
}
// 实现范围查询的方法(BETWEEN AND、>、<、>=、<=会调用的方法)
@Override
public Collection<String> doSharding(Collection collection, RangeShardingValue rangeShardingValue) {
return collection;
}
}# 数据源配置
dataSources:
# 主数据库配置
db_0:
# 数据源类名,这里使用的是阿里巴巴的Druid连接池
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,包括数据库地址、端口、数据库名以及连接参数
url: jdbc:mysql://192.168.6.141:3306/user
username: remote
password: fujianz123
# 从数据库1配置
db_1:
# 数据源类名,与主数据库相同
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
# JDBC驱动类名,与主数据库相同
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接URL,与主数据库类似,但端口不同
url: jdbc:mysql://192.168.6.142:3306/user
username: remote
password: fujianz123
rules:
- !SHARDING
tables:
dict:
actualDataNodes: db_${0..1}.dict
# 数据库分片策略
databaseStrategy:
standard:
shardingColumn: name
shardingAlgorithmName: address_route
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
shardingAlgorithms:
# 配置一个自定义的Standard分片算法
address_route:
# 声明使用自定义的算法实现类
type: CLASS_BASED
props:
strategy: STANDARD
algorithmClassName: com.fjut.shardingsphere.config.ShardingConfig
#主键生成算法
keyGenerators:
snowflake: # 分布式序列算法名称
type: SNOWFLAKE
- !SINGLE
tables:
#- ds_0.t_single # 加载指定单表
#- ds_1.* # 加载指定数据源中的全部单表
- "*.*" # 加载全部单表
# 属性配置
props:
# 是否显示执行的SQL语句
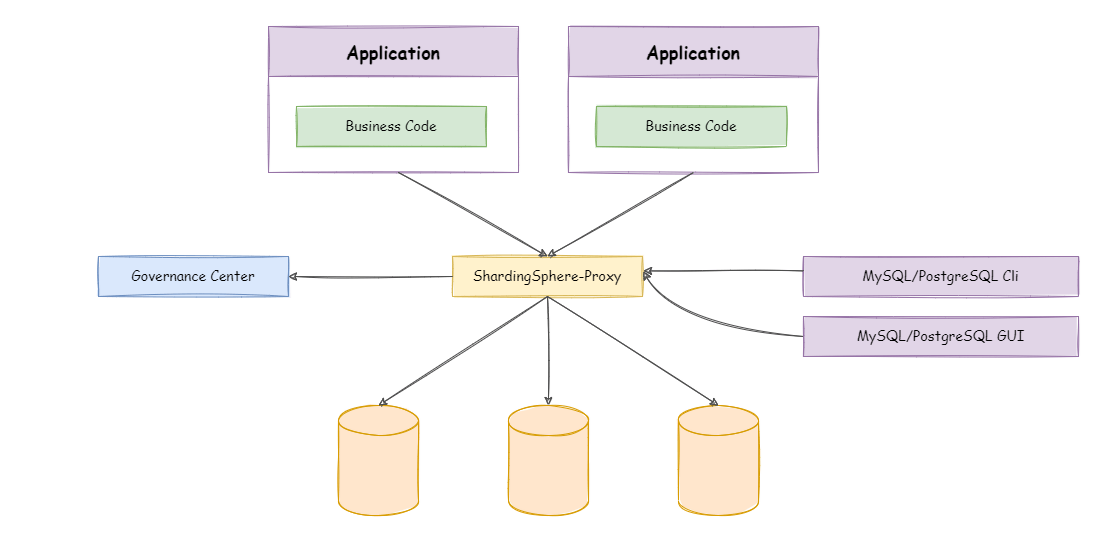
sql-show: trueShardingSphere-Proxy
Sharding-Proxy的用法基本上和Sharding-JDBC完全相同,不同的区别在于:Sharding-Proxy只是单独拧出来部署了而已。