golang
基础语法
// 定义了包名,main表示一个可独立执行的程序。
package main
import "fmt"
// 可独立执行程序执行入口。
func main() { // {’ 必须和函数名在同一行,不能另起一行
fmt.Print("Hello World"); // 可以接分号,可以不接
}常量、变量
- 局部常/变量:代码块内声明,作用域仅限于对应代码块内,声明后必须使用,优先级大于全局变量。
- 全局常/变量:代码块外声明,声明后可暂不使用,首字母大写(公开,作用域跨包),小写(私有,作用域包内)。
变量
变量声明
var a int = 5
// 如果初始化时指定了值,可以省略类型,由编译器推断类型
var b = 8
func main() {
// 声明并赋值,无法声明为全局变量
c := 2
}多变量声明
var x,y int = 1,2
var e, f = true,"hello"
var (
a string = "aaa"
b int = len(a)
)
func main() {
// _表示匿名变量,仅作为占位符,即丢弃该参数
_, b := 1, "aaa"
// 交换变量
a, b = b, a
}常量
变量在运行时分配内存,常量在编译阶段就已经计算完成并内联到使用它的地方。即常量不占用运行时内存,没有内存地址的概念,无法进行取地址操作。
常量声明
const b string = "abc"
// 无类型常量,可以在赋值或计算中,自动根据目标变量的类型进行隐式转换
// 其在编译阶段可以存储比基本类型更高的精度(256位),但仅在常量表达式计算中拥有此精度
const TimeoutSeconds = 3.7
var t1 float32 = TimeoutSeconds // 自动转化为 float32
var t2 float64 = TimeoutSeconds // 自动转化为 float64
var t3 int = TimeoutSeconds // 自动转化为 int (截断为3)
// 不同种类的无类型常量有各自的默认类型,如整型是int,浮点型是float64
const a = 2.55
fmt.Println(a + 1) // a以float64参与计算,输出3.55多常量声明
const _, b, c = 1, false, "str"
const a, b int = 1,1;
// 内部使用的函数必须为内置函数,否则无法通过编译
const (
a = "abc"
// 可以复用前方定义的常量
b = len(a)
// 字符串类型在 go 里是个结构, 包含指向底层数组的指针和长度,这两部分每部分都是 8 个字节,所以字符串类型大小为 16 个字节。
c = unsafe.Sizeof(a)
// 省略赋值:当某个常量没有显式赋值时,它会自动复用上一行的表达式
d
)iota
iota 从 0 开始,在同一个 const 声明块中,每新增一行常量声明,其值自动加 1
// 表达式用法,无类型常量,一般不需要担心溢出
const (
_ = iota // 跳过第一个值 0
KB = 1 << (10 * iota) // 1 << 10 = 1024
MB // 1 << 20 = 1048576,未显示声明,自动继承上一行的表达式
)
// 中断与重置
const (
d = iota,c = iota // 0 0,同一行值相同
e = 100 // 显式赋值,中断递增
f = iota // 2(恢复递增,计数不中断)
)零值
在 Go 中,声明变量但未显式初始化时,变量会被赋予该类 型的“零值”。
- 数值类型(int, float等)、字符类型(rune、byte)、复数类型(complex64、complex128) ->
0、0.0、0+0i等 - 字符串 ->
""(空字符串) - 布尔型 ->
false - 结构体 -> 所有字段都为各自类型的零值
- 数组 -> 每个元素都是对应类型的零值
- 指针、接口(无确定类型,所以设置零值为nil)、切片、map、channel、函数 ->
nil
输入输出
输入
var name string
fmt.Scan(&name) // 按空白符分隔
fmt.Scanln(&name) // 按换行符分隔
fmt.Scanf("%s", &name) // 按占位符读入输出
fmt.Print(name) // 直接将参数输出,不会添加任何额外的空白字符
fmt.Println("a=", a, ",b=", b, ",c=", c) // 多个值以空格分割,结尾添加换行符
fmt.Printf("a=%d,b=%d,c=%d", a, b, c) // 按占位符输出
// %v 默认格式(根据类型自动选择),如{10}
// %+v 结构体额外显示字段名,如{A:10}
// %#v 更详细的格式(含类型名、引号等),如main.S{A:10}
// %T 输出值的类型,如float64
u := User{Name: "Alice", Age: 25}
str1 := fmt.Sprintf("用户信息:%v", u)// 返回格式化结果,不输出数据类型
基本数据类型
基本类型
整型
- int、uint:平台相关,32位系统为32,64位系统为64
- uint8、uint16、uint32、uint64、int8、int16、int32、int64:通过math.MaxUint16 获取最大/小值
v:=123_456 // _作为分隔符,实际表示123456
v:=0b00101101 // 接受字面量,表示二进制00101101
v:=0x1p-2 // 接受字面量,表示十六进制的1 / 2^2- uintptr:平台相关,32位系统为32,64位系统为64,其用于存储一个内存地址,其不会阻止GC回收这个地址内存(普通指针引用会参与GC追踪),主要用于底层编程,特别是需要与操作系统交互或进行指针运算的场景。
// 出于安全考虑,不允许直接对普通指针进行算术运算(如 ptr + 1),所以需要转为uintptr进行运算。
p := unsafe.Pointer(&obj)
nextPtr := unsafe.Pointer(uintptr(p) + offset)浮点型
存在精度损失,需要使用第三方依赖解决:https://github.com/shopspring/decimal
// 默认64位
float32、float64
// 支持科学计数法
num8 := 5.1234e2 // ? 5.1234 * 10 的2次方复数型
var complexNum complex128 = 3.14 + 2i // 复数128,复数默认类型
var complex32 complex64 = 1 + 2i // 复数64布尔型
var a bool = true;字符型
byte(uint8 的别名):主要用于表示 ASCII 字符(一字节)
// 特殊值和错误处理需要负数,如InvalidRune(-1)、EOF(-2),所以不用unit
rune(int32 的别名):主要用于表示 Unicode 码点(三字节),在处理字符串时,需要将字符串转换为 rune字符串
字符串底层是[]byte, 所有操作均是针对字节进行的,例如:string[i]只能获取第i个字节,需要转为[]rune才能获取第i个字符。
字符串是不可变的,若要修改,需要先将其转换成[]rune或[]byte进行修改,完成后再转换为string(会重新分配内存)。
- 并发环境可以保证数据安全。
- 哈希表使用字符串作为key,不变性使其不需要每次都重新计算hash值。
// 单行字符串
var str string = "知道"
// 多行字符串,保留原格式,即使是转义字符(如 \n)会被原样输出
var s string = `今天
天气
真好`| 方法 | 介绍 |
|---|---|
| len(str) | 获取字符串字节数,获取字符数需要转化:len([]rune(s)) |
| + 或 fmt.Sprintf | 拼接字符串,建议大量拼接时使用 strings.Builder 或 bytes.Buffer,<br>例如:var builder strings.Builder <br> builder.WriteString("a") <br> fmt.Println(builder.String()) |
| strings.Split | 分割 |
| strings.contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀 / 后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位置(按字节数,而不是字符数) |
| strings.Join(a[]string, sep string) | join 操作 |
指针
用于修改原数据或省去大结构体的拷贝开销。
var p *int = &x // 通过取地址获取对应指针
p := new(int) // 通过new获取指向对应类型零值的指针
*p = 20 // 通过*解引用,修改原始变量的值
p := &Person{Name: "Alice", Age: 30}
(*p).Age = 31 // 解引用访问字段
p.Age = 32 // 语法糖,与上面等价类型转换
Go语言中只有强制(显示)类型转换,同类型才可以参与计算(除了无类型常量)。
// 数值类型间转换
var a int16 = 1
var b int32 = 2
fmt.Println(a - int16(b))
// 各类型转换为字符串,不能使用+
var str string = fmt.Sprintf("%d %f %t", 1, 1.2, false) // 通过Sprintf
strconv.FormatBool(true) // 通过strconv
// 字符串转各类型
num64, err := strconv.ParseInt(s, 10, 64) // 转int64,基数10
f64, err := strconv.ParseFloat(s, 64) // 转float64
b2, _ := strconv.ParseBool(s2) // 转bool
b := []byte(s) // 字符串转[]byte
r := []rune(s) // 字符串转[]rune(每个元素是一个Unicode字符)复合数据类型
数组
固定长度(不可增删元素,且长度是类型的一部分)且元素类型相同,其在编译期确定,所以数组长度不能是变量。
var array [3]int // 使用零值初始化
var array1 = [3]int{1, 2, 3} // 全部指定值初始化
var array2 = [5]int{1, 2, 3} // 部分指定值初始化
var array3 = [...]int{1, 2, 3} // 指定值初始化,且自动推断数组长度
array4 := [...]int{1: 1, 3: 5} // 指定索引1的值为1,索引3的值为5,其余为默认零值
// 多维数组,只有第一层可以使用...来让编译器推导数组长度
array5 := [...][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}切片
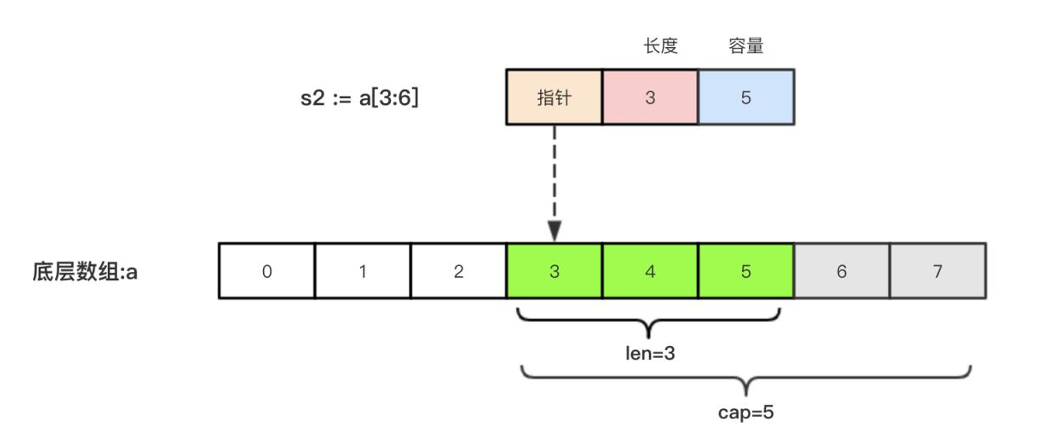
定义
切片占用 24 字节
- 8 字节指针:指向在堆上分配的底层数组,所以多个切片引用相同数组时,对其中任一个的修改会影响其他切片。
- 8 字节容量:当前切片指向数组的容量,从指针指向位置开始,到引用数组末尾元素个数。
- 8 字节长度:当前切片存储元素的个数
var identifier []int // 声明空切片(可以对nil切片进行append操作,因为其对nil进行了特判)
var identifier := []int{} // 声明并初始化一个空切片,不为nil,len为0
// 通过make指定切片容量(cap(x))和长度(len(x)),容量需要大于长度
var slice1 []type = make([]type, length, capacity) // 类型、长度、容量
var slice1 []type = make([]T, length) // 类型、长度&容量
// 直接初始化切片,其cap=len=3
s :=[] int {1,2,3}
// 基于已有切片进行创建,前闭后开,共用同一个底层数组
s := arr[startIndex:endIndex:maxCap] // 不指定默认值如下:[0,len(arr),cap(arr) - startIndex]
arr := [5]int{1, 2, 3, 4, 5}
s1 := arr[1:3] // len=2, cap=4(5-1)
s2 := arr[1:3:4] // len=2, cap=3(4-1)使用
// 向切片添加元素,长度大于容量时,可能触发扩容导致底层数组变化,所以会返回一个新的切片。
// 容量小于 1024 时,每次扩容为原来的 2 倍;容量大于等于 1024 时,每次扩容为原来的 1.25 倍
numbers = append(numbers, 2,3,4) // 追加一个或者多个元素
numbers2 = append(numbers2, numbers...) // 追加另一个切片
// 将src切片的数据,拷贝到target,会创建新的底层数组(浅拷贝)
copy(target,src)
// 从切片中删除元素
a := []int{30, 31, 32, 33, 34, 35, 36, 37}
a = append(a[:2], a[3:]...) // 要删除索引为2的元素
// 清空切片
s = []int{} // 重新分配
s = s[:0] // 切片长度为 0
// 过滤指定元素
result := s[:0] // 重用底层数组
for _, v := range s {
if predicate(v) {
result = append(result, v)
}
}排序
// 针对不同类型进行排序
sort.Ints(intList)
sort.Float64s(float8List)
sort.Strings(stringList)
// 逆序
sort.Sort(sort.Reverse(sort.IntSlice(intList)))
sort.Sort(sort.Reverse(sort.Float64Slice(float8List)))
sort.Sort(sort.Reverse(sort.StringSlice(stringList)))map
map 是无序的,每次遍历 map,键的顺序都可能不同,这是设计者为了防止程序员依赖 map 的顺序而故意做的随机化处理。
map的桶中存储的是value的值,而不是其引用(java存储的是其堆上的引用)。
go// 获取的都是value的副本,如果需要修改结构体字段,需要将 Map 的 Value 定义为指针类型 func main() { type User struct { Name string } m := map[int]User{ 1: {"Alice"}, } // 编译报错,m[key] 返回的是对应value的副本,下方操作不会影响value,没有意义,所以禁止 // m[1].Name = "Bob" // 编译报错,动态扩容会导致地址变更,允许取地址可能导致野指针,所以禁止。 // user := &m[1] user := m[1] user.Name = "Bob" fmt.Print(m) }
定义
// map为对nil进行特殊处理,对nil进行添加元素会触发panic
var test1 map[string]string = make(map[string]string, 10)
test2 := make(map[string]string)
test3 := map[string]string{
"one" : "php",
"two" : "golang",
"three" : "java",
}
language := make(map[string]map[string]string)使用
// 如果key不存在,则val为零值,expire为false,只接受一个参数,则得到val
val, expire := language["php"]
val := language["php"]
//修改(不存在则增加)
language["php"] = "3"
//删除了php子元素
delete(language, "php")
// 如果只接受一个参数,则为key(遍历是无序的)
for k, v := range scoreMap {
fmt.Println(k, v)
}值类型与引用类型
golang中所有的变量传递都是值传递,所谓的“引用类型”,本质上其是一个指针或是一个包含了一个指向底层数据指针的结构体(指针、切片、映射、通道、接口、函数等)。
// 作为参数传递时,传递了下方内容,通过指针修改了底层数组,所以原数据也会发生改变。
type SliceHeader struct {
Pointer unsafe.Pointer // 指向底层数组的指针
Len int // 长度
Cap int // 容量
}
// interface{} 内部包含指向具体值、类型的指针,参数传递后修改只是修改了指针的指向,而没有修改指针指向原有的数据,所以原数据不会改变。
func test(a interface{}) {
a = 2
}
func main() {
var a interface{} = 1
test(a)
fmt.Print(a)
}new和make
make 仅适用于slice、map、channel,用于分配内存并根据传入的参数(长度、容量等)初始化底层的复杂数据结构,返回一个实例。
new 适用于除了make支持外的类型,用于分配内存并以赋予零值,返回一个指针(func new(Type) *Type)。如果使用new为slice等分配内存,得到的是指向这些类型内部零值结构体的指针(如slice指向的数组就是nil)
// 初始为nil,必须new后才可以使用
var a *int
a = new(int) // 等同于 a = &int{}
*a = 10自定义类型与别名
// 自定义类型,获取变量类型得到的是Code
type Code int
// 在同一个包下,可以为Code类型绑定方法
func (c Code) GetMsg() string {
// 与原始类型比较时需要进行类型转换
if int(SuccessCode) == i :
return "成功"
}
// 类型别名,获取变量类型得到的是uint8,不能绑定方法,与uint8比较时不需要转换类型
type byte = uint8运算符
自增/减运算符
golang中,++和--只能独立使用,且不存在前置++和--,其余运算符和c保持一致
i++ //正确
a = i++ //错误,只能独立使用
++i //错误,没有前++--==
- 指针:比较指针指向的地址。
- 数组:比较数组长度和每个元素(需元素可比较)。
- 切片、映射、函数、及包含这些类型的结构体:只可与 nil 进行比较。
- 结构体:比较每个字段(需字段可比较)
- 通道:比较通道的内存地址
分支循环
分支
go语言中没有三目运算
// 允许在if表达式之前添加一个执行语句,再根据变量值进行判断(执行结果作用域仅在当前分支,不会造成污染)
if num := 56; num >= 90 {
// else 或 else if 必须与前一个 if 代码块的右大括号 } 写在同一行
} else if num > 0 {
} else {
}
// case中多行使用大括号包裹,一个case执行完默认直接结束switch,不会穿透到下一个
switch {
case age <= 0:{
fmt.Println("<=0")
}
case age <= 18:
fmt.Println("<=18")
fallthrough // 穿透到下一个case继续执行
case age <= 35:
fmt.Println("<=35")
default:
fmt.Println(">35")
}
// 根据week的值进行枚举匹配
switch week {
case 1,2,3,4,5:
fmt.Println("工作日")
case 6, 7:
fmt.Println("双休")
default:
fmt.Println("错误")
}
// 根据类型进入分支
switch val := v.(type) {
case Person:
fmt.Printf("Person类型:姓名=%s,年龄=%d\n", val.Name, val.Age)
case Student:
fmt.Printf("Student类型:姓名=%s,分数=%.1f\n", val.Name, val.Score)
case []int:
fmt.Printf("[]int切片类型,值为%v\n", val)
}循环
go中没有while
// 基本for循环
for i := 0; i <= 100; i++ {
sum += i
}
// 死循环
for {
time.Sleep(1 * time.Second)
}
// 省略初始条件和变化语句(若初始条件和变化语句都为空,则分号也可省略)
for ; i <= 100; {
i++
}
// 遍历数组、切片、字符串,第一个参数是索引,第二个参数是值
for index, s2 := range s {
fmt.Println(index, s2)
}
// 遍历map,第一个参数就是key,第二个就是value
for key, val := range s {
fmt.Println(key, val)
}break
// break默认只能跳出一层循环,通过label标签,可以指定跳出的循环(针对'for'、'select' 或 'switch' )
label:
for i := 0; i <2; i++ {
for j :=0; j <10; j++ {
if j == 2 {
break label
}
}
}continue
// continue默认跳过当前循环的本次迭代,通过标签,可以跳过指定循环的本次迭代(针对'for')
here:
for i := 0; i < 2; i++ {
for j := 0; j < 4; j++ {
if j == 2 {
continue here
}
fmt.Println("i j的值", i, "-", j)
}
}goto
// 可以跳转到任意标签位置(任意)
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
//设置退出标签
goto breakTag
}
fmt.Printf("%v-%v\n", i, j)
}
}
return
breakTag:
fmt.Println("结束for循环")函数
概述
go中方法通过方法名首字母大小写确定其作用域。
- 方法(Method):与特定类型关联的函数,有接收者(receiver)。
- 函数(Function):独立的函数,没有接收者。
定义
// 单返回值,若参数x,y类型一致可以合并在一起
func swap(x int, y string) string {
return y
}
// 多返回值
func swap(x, y string) (string, string) {
return y, x
}
// 可变参数列表(只能作为参数列表最后一个参数)
func add2(numList ...int) {
fmt.Println(numList)
}
// 命名返回值,再返回参数中直接定义,裸返回即可
func rectangleProperties(length, width float64) (area float64, perimeter float64) {
area = length * width
perimeter = 2 * (length + width)
return // 裸返回
}
// 函数作为变量
var add = func(a, b int) int {
return a + b
}
var funcMap = map[int]func(){
1: func() {
fmt.Println("登录")
},
2: func() {
fmt.Println("个人中心")
},
3: func() {
fmt.Println("注销")
},
}
funcMap[1]()参数
go中默认值传递(基本数据类型、数组、结构体等),引用传递适用于指针、切片、映射、通道等。
// &取地址,*解引用
swap(&a, &b)
func swap(x *int, y *int) {
var temp int
temp = *x
*x = *y
*y = temp
}闭包
当通过调用外部函数返回的内部函数后,被内部函数引用的外部函数的变量依然会保存在内存中,则将这些外部函数变量和内部函数组合称为闭包。
func awaitAdd(t int) func(...int) int {
time.Sleep(time.Duration(t) * time.Second)
return func(numList ...int) int {
var sum int
for _, i2 := range numList {
sum += i2
}
return sum
}
}
func main() {
fmt.Println(awaitAdd(2)(1, 2, 3))
}init
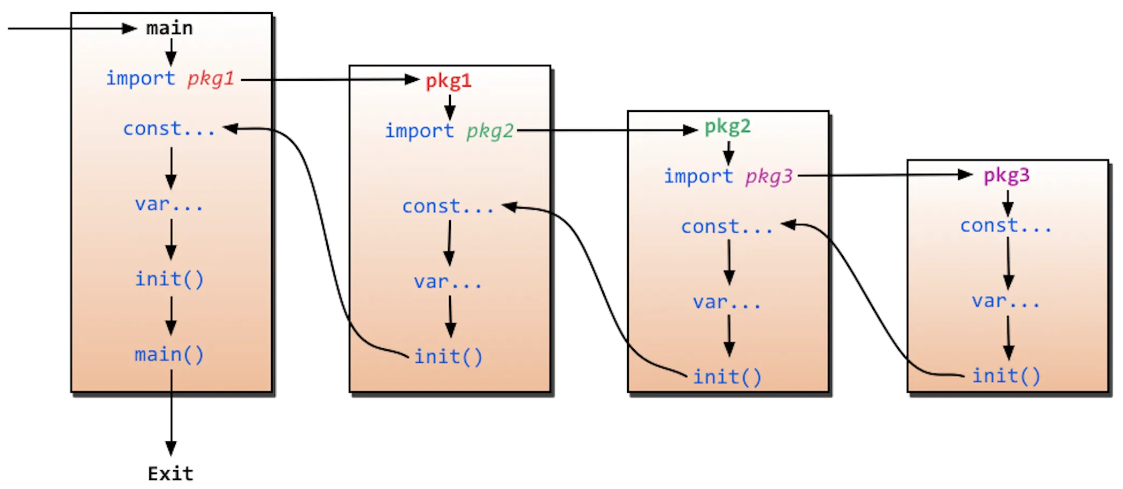
go中保留函数:init(所有包)和 main(仅 main包),他们在定义时不能有任何的参数和返回值。程序从main函数开始执行,递归实现导包—常量定义—变量定义—init函数执行 (一个包会被多个包同时导入,其只会被导入一次)
defer
在函数return后或者panic后调用,用于释放占用的资源、捕捉处理异常、输出日志等,如果一个函数中有多个defer语句,按栈的顺序调用。
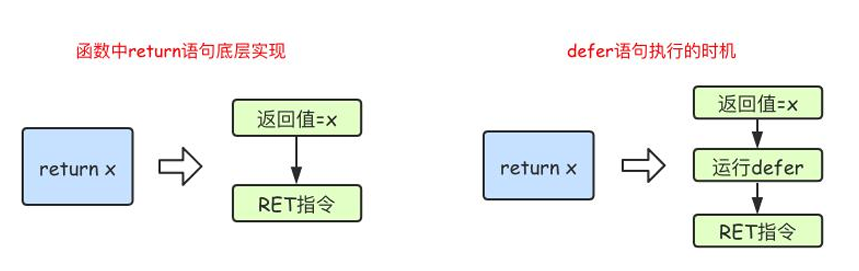
func multipleDefers() {
defer fmt.Println("后执行")
defer fmt.Println("先执行")
}异常处理
error
用于处理可预见的、程序应该能够处理的错误,即业务异常。
error接口
内置接口,任何实现该接口的类型,都可以作为 error 使用。
type error interface {
Error() string
}Go 中,错误被看作一个普通的值,通常是函数的最后一个返回值。而调用者必须检查这个 error 值
// 一个典型的函数,成功时返回结果,失败时返回 error
func Divide(a, b float64) (float64, error) {
if b == 0 {
// 返回一个零值和一个错误
return 0, errors.New("division by zero")
}
// 返回结果和一个 nil 错误,表示成功
return a / b, nil
}
result, err := Divide(10, 0)
if err != nil {
// 处理错误:打印、记录日志、返回给上层等
fmt.Println("计算出错:", err)
return
}
// 如果 err 是 nil,说明函数调用成功,可以安全使用 result
fmt.Println("计算结果:", result)基本方法
用于创建简单的、静态的字符串错误。
err := errors.New("一个简单的错误")用于创建带有格式化字符串的错误。
err := fmt.Errorf("用户 %s 不存在", name)返回错误,并携带上下文信息。
if err != nil {
// 使用 %w 包装原始错误 err
return nil, fmt.Errorf("打开文件 %s 失败: %w", path, err)
}判断 err 链中的任何一个错误是否与 target 相等
if errors.Is(err, os.ErrNotExist) {
fmt.Println("文件不存在!") // 这会打印出来
}将 err 链中的错误转换为 target 指向的类型
// 假设我们有一个自定义错误类型
type MyError struct {
Code int
Msg string
}
func (e *MyError) Error() string {
return e.Msg
}
err := &MyError{Code: 404, Msg: "资源未找到"}
var myErr *MyError
if errors.As(err, &myErr) {
fmt.Printf("捕获到自定义错误,代码: %d, 信息: %s\n", myErr.Code, myErr.Msg)
}自定义错误接口
错误定义
// 1. 定义自定义错误结构体
type UserError struct {
Code int // 业务错误码
Message string // 错误描述
Op string // 操作名称,方便追踪
}
// 2. 实现 error 接口的 Error() 方法
func (e *UserError) Error() string {
// 可以格式化输出所有信息,或者只返回 Message
return fmt.Sprintf("Op: %s, Code: %d, Message: %s", e.Op, e.Code, e.Message)
}
// 3. 定义一些预定义的错误,方便外部调用方比较
var (
ErrUserNotFound = &UserError{Code: 1001, Message: "user not found"}
ErrInvalidPass = &UserError{Code: 1002, Message: "invalid password"}
)
// 4. 在函数中返回自定义错误
func GetUser(id int) (*User, error) {
// 模拟用户未找到
if id == 999 {
// 可以直接返回预定义的错误
return nil, ErrUserNotFound
}
// ... 正常逻辑
return &User{ID: id, Name: "Alice"}, nil
}调用方
func main() {
user, err := GetUser(999)
if err != nil {
// 尝试将 err 转换为 *UserError 类型
var userErr *UserError
if errors.As(err, &userErr) {
// 成功!现在我们可以访问 UserError 的所有字段了
fmt.Printf("捕获到自定义错误: Code=%d, Message=%s, Op=%s\n", userErr.Code, userErr.Message, userErr.Op)
// 可以根据错误码进行不同的处理
switch userErr.Code {
case 1001:
fmt.Println("处理逻辑:用户未找到,可能需要重定向到注册页。")
case 1003:
fmt.Println("处理逻辑:输入参数无效,返回给客户端一个 400 Bad Request。")
}
} else {
// 如果不是 UserError 类型,则进行通用处理
fmt.Printf("捕获到未知错误: %v\n", err)
}
return
}
fmt.Printf("成功获取用户: %+v\n", user)
}panic和recover
panic用于运行时异常,如数组越界、内存溢出等。recover 用于“捕获”一个 panic。它只能在 defer 函数中有效。
func Demo() {
// 需要定义在错误发生之前,捕捉panic
defer func() {
// 设置recover拦截panic,并获取错误信息,如果没有panic,则返回nil
err := recover()
if err != nil {
fmt.Println(err)
}
}()
// 立即停止执行当前函数的剩余代码,开始回溯调用栈,执行所有被 defer 的语句。如果回溯到main 函数还没有被 recover,程序会崩溃。
panic("aaa")
}面向对象
结构体
定义及初始化
定义
// Student 定义结构体,属性名小写表示私有,大小表示公有;类型后面使用飘号添加结构体标签(键值对),可以被反射读取用于做操作
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Email string `json:"email"`
isAdmin bool `json:"isAdmin"`
}初始化
var p1 Person // 各个字段被初始化为零值,fmt.Print输出: { 0 false}
p2 := Person{"Bob", 25, "bob@email.com", false} // 按顺序初始化,需全部字段
p3 := Person{Name: "Charlie",} // 指定字段赋值,未指定则使用默认值(最后一个键值对结尾也需要逗号)
p4 := new(Person) // 使用new创建,获得指针
pPtr := &Person{Name: "Bob"} // 等价与new
(*p4).Name = "David"
p4.Name = "David" // 指针类型也可以使用点访问属性,编译器自动解引用嵌套匿名结构体
type Person struct {
Name string
Age int
Contact struct { // 匿名结构体
Phone string
Email string
}
}
// 分步初始化匿名结构体字段
p := Person{
Name: "张三",
Age: 30,
}
p.Contact.Phone = "13800138000"
p.Contact.Email = "zhangsan@example.com"
// 需要重新定义匿名结构体类型
p := Person{
Name: "李四",
Age: 25,
Contact: struct {
Phone string
Email string
}{
Phone: "13900139000",
Email: "lisi@example.com",
},
}组合
嵌套结构体内部可能存在相同的字段名,此时需要指定具体路径进行访问。
具名嵌套
type Address struct {
City string
}
type Person struct {
Name string
Age int
Home Address // 具名嵌套
Work Address // 可以嵌套多个同类型结构体
}
func main() {
p := Person{
Name: "张三",
Age: 30,
Home: Address{
City: "北京"
},
Work: Address{
City: "上海"
},
}
// 通过字段名访问嵌套结构体
fmt.Println(p.Home.City) // 北京
fmt.Println(p.Work.City) // 上海
}匿名嵌套
当使用匿名嵌套时,嵌套结构体的方法会被"提升"到外层结构体(访问成员时,优先查找当前1结构体,找不到再去匿名结构体中查找)。
type Address struct {
City, State string // 同类型可以写在一行
string // 匿名字段默认采用类型名作为字段名(多个匿名字段会导致结构体字段重复)
}
type Contact struct {
Phone string
Address // 匿名字段,嵌入 Address 结构体
}
// 初始化
c := Contact{
Phone: "123-4567",
Address: Address{ // 初始化匿名字段
City: "San Francisco",
State: "CA",
},
}
// 可以通过Contact实例直接访问 Address 的字段
fmt.Println(c.Phone)
// 也可以完整的访问
fmt.Println(c.Address.City)方法
方法绑定
方法是绑定到特定类型的函数(只能为同包下的类型进行绑定)
// (p Person) 是接收者,表示这是 Person 结构体的一个方法,操作的是结构体的一个副本,无法修改原始数据
func (p Person) Greet() string {
return "Hello, my name is " + p.Name
}
// 指针接收者,可以修改原始结构体的数据
func (p *Person) HaveBirthday() {
p.Age++
}
p.HaveBirthday() // 即使 p 不是指针,编译器也会自动取地址 (&p).HaveBirthday()方法值
确定方法调用者为指定实例,不需要动态选择
type Counter struct {
count int
}
func (c *Counter) Increment() {
c.count++
fmt.Printf("Counter: %d\n", c.count)
}
func (c Counter) GetValue() int {
return c.count
}
func main() {
counter := &Counter{count: 0}
// 通过实例对象获取对应方法
inc := counter.Increment // 非指针接受者
get := counter.GetValue // 指针接受者
inc() // 直接调用,也可以作为参数进行传递
}方法表达式
用于动态选择方法的调用者
type Point struct {
x, y int
}
func (p Point) DistanceTo(other Point) float64 {
dx := p.x - other.x
dy := p.y - other.y
return math.Sqrt(float64(dx*dx + dy*dy))
}
func (p *Point) Move(dx, dy int) {
p.x += dx
p.y += dy
}
func main() {
p1 := Point{1, 2}
p2 := Point{4, 6}
// 方法表达式
distanceFunc := Point.DistanceTo // 类型: func(Point, Point) float64
moveFunc := (*Point).Move // 类型: func(*Point, int, int)
// 使用方法表达式,需要显式传递接收者
dist := distanceFunc(p1, p2)
moveFunc(&p1, 3, 4)
}断言与接口
断言
所有类型都实现了interface{}的接口(包括基本数据类型、自定结构体),所以使用这个接口可以接受任意类型变量,但是将其进行转换为其他类型时,需要进行断言。
// any 是interface{}的类型别名
type any = interface{}
var slice = []any{"张三", 20, true, 32.2} // 存储任意类型
var v interface{} // 使用any,没有指定具体类型,则默认为nil
// 断言为其他类型
var a interface{}
value := a.(T) // 单返回值,如果断言成功,value 是 a 转换为 T 类型的值。如果断言失败,则会触发 panic。
value, ok := a.(T) // 多返回值,若成功则ok为true,value为对应值,不会触发panic
// 配合Switch语句进行匹配
var t interface{}
t = functionOfSomeType()
switch t := t.(type) {
default:
fmt.Printf("unexpected type %T", t)
case bool:
fmt.Printf("boolean %t\n", t)
case int:
fmt.Printf("integer %d\n", t)
}
// 配合if使用
if x == nil {
return "NULL"
} else if _, ok := x.(int); ok {
return fmt.Sprintf("%d", x)
} else if _, ok := x.(uint); ok {
return fmt.Sprintf("%d", x)
} else {
panic(fmt.Sprintf("unexpected type %T: %v", x, x))
}接口
接口是一组方法定义的集合,不能包含变量,一个类型实现了接口的所有方法即实现了该接口
type SayInterface interface {
say()
}
type MoveInterface interface {
move()
}
// 定义接口,支持将多个接口组合成新接口
type Animal interface {
SayInterface
MoveInterface
}
// Chicken 中实现了Animal接口的所有方法
type Chicken struct {
Name string
}
func (c Chicken) say() {
fmt.Println("chicken say")
}
func (c Chicken) move() {
fmt.Println("chicken move")
}
func main() {
// 实现了多态
var animal Animal = Chicken{"ik"}
animal.say()
}反射
在程序编译期将变量的反射信息,如字段名称、类型信息、 结构体信息等整合到可执行文件中,并给程序提供接口访问反射信息,反射的核心就是让程序在运行阶段(非编写阶段),检查类型信息、操作对象值、动态调用方法。
接口值与反射对象
接口值到反射
reflect.TypeOf 和 reflect.ValueOf 其接受具体类型变量,Go 会将其转化为interface{} 值,通过反射库再从这个接口值中拆解出反射类型(reflect.Type)和 反射值(reflect.Value)。
- reflect.Type:包含了 Go 类型所有的静态信息(运行时类型信息),比如类型的名称(
string)、种类(Kind)、字段、方法等。 - reflect.Value:作为一个 Go 值的副本,你可以通过它来获取、设置这个值,甚至调用它的方法。
t := reflect.TypeOf(x) // 获取类型对象
v := reflect.ValueOf(x) // 获取值对象反射对象到接口值
通过 reflect.Value 的 Interface() 方法,将反射值还原成一个 interface{} ,再断言为具体类型。
// 先获取反射对象
v := reflect.ValueOf(original)
// 再从反射对象转回接口值
recovered := v.Interface().(string)修改反射对象
var num int = 10
// 错误示例,传递值
v1 := reflect.ValueOf(num)
v1.SetInt(20) // 这里会panic,因为v1是不可设置的
// 正确示例:传递指针
v2 := reflect.ValueOf(&num).Elem() // Elem()获取指针指向的值
v2.SetInt(20)类型反射
// 基本信息
// 返回类型的底层种类,Int、Bool、Slice、Array、Map、Struct、Func等,自定义类型会返回底层实际类型。
Kind() Kind
// 返回类型的名称。对于命名类型返回其名称(自定义类型会返回定义的名称),对于匿名类型、内置复合类型(切片 / 映射 / 指针等),则返回空字符串 ""
Name() string
// 返回类型定义的包路径。对于内置类型和未命名类型返回空字符串
PkgPath() string
// 返回该类型的值是否可以使用 == 和 != 运算符进行比较
Comparable() bool
// 返回类型的字符串表示,包含包路径
func (t Type) String() string
// 返回类型所需的字节数
func (t Type) Size() uintptr
// 复合类型方法
// 对于指针、数组、切片、映射、通道,返回元素类型
func (t Type) Elem() Type
// 对于映射,返回键类型
func (t Type) Key() Type
// 对于数组,返回长度
func (t Type) Len() int
// 结构体相关方法
// 返回结构体字段数量
func (t Type) NumField() int
// 返回指定索引的字段信息
func (t Type) Field(i int) StructField
// 按名称查找字段
func (t Type) FieldByName(name string) (StructField, bool)
// 按索引链查找嵌套字段
func (t Type) FieldByIndex(index []int) StructField
// StructField 类型相关信息
type StructField struct {
Name string //Name是字段的名字
PkgPath string //PkgPath是非导出字段的包路径,对导出字段该字段为""
Type Type //字段的类型
Tag StructTag //字段的标签
Offset uintptr //字段在结构体中的字节偏移量
Index []int //用于Type.FieldByIndex时的索引切片
Anonymous bool //是否匿名字段
}
// 函数相关
// 返回参数数量
func (t Type) NumIn() int
// 返回返回值数量
func (t Type) NumOut() int
// 返回第i个参数类型
func (t Type) In(i int) Type
// 返回第i个返回值类型
func (t Type) Out(i int) Type
// 判断是否为可变参数函数
func (t Type) IsVariadic() bool
// 方法相关
// 返回方法数量
func (t Type) NumMethod() int
// 返回第i个方法
func (t Type) Method(int) Method
// 按名称查找方法
func (t Type) MethodByName(string) (Method, bool)
// 类型关系检查
// 判断是否实现了指定接口
func (t Type) Implements(u Type) bool
// 判断是否可以赋值给指定类型
func (t Type) AssignableTo(u Type) bool
// 判断是否可以转换为指定类型
func (t Type) ConvertibleTo(u Type) bool
// 判断类型是否可比较
func (t Type) Comparable() bool值反射
// 基本信息
// Kind返回值的种类
func (v Value) Kind() Kind
// Type返回值的类型
func (v Value) Type() Type
// Interface将值转换为interface{}
func (v Value) Interface() interface{}
// String返回值的字符串表示
func (v Value) String() string
// 值状态检查
// IsValid判断值是否有效
func (v Value) IsValid() bool
// IsNil判断值是否为nil
func (v Value) IsNil() bool
// IsZero判断值是否为零值
func (v Value) IsZero() bool
// CanAddr判断值是否可获取地址
func (v Value) CanAddr() bool
// CanSet判断值是否可设置,临时变量、常量、私有变量、反射不存在的字段等返回false
func (v Value) CanSet() bool
// CanInterface判断值是否可转换为interface{}
func (v Value) CanInterface() bool
// 基本值类型操作
// 转为数值类型
func (v Value) Int() int64
func (v Value) Uint() uint64
func (v Value) Float() float64
func (v Value) Complex() complex128
func (v Value) Bool() bool
// 设置数值
func (v Value) SetInt(x int64)
func (v Value) SetUint(x uint64)
func (v Value) SetFloat(x float64)
func (v Value) SetComplex(x complex128)
func (v Value) SetBool(x bool)
// 字符串相关
func (v Value) String() string
func (v Value) SetString(x string)
func (v Value) Bytes() []byte
func (v Value) Len() int // 字符串/数组/切片/映射长度
// 复合类型操作
// 指针相关
func (v Value) Pointer() uintptr
func (v Value) UnsafeAddr() uintptr
func (v Value) Addr() Value
func (v Value) Elem() Value // 获取指针指向的值
// 切片和数组
func (v Value) Index(i int) Value
func (v Value) Slice(i, j int) Value
func (v Value) Slice3(i, j, k int) Value
func (v Value) Cap() int
func (v Value) SetCap(int) // 仅限切片
// 映射
func (v Value) MapIndex(key Value) Value
func (v Value) MapKeys() []Value
func (v Value) SetMapIndex(key, val Value)
func (v Value) MapRange() *MapIter
// 结构体
func (v Value) Field(i int) Value
func (v Value) FieldByName(name string) Value
func (v Value) FieldByNameFunc(match func(string) bool) Value
func (v Value) FieldByIndex(index []int) Value
// 通道
func (v Value) Send(x Value)
func (v Value) Recv() (x Value, ok bool)
func (v Value) TryRecv() (x Value, ok bool)
func (v Value) TrySend(x Value) bool
func (v Value) Close()
// 函数调用
// Call调用函数
func (v Value) Call(in []Value) []Value
// CallSlice调用可变参数函数
func (v Value) CallSlice(in []Value) []Value
// NumMethod返回方法数量
func (v Value) NumMethod() int
// Method按索引获取方法值
func (v Value) Method(int) Value
// MethodByName按名称获取方法值
func (v Value) MethodByName(string) Value案例
有效判断
IsValid() bool:判断当前的 reflect.Value 是否指向一个实际存在的 Go 数据值
- 直接声明的零值:var v2 reflect.Value
- 获取nil的反射值:reflect.ValueOf(nil)、var a any reflect.ValueOf(a)
- 通过反射查找不存在的成员
- 对 map 访问不存在的 key
IsNil() bool:判断反射值指向的引用类型值是否为 nil。仅适用于特定的引用类型(指针、接口、slice、map、chan、func等),非目标类型调用会直接 panic。
IsZero() bool:判断反射值指向的 Go 数据值是否为该类型的零值(如 int=0、string=""、指针=nil)
func safeOperation(v reflect.Value) {
// 第一步:总是先检查IsValid
if !v.IsValid() {
// 值无效,直接返回
return
}
// 第二步:检查是否可以nil且是否为nil
if canBeNil(v.Kind()) && v.IsNil() {
// 处理nil情况
return
}
// 第三步:检查是否为零值
if v.IsZero() {
// 处理零值情况
return
}
// 安全操作
// ...
}
func canBeNil(kind reflect.Kind) bool {
switch kind {
case reflect.Ptr, reflect.Interface, reflect.Slice,
reflect.Map, reflect.Chan, reflect.Func:
return true
}
return false
}设置值
func main() {
var num float64 = 1.2345
// 参数必须是指针才能修改其值
pointer := reflect.ValueOf(&num)
newValue := pointer.Elem() // 通过指针获取指向元素
newValue.SetFloat(77) // 重新赋值
pointer = reflect.ValueOf(num)
newValue = pointer.Elem() // 如果非指针,这里直接panic,“panic: reflect: call of reflect.Value.Elem on float64 Value”
}动态调用方法
// 动态调用对象方法
func callMethod(obj interface{}, methodName string, args ...interface{}) []interface{} {
v := reflect.ValueOf(obj)
method := v.MethodByName(methodName)
if !method.IsValid() {
panic(fmt.Sprintf("方法 %s 不存在", methodName))
}
// 准备参数
in := make([]reflect.Value, len(args))
for i, arg := range args {
in[i] = reflect.ValueOf(arg)
}
// 调用方法
result := method.Call(in)
// 转换返回值
out := make([]interface{}, len(result))
for i, val := range result {
out[i] = val.Interface()
}
return out
}
func main() {
calc := &Calculator{}
// 动态调用Add方法
result1 := callMethod(calc, "Add", 10, 20)
// 动态调用Multiply方法
result2 := callMethod(calc, "Multiply", 5, 6)
// 动态调用Greet方法
result3 := callMethod(calc, "Greet", "World")
}标签解析
type User struct {
ID int `json:"id" db:"user_id"`
Username string `json:"username" db:"user_name"`
Email string `json:"email,omitempty" db:"email_address"`
Password string `json:"-" db:"password_hash"` // 不导出到JSON
}
// 解析结构体标签
func parseStructTags(s interface{}) {
t := reflect.TypeOf(s).Elem()
for i := 0; i < t.NumField(); i++ {
field := t.Field(i)
jsonTag := field.Tag.Get("json")
dbTag := field.Tag.Get("db")
}
}
func main() {
user := User{
ID: 1,
Username: "john_doe",
Email: "john@example.com",
Password: "secret",
}
// 解析标签
parseStructTags(&user)
}泛型
- 类型参数(如
T),泛型可处理多种数据类型;而类型约束(如int | float64)则能精确限定这些类型的范围。 - 泛型函数的返回类型可与输入类型直接关联,相较于interface不需要类型断言,将类型安全从运行时前置到编译时。
类型参数
在函数或类型定义中,使用方括号声明类型参数:
// 泛型函数
type MyInt1 int
type MyInt2 = int
// T的类型可以为int或者float64(不能是MyInt1,可以是MyInt2),U的类型需要实现comparable接口
func Pair[T int | float64, U comparable](first T, second U) {
fmt.Println(first, second)
}
// 有 ~ :允许底层类型为 int 的所有类型,包括 MyInt1
func Pair[T ~int | ~float64, U comparable](first T, second U) {
fmt.Println(first, second)
}
// 泛型结构体
type Stack[T any] struct {
elements []T
}
func(c*Stack[T])Set(valueT){
c.value=value
}
//泛型接口
typeUsber[Tany]interface{
GetDevice()T//添加一个获取具体设备的方法
}类型约束
// 约束类型范围
type Number interface {
int | float64
}
func Add[T Number](a, b T) T {
return a + b
}原理
Go编译器会将类型按GCShape分组,主要依据类型的基础类型或是否为指针(java会直接将泛型擦除为Object,用时再转换):
基础类型(如int、float64)各自独立生成代码。
go// 当调用Add[int](1, 2)和Add[float64](1.1, 2.2)时,编译器会生成两个版本的函数:一个处理int,一个处理float64。 func Add[T int | float64](a, b T) T { return a + b }所有指针类型(如int、string、*bytes.Buffer)共享同一份代码,因为它们在内存布局上相似。
gofunc Do[T any](v T) { ... } // 当多个类型共享同一份代码时(如指针类型),Go编译器会通过字典来传递类型相关的元数据(类型信息等)。上方代码调用会被改写为如下 func Do(v any, dict *typeDictionary) { ... }
协程
实现机制
模型架构
协程是GoLang语言设计的一部分,底层运行时直接、原生支持。goLang协程底层采用 GMP 模型,。
- G (Goroutine):协程(即要执行的代码单元),运行时通过一个结构体,记录了协程的栈、状态、程序计数器等信息。
- M (Machine/OS Thread):系统线程,真正在 CPU 上执行代码的实体。Go 运行时会根据需要创建或销毁 M。
- P (Processor/Context):执行上下文,P 维护了一个可运行的 Goroutine 队列。M 必须获得一个 P 才能执行 G。
每个 P 都有一个本地的 Goroutine 运行队列。当一个 go func() 被调用时,新的 G 会被创建并放入某个 P 的本地队列中。
- 本地队列:优先从这里获取 G。好处是无锁,访问速度快。
- 全局队列:所有 P 共享的队列。当本地队列满了(默认容量为 256),新的 G 会被放入全局队列。
- 工作窃取:当一个 P 的本地队列为空时,它会“随机”选择另一个 P,从其本地队列的尾部“偷”走一半的 G 到自己的队列中。从尾部偷可以减少锁竞争。
Go 运行着一个特殊的 Goroutine,不与任何 P 绑定的 M,叫做 sysmon(系统监控)。它的职责包括:
- 抢占长时间运行的 Goroutine:如果一个 G 在一个 M 上运行超过 10ms(非精确值),
sysmon会标记它,让它在函数调用的入口处有机会被抢占,让出 M,给其他 G 运行的机会。 - 回收因系统调用阻塞过久的 M。
- 向空闲的 P 注入任务,防止它们空转。
每个新创建的 Goroutine 默认只分配 2KB 的栈空间(对比线程的 MB 级)。
- 如果函数调用层级很深或使用了大量局部变量,导致栈空间不足,Go 运行时会自动为这个 G 分配一块新的、更大的栈内存,并把旧栈的内容复制过去。
- 当栈空间使用率很低时,运行时也可能在垃圾回收时收缩栈的大小。
调度场景
系统调用阻塞
当一个 Goroutine(G)执行了一个会导致阻塞的系统调用(如文件 I/O等)
- G 在 M 上执行,发起系统调用,M 和 G 一起被操作系统阻塞。
- Go 运行时检测到这种情况,会将这个 M 和它关联的 P 解绑。
- 这个 P 会被分配给另一个空闲的 M(或者新建一个 M),去继续执行 P 队列里的其他 G。
- 当那个系统调用结束时,原来的 G 会尝试“获取”一个 P 来继续执行。如果获取不到,它会被放入全局队列,等待其他 M 来执行。
网络调用阻塞
当一个 Goroutine(G)执行了一个网络 I/O 操作(还有channel、time.Sleep等),它将会使用网络轮询器。
- 当 G 进行网络操作(如
conn.Read())时,如果数据还没准备好,Go 调度器不会让 M 阻塞等待。 - 它会把这个 G 从 P 的运行队列中移除,并告诉Netpoller(网络轮询器,基于 epoll/kqueue/IOCP):“当这个连接上有数据时,请通知我”。
- 然后,M 就可以立即去执行 P 队列里的下一个 G。
- 当网络轮询器检测到数据准备好了,它会把这个 G 重新放回某个 P 的队列中,等待被再次执行。
虚拟线程
模型架构
主要通过重写方法支持虚拟线程,如sleep、socket等。Java 虚拟线程的底层实现被称为载体线程模型
- 虚拟线程:一个
java.lang.Thread的实例,它只包含任务的元数据和调度所需的状态。 - 载体线程:这是真正在 CPU 上执行代码的操作系统线程。它是一个普通的平台线程,通常来自于一个专门的线程池。
- 调度器:负责将虚拟线程调度到载体线程上运行,默认是一个
ForkJoinPool。
虚拟线程在处理阻塞时,通过Continuation (编程语言层面的概念,它代表了一段可以被暂停和恢复的计算。)处理,它能够捕获一个虚拟线程的整个调用栈(包括所有的局部变量、程序计数器等),并将其打包保存。
yield(暂停/出栈):- 当一个虚拟线程在载体线程上运行,并遇到一个阻塞操作(如文件 I/O)时,JVM 会执行
Continuation.yield()。 - 这个操作会“冻结”当前虚拟线程的执行状态,将它的调用栈完整地保存到 Java 堆内存中。
- 执行完
yield后,虚拟线程就从载体线程上“卸载”下来。载体线程此时变得“干净”了,可以被调度器拿去执行其他虚拟线程。
- 当一个虚拟线程在载体线程上运行,并遇到一个阻塞操作(如文件 I/O)时,JVM 会执行
run(恢复/入栈):- 当那个阻塞操作完成后(比如文件数据已经准备好了),JVM 会收到通知。
- 它会找到之前保存在堆内存中的那个
Continuation“存档”。 - 调度器会从线程池中拿出一个空闲的载体线程(可能是之前那个,也可能是另一个),将这个“存档”“挂载”上去。
- 然后执行
Continuation.run(),虚拟线程就从之前暂停的那个点无缝地继续执行,就好像什么都没发生过一样。
调度场景
- 对于网络 I/O:JVM 几乎总是使用非阻塞套接字 +
epoll/kqueue等多路复用器。这是最高效的方式。 - 对于文件 I/O:
- 在支持
io_uring的现代 Linux 系统上,JVM 会使用io_uring,这使得文件 I/O 的处理方式和网络 I/O 几乎完全一样,实现了真正的异步。 - 在较旧的系统上,JVM 可能会采用一个“备用方案”:使用一个专门的载体线程池来执行这些阻塞的文件 I/O 调用。但即便如此,对于主调度器来说,虚拟线程仍然是“被卸载”了,并没有阻塞主要的计算线程池。
- 在支持
基本使用
启动方式
main称为主协程,如果主协程退出了,那么程序会立即终止,所有其他协程都会被强制结束。
func sayHello(msg string) {
fmt.Printf(msg)
}
func main() {
// 启动一个协程来执行 sayHello
go sayHello("World")
// 匿名函数协程
go func(msg string) {
fmt.Println(msg)
runtime.Goexit() // 立即终止当前 goroutine 执⾏,defer依旧会执行
}("Hello World")
time.Sleep(150 * time.Millisecond)
}设置运行核心数
运行调度器使用GOMAXPROCS参数确定执行 Go 的内核线程,默认是CPU逻辑核心数。
func main() {
//获取当前计算机上面的Cup个数
cpuNum := runtime.NumCPU()
//可以自己设置使用多个cpu
runtime.GOMAXPROCS(cpuNum - 1)
}Channel
概述
缓冲类型
// 创建无缓冲channel,执行同步,发送操作会阻塞,直到接收操作被执行。反之,接收操作也会阻塞,直到发送操作被执行。
ch := make(chan int)
// 创建有缓冲channel,只有当缓冲区满时,发送操作才会阻塞;只有当缓冲区空时,接收操作才会阻塞。
ch := make(chan int, 10) // 缓冲区容量为10数据流向
双向channel可以看做单向channel的基类,make出来的都是双向。
// 双向channel,可读可写
var ch chan int = make(chan int)
// 只读channel,仅读
var readOnly <-chan int = make(<-chan int)
// 只写channel,仅写
var writeOnly chan<- int = make(chan<- int)操作
close
- 关闭后不能再发送:向一个已经关闭的 Channel 发送数据会导致 panic(重复关闭也会导致panic)。
- 关闭后仍可读取:channel关闭后,若其中仍有数据,则会返回剩余值。若不存在数据,再次接收会返回该类型的零值。
// 关闭管道
close(ch)
// 判断 Channel 是否关闭,若无元素且chan关闭,则ok返回false(若未关闭且无元素则阻塞)
v, ok := <-ch发送与读取
// 发送数据
ch <- 42
// 接收数据,若通道
value, ok := <-chrange
当 Channel 发送方被关闭,且所有数据都被接收完毕后,循环会自动退出。
for value := range ch {
// 处理 value
}select
select 语句每个 case 都是一个 Channel 的发送或接收操作,其会阻塞,直到其中一个 case 可以执行,执行后退出select。
- 如果多个 case 同时就绪,
select会 随机选择 一个执行。 - 如果没有 case 就绪,但有
default分支,则会执行default分支(非阻塞)。 - 如果没有 case 就绪,也没有
default分支,select会阻塞。
// 超时控制。如果 1 秒内 ch 没有数据,就会执行超时的 case。
select {
case msg := <-ch:
fmt.Println("接收到消息:", msg)
// time.After是一个chan,会阻塞指定时长,然后返回具体时间
case <-time.After(1 * time.Second): // 1秒后超时
fmt.Println("操作超时!")
}
// 永久阻塞
select {}
// 如果一个 case 中的 Channel 是 nil,那么这个 case 将永远不会被选中,用于动态禁用分支
var sendCh chan int // sendCh 是 nil
for i := 0; i < 5; i++ {
select {
case sendCh <- i: // 因为 sendCh 是 nil,这个 case 永远不会执行
fmt.Println("Sent:", i)
default:
fmt.Println("Channel is disabled, value", i, "is dropped")
}
}
// 结合for,通过监听退出信号退出
for {
select {
case <-quit: // 监听退出信号
fmt.Printf("%s 收到退出信号,正在停止...\n", name)
return
default:
fmt.Printf("%s 正在工作中...\n", name)
time.Sleep(500 * time.Millisecond)
}
}其他
len(ch) // 求取缓冲区中剩余元素个数
cap(ch) // 求取缓冲区元素容量大小。Context
用于解决跨 API 和 Goroutine 的数据传递、超时、取消问题而设计的。
- 根节点:每个请求处理流程的入口处创建一个根 Context。
- 派生节点:从这个根 Context 可以派生出子 Context。每个子 Context 可以基于父 Context 添加新的功能,如设置超时、设置取消信号或附加键值对。
- 信号传播:当父 Context 被取消(无论是超时还是主动)时,这个取消信号会自动传播给所有派生出的子 Context。
根节点
- context.Background():所有 Context 的根。它是一个空的、永远不会被取消的、没有值的、没有截止日期的 Context。通常用在 main 函数、请求的入口
- context.TODO():功能上和Background()一样,区别在于语义上,用于表明:“这里的代码还没完成,我暂时需要一个 Context,但还没确定应该从哪里获取它”。
派生节点
WithCancel( 实现主动取消)
func WithCancel(parent Context) (ctx Context, cancel CancelFunc):返回一个子 Context 和一个 CancelFunc。调用这个 CancelFunc 会触发取消信号,Context可以监听这个取消信号。
func main() {
// 创建一个可取消的 context
ctx, cancel := context.WithCancel(context.Background())
go func() {
for {
select {
// 在任何可能被阻塞的操作(如网络请求、I/O 操作、time.Sleep)前,都应该检查 ctx.Done() 是否已关闭,以便及时响应取消信号。
case <-ctx.Done(): // 监听取消信号
fmt.Println("Goroutine 收到取消信号,退出。")
return
default:
fmt.Println("Goroutine 正在工作中...")
}
}
}()
fmt.Println("主程序决定取消任务。")
cancel() // 发出取消信号
time.Sleep(1 * time.Second)
}WithTimeout/WithDeadline(实现超时控制)
WithTimeout(parent Context, timeout time.Duration):设置一个相对的超时时间,通过Context可以监听这个取消信号。WithDeadline(parent Context, deadline time.Time):设置一个绝对的截止时间,通过Context可以监听这个取消信号。
func main() {
// 创建一个带超时的 context,2秒后自动取消
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel() // 确保提前退出也会关闭Context,而不会继续等待超时,减少资源浪费。(取消操作时幂等的)
go doSomething(ctx)
select {
case <-ctx.Done():
fmt.Println("主程序: ctx.Done() channel 关闭,原因:", ctx.Err()) // 会打印 "context deadline exceeded"
}
}
func doSomething(ctx context.Context) {
select {
case <-time.After(3 * time.Second): // 模拟一个耗时3秒的操作
fmt.Println("操作完成")
case <-ctx.Done(): // 如果在3秒内 context 被取消(这里是2秒超时)
fmt.Println("操作被取消,原因:", ctx.Err())
}
}
WithValue(传递请求范围数据)
func WithValue(parent Context, key, val interface{}) Context: 用于在 Context 中存储键值对,用于传递请求ID 、用户身份信息等元信息。
// 定义一个不导出的类型作为 key,避免冲突
type contextKey string
const userIDKey contextKey = "userID"
func main() {
ctx := context.WithValue(context.Background(), userIDKey, "user-12345")
handleRequest(ctx)
}
func handleRequest(ctx context.Context) {
userID := ctx.Value(userIDKey).(string) // 类型断言
fmt.Printf("处理请求,用户ID: %s\n", userID)
// 在下游函数中继续使用
processUser(ctx)
}
func processUser(ctx context.Context) {
userID := ctx.Value(userIDKey).(string)
fmt.Printf("处理用户 %s 的数据...\n", userID)
}组合
context 的设计哲学是组合,可以通过链式地将不同功能“附加”到一个 Context 上。
// --- 步骤 1: 定义用于传值的 Key,防止冲突 ---
type contextKey string
const (
userIDKey contextKey = "userID"
requestIDKey contextKey = "requestID"
)
// --- 模拟一个耗时的数据库查询 ---
func databaseQuery(ctx context.Context) {
// 模拟一个耗时操作,可能超过请求的超时时间
select {
case <-time.After(5 * time.Second): // 假设查询需要5秒
fmt.Println("[DB Query] 查询成功完成!")
case <-ctx.Done(): // 关键:监听 context 的取消信号
// 如果请求超时或被取消,这里会立即执行
fmt.Printf("[DB Query] 查询被取消,原因: %v\n", ctx.Err())
}
}
// --- 模拟业务处理逻辑 ---
func handleRequest(ctx context.Context) {
// 调用更下游的服务(如数据库)
databaseQuery(ctx)
}
func main() {
// --- 步骤 2: 构建一个组合了所有功能的 Context ---
// 创建根 Context
rootCtx := context.Background()
// 附加请求范围的数据 (传值)
ctxWithValue := context.WithValue(rootCtx, userIDKey, "user-12345")
ctxWithValue = context.WithValue(ctxWithValue, requestIDKey, "req-abcde")
// 在已有数据的基础上,添加超时控制 (超时)
ctx, cancel := context.WithTimeout(ctxWithValue, 3*time.Second)
defer cancel() // 最佳实践:确保资源被释放
// --- 步骤 3: 启动业务处理 ---
go handleRequest(ctx)
// --- 步骤 5: 主 Goroutine 等待 Context 的结束信号 ---
select {
case <-ctx.Done():
// 当 context 被取消(超时或手动取消)时,这里的代码会执行
fmt.Printf("主程序: 请求结束,原因: %v\n", ctx.Err())
}
}原理
Context
作为父接口,不做实现,不同的 Context 类型(用于取消、超时、传值)只需要实现这四个方法中它们关心的部分。
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}emptyCtx
这是 context.Background() 和 context.TODO() 返回的类型,作为整个 Context 树的根节点。
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key interface{}) interface{} {
return nil
}valueCtx
调用WithValue(parent)创建一个valueCtx, 其不会修改原有的 Context,而是创建一个新的 valueCtx 节点,链接到父节点上。原有的 Context 保持不变。
- 它先检查传入的 key 是否等于自己存储的 key。如果是,就返回自己的 val。
- 如果不是,它就调用父 Context 的 Value 方法(即 c.Context.Value(key)),把请求向上传递,直到找到匹配的 key 或到达根节点(emptyCtx)。
type valueCtx struct {
Context // 嵌入父 Context
key, val interface{}
}因为valueCtx的链式查找行为,所以后面设置的相同key(包括类型和值),将会在使用“覆盖”前面的key(实际原先的还存在,但不会再匹配到)。
// 通过不导出类型,但是导出对应实例来作为key。
// 自定义的类型,不会和第三方库中的类型冲突,如果是基础类型可以自定义类型: type contextKey string
// 只导出唯一实例,而不导出类型,方便key被覆盖时排查问题,只需要查找该唯一实例使用的位置即可。
// 1. Key 类型不导出,外部无法创建
type userIDKey struct{}
// 2. 导出一个该类型的唯一实例(指针)
var UserID = &userIDKey{}cancelCtx
调用 context.WithCancel(parent) 时,会创建一个 cancelCtx
donechannel当
cancelCtx被创建时,done是nil。第一次调用Done()方法时,它会懒加载创建一个chan struct{}。go// 先调用 cancel(),后调用 Done() // 当发现done为nil时,将会执行下方操作,而不是close。而后Done调用时,会发现该chan已经是关闭了,获得信号。 ctx.done = closedchan // 先调用Done(),后调用cancel() // Done()中执行创建一个新的chan ctx.done = make(chan struct{}) // 调用 cancel() 关闭该chan。而后Done调用时,会发现该chan已经是关闭了,获得信号。 close(ctx.done)当
cancel()函数被调用时,这个donechannel 会被关闭。所有监听
<-ctx.Done()的 Goroutine 都会因为 channel 关闭而收到信号。
childrenmap- 当一个
cancelCtx被创建时,它会向上(向父 Context)注册自己,把自己加入到父 Context 的childrenmap 中。 - 当父 Context 的
cancel()被调用时,它会遍历自己的childrenmap,并调用每一个子 Context 的cancel()方法。
- 当一个
cancel方法- 加锁。
- 设置
err(例如context.Canceled)。 - 关闭
donechannel。 - 遍历
children,递归地取消所有子节点。 - 从父 Context 的
childrenmap 中移除自己。
type cancelCtx struct {
Context // 嵌入父 Context
mu sync.Mutex // 互斥锁,保证并发安全
done chan struct{} // 用于通知取消的 channel
children map[canceler]struct{} // 存储所有可取消的子 Context
err error // 取消原因
}timerCtx
调用context.WithTimeout(),会创建一个timerCtx,嵌入了 time.Timer 以及 cancelCtx(具备所有取消和传播的能力)。
- 自动取消:当
Timer到期时,它会调用timerCtx的cancel()方法,从而触发整个取消链式反应。 - 手动取消:如果你手动调用的
cancel()函数,它会先停止Timer(防止资源泄漏),然后调用嵌入的cancelCtx的cancel()方法。
type timerCtx struct {
cancelCtx // 嵌入 cancelCtx
timer *time.Timer // 定时器
}同步与锁
同步
WaitGroup:等待一组子协程全部执行完毕后再退出。
Add(int): 计数器增加int的值。Done(): 计数器减1(通常在defer语句中使用)。Wait(): 阻塞当前协程,直到计数器变为0。
func worker(id int, wg *sync.WaitGroup) {
defer wg.Done() // 在函数退出时调用,确保计数器减1
time.Sleep(time.Second) // 模拟耗时工作
}
func main() {
var wg sync.WaitGroup
for i := 1; i <= 5; i++ {
wg.Add(1) // 启动一个协程前,计数器加1
go worker(i, &wg)
}
wg.Wait() // 等待所有协程完成(计数器归零)
}CAS
原子操作
操作要么完全执行,要么完全不执行,不会被其他goroutine中断。
counter++包含“读取-修改-写入”三个步骤。在多线程环境下,这三个步骤可能被交错执行,导致结果错误。sync.Mutex通过加锁的方式,强制这三个步骤作为一个整体(临界区)被执行,从而保证了原子性。sync/atomic直接提供硬件级别的原子指令来完成“读取-修改-写入”这一组合操作,从而避免了使用锁带来的开销(如内核态切换、线程阻塞等)。
内存屏障
- 阻止重排,即屏障之前的所有内存操作,必须先于屏障之后的所有内存操作执行并完成。
- 保证可见性,强制 CPU 将写缓冲区中的所有数据刷新到主内存,并(或)使当前 CPU 核心的缓存失效,强制从主内存中重新加载数据。
- 写屏障(Release屏障):确保所有在屏障之前的写操作,其结果都对其他处理器可见。
- 读屏障(获取屏障):确保所有在屏障之后的读操作,都能看到其他处理器最新的写操作结果。
- 全内存屏障:兼具两者功能。
// 共享变量
var a, b, flag int32
// --- Goroutine 1 (写入者) ---
func writer() {
a = 10 // 操作1:写入 a
b = 20 // 操作2:写入 b
// --- 没有内存屏障 ---
flag = 1 // 操作3:写入 flag (普通赋值)
}
// --- Goroutine 2 (读取者) ---
func reader() {
for {
// --- 没有内存屏障 ---
if flag == 1 { // 操作4:读取 flag (普通读取)
// 操作5:读取 a
fmt.Println("a =", a)
// 操作6:读取 b
fmt.Println("b =", b)
break
}
}
}编译器重排
编译器为了优化性能,可能会对指令进行重排,导致执行顺序与代码编写顺序不一致,在多线程环境下导致预期之外的结果。
// writer
// 编译器可能会认为 flag = 1 与 a = 10, b = 20 没有依赖关系。为了优化,它可能会把 flag = 1 的指令重排到 a 和 b 的赋值之前。
flag = 1; // 先设置标志
a = 10;
b = 20;
// reader
a_copy := a; // 在循环开始前就读取 a
b_copy := b; // 在循环开始前就读取 b
for {
if flag == 1 {
fmt.Println("a =", a_copy); // 使用之前读取的旧值
fmt.Println("b =", b_copy); // 使用之前读取的旧值
break
}
}CPU/处理器重排
写入过程:
writer在 CPU-0 上运行。它执行a = 10和b = 20。这些值可能被写入 CPU-0 的高速缓存中,但还没有来得及同步到主内存。- 接着,
writer执行flag = 1。这个操作可能被很快地同步到主内存,并通知其他 CPU 核心(如 CPU-1)flag的缓存行已失效。
读取过程:
reader在 CPU-1 上运行。它一直在轮询flag。当它收到flag缓存行失效的通知后,它会从主内存中重新加载flag的值,发现它变成了1。- 于是,
reader跳出循环,开始执行fmt.Println(a)和fmt.Println(b),但此时的a和b还在CPU-0 的高速缓存里,没有到达主内存,读取的是旧值。
atomic包
在 writer 中:
- 屏障之前的范围是
a = 10和b = 20,屏障本身是atomic.StoreInt32(&flag, 1)。 - 保证:CPU 和编译器必须确保
a和b的写入操作,在flag被设置为1之前完成,并且它们的值对其他 CPU 核心可见。a=10和b=20的相对顺序可能颠倒,但它们俩一定都在flag=1之前。
在 reader 中:
- 屏障本身是
atomic.LoadInt32(&flag),屏障之后的范围是fmt.Println("a =", a)和fmt.Println("b =", b)。 - 保证:当
atomic.LoadInt32(&flag)成功读取到1时,这个屏障会强制 CPU 去获取最新的数据。因此,在屏障之后读取a和b时,一定能看到writer中在屏障之前所做的所有写入(即a=10和b=20)。a和b的读取顺序也可能颠倒,但它们读到的值一定是最新的。
// 共享变量
var a, b, flag int32
// --- Goroutine 1 (写入者) ---
func writer() {
a = 10 // 操作1:写入 a
b = 20 // 操作2:写入 b
// --- 写屏障 ---
atomic.StoreInt32(&flag, 1) // 操作3:原子写入 flag (包含屏障)
}
// --- Goroutine 2 (读取者) ---
func reader() {
for {
// --- 读屏障 ---
if atomic.LoadInt32(&flag) == 1 { // 操作4:原子读取 flag (包含屏障)
// 操作5:读取 a
fmt.Println("a =", a)
// 操作6:读取 b
fmt.Println("b =", b)
break
}
}
}基本函数与类型
atomic原子操作主要针对以下类型:int32, int64,uint32, uint64,uintptr,unsafe.Pointer (通用指针)
Add 系列:增减操作
func AddInt64(addr *int64, delta int64) (new int64)- 将
delta加到*addr上,并返回新值。
Load 系列:加载(读取)操作
func LoadInt64(addr *int64) (val int64)- 原子地读取
*addr的值,在并发读取的场景下,保证你读到最新的值(配合Store使用)。
Store 系列:存储(写入)操作
func StoreInt64(addr *int64, val int64)- 原子地将
val写入*addr,配合Load通常成对使用,用于安全地设置和读取一个标志位或配置值。
Swap 系列:交换操作
func SwapInt64(addr *int64, new int64) (old int64)- 原子地将
new设置到*addr,并返回被替换掉的旧值,相当于old = *addr; *addr = new; return old;
Compare-and-Swap (CAS) 系列:比较并交换操作
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)- 它会原子地执行以下逻辑:
- 读取
*addr的当前值。 - 比较当前值是否等于
old。 - 如果相等,则将
new写入*addr,并返回true。 - 如果不相等,则什么都不做,并返回
false。
- 读取
atomic.Value
func (v *Value) Store(x interface{}): 原子地存储一个值。func (v *Value) Load() (x interface{}): 原子地加载当前的值。gotype Config struct { Endpoint string Timeout time.Duration } func main() { var config atomic.Value // 初始化配置 config.Store(Config{Endpoint: "https://api.example.com/v1", Timeout: 2 * time.Second}) var wg sync.WaitGroup // 启动多个 Goroutine 读取配置 for i := 0; i < 5; i++ { wg.Add(1) go func(id int) { // 原子地加载配置 cfg := config.Load().(Config) fmt.Printf("Reader %d: Endpoint=%s, Timeout=%v\n", id, cfg.Endpoint, cfg.Timeout) }() } // 模拟配置更新 time.Sleep(500 * time.Millisecond) newConfig := Config{Endpoint: "https://api-v2.example.com", Timeout: 5 * time.Second} config.Store(newConfig) wg.Wait() }
自旋锁案例
type SpinLock struct {
flag int32 // 0 表示未锁定, 1 表示已锁定
}
func (s *SpinLock) Lock() {
for !atomic.CompareAndSwapInt32(&s.flag, 0, 1) {
// 如果 CAS 失败,说明锁已被持有,继续“自旋”(循环等待)
// 在实际应用中,可以加入 runtime.Gosched() 让出 CPU,避免空转浪费
}
}
func (s *SpinLock) Unlock() {
// 将 flag 设置回 0
atomic.StoreInt32(&s.flag, 0)
}
func main() {
var lock SpinLock
var wg sync.WaitGroup
sharedData := 0
for i := 0; i < 10; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
lock.Lock()
fmt.Printf("Goroutine %d: Acquired lock, modifying data...\n", id)
// 模拟耗时操作
sharedData++
time.Sleep(100 * time.Millisecond)
fmt.Printf("Goroutine %d: Releasing lock.\n", id)
lock.Unlock()
}(i)
}
wg.Wait()
锁
当多个协程并发地访问和修改同一个共享数据,其结果是不可预测的,需要通过锁来限制。
互斥锁
保证在任何时刻,只有一个Goroutine能持有锁。其他试图获取锁的Goroutine将会被阻塞,直到锁被释放。
// ... (main 函数开头部分不变)
func main() {
var wg sync.WaitGroup
var mu sync.Mutex // 创建一个互斥锁
counter := 0
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
// 务必使用 defer mutex.Unlock() 来释放锁
defer wg.Done()
mu.Lock() // 在访问 counter 前加锁
counter++
mu.Unlock() // 访问结束后解锁
}()
}
wg.Wait()
}读写锁
适用于读多写少的场景,将锁的访问者分为读者和写者两类。
- 读锁(共享锁):多个Goroutine可以同时持有读锁,互不干扰。
- 写锁(排他锁/互斥锁):一次只有一个Goroutine持有写锁,获取前不能有其他读/写锁,获取后阻塞其他读/写锁。
var rwmutex sync.RWMutex
rwmutex.Lock() / rwmutex.Unlock(): 获取/释放写锁。
rwmutex.RLock() / rwmutex.RUnlock(): 获取/释放读锁。模块化
概念
包
同一目录下的go文件归属一个包,必须使用相同的package,通过 import 语句来导入,包名和目录名不强制要求完全一致
- 同一个包内:所有标识符(无论大小写)都是相互可见的。
- 跨包访问:只有首字母大写的公有标识符才能被其他包导入和使用。首字母小写的私有标识符对于外部包来说是完全不可见的。
my-project/
├── go.mod
├── main.go <-- 属于 main 包
└── utils/ <-- 这是一个目录,代表一个包
├── string.go <-- 属于 utils 包
└── math.go <-- 也属于 utils 包模块
一个或多个包的集合,这些包作为一个单元被一起版本控制和发布,模块的根目录下必须有一个 go.mod 文件。
go.mode
用于锁定go以及引用依赖的版本,跨模块访问需要使用require导入模块。
module:定义模块路径。go:指定该模块所期望的 Go 语言版本(例如go 1.21)。require:列出项目直接依赖的模块及其版本号。indirect:标记那些被间接依赖(即你的依赖所需要的依赖)的模块。
module github.com/yourname/awesome-project
go 1.21
require (
// 直接依赖
github.com/gin-gonic/gin v1.9.1
// 注释indirect表示间接依赖,即代码没有直接 import 它
golang.org/x/net v0.12.0 // indirect
)
// 4. exclude: 排除某个特定版本,Go 工具链会自动寻找一个兼容的其他版本(不能指定替换成哪个版本)
exclude github.com/some/dependency v1.0.0
// 5. replace: 替换某个模块为另一个路径或版本,可以是本地,也可以是远程
replace github.com/some/dependency => ./local-modgo.sum
用于记录每个依赖包的加密哈希值,以校验依赖包的完整性,防止依赖被篡改。
基本使用
| 命令 | 作用 |
|---|---|
| go mod init <模块路径> | 生成 go.mod 文件,go mod init github.com/yourname/calculator |
| go mod download | 下载 go.mod 文件中指明的所有依赖 |
| go mod tidy | 整理现有的依赖,添加你代码中用到的,但 go.mod 里没有的依赖。<br>删除 go.mod 里存在,但你代码中已经没用到的依赖。 |
| go mod graph | 查看现有的依赖结构 |
| go mod edit | 编辑 go.mod 文件 |
| go mod vendor | 导出项目所有的依赖到vendor目录 |
| go mod verify | 校验一个模块是否被篡改过 |
| go mod why | 查看为什么需要依赖某模块 |
依赖管理
包导入
代码中
import包,当运行go build,go run或go test时,Go 会自动查找并下载最新版本的依赖,并更新go.mod和go.sum。go// 运行 go run .,Go 会自动下载 gin 框架 import "github.com/gin-gonic/gin" func main(){ }使用
go get命令手动添加。go// 获取最新版本 go get github.com/gin-gonic/gin
导入流程
解析与查找:直接运行go get 或者运行 go run 之后扫描发现缺少依赖,隐式的执行go get。
定位于下载:Go 工具链默认不会直接去 GitHub 等源码仓库下载代码。它会先向 Go 模块代理 发起请求。
Go 向
GOPROXY请求模块(默认的代理是https://proxy.golang.org),代理找到该版本,返回模块的元数据。go// 设置代理路径,多个代理,逗号分隔 export GOPRIVATE="github.com/mycompany/*,gitlab.com/another-team/*"Go 从代理下载模块的压缩包(
.zip文件)和go.mod文件。如果代理没有这个模块,Go 会根据
GOPROXY的配置进行“回源”(默认配置是proxy.golang.org,direct,direct表示如果代理找不到,就直接去源码仓库下载)。下载的模块都会被解压并存储在本地模块缓存中,路径通常是
$GOPATH/pkg/mod,项目在编译时引用缓存中的代码。
校验与验证:Go 在下载完模块代码后,会计算其内容的加密哈希值(SHA256),然后查找go.sum文件。
- 如果存在该依赖:新下载代码的哈希与
go.sum中记录的哈希。如果一致,校验通过。如果不一致,Go 会报错并终止构建。 - 如果不存在:这是你第一次添加这个依赖。Go 会向 Go 校验和数据库 发起请求,然后对比哈希值。默认的
GOSUMDB是sum.golang.org。
- 如果存在该依赖:新下载代码的哈希与
更新源数据
go.mod:如果go.mod中没有这个依赖,会添加一个require指令。如果已有,可能会更新版本号。go.sum:如上一步所述,会追加新依赖的哈希记录。
版本控制
格式为 MAJOR.MINOR.PATCH,例如,v1.2.3。
MAJOR:不兼容的 API 修改。MINOR:向下兼容的功能性新增。PATCH:向下兼容的问题修正。
当大版本发生更新,对应的导入路径一般建议修改,因为 Go 的 import 路径必须是唯一的。如果不改变路径,用户无法同时导入一个库的 v1 和 v2 版本。
// v1.2.3:精确版本
// v1.2:最新补丁版本
// v1:最新次要版本
// latest:最新版本
// master:分支最新提交
module github.com/user/project // v1 及以下版本:模块路径中不带版本号。
module github.com/user/project/v2 // v2 及以上版本:模块路径必须带上版本后缀。多模块
假设项目中:存在两个模块,mylib 以及 myapp(依赖 mylib),当mylib更新后,myapp若想调用最新依赖。
传统模式
将
mylib的新版本发布到远程仓库使用replace指向本地
goreplace github.com/you/mylib => ../mylib // 指向本地的 mylib 目录
工作区
工作区模式就是为了解决“本地多模块开发”,不应该提交到git,因为协作开发者的路径和你的不一样,CI/CD打包也找不到对应路径。
查找并解析
go.work文件,读取对应的go.mod文件,构建对应模块的映射。模块路径 本地目录 github.com/you/myapp~/dev/myappgithub.com/you/mylib~/dev/mylib当一个模块引用了另一个模块,如
github.com/you/myapp,则会直接使用~/dev/myapp目录下的源码进行编译和链接
go.work文件
通常放在所有相关模块的公共父目录中,但理论上可以放在任何地方
// go work init (创建一个空的 go.work)
// go work use ./myapp (添加 myapp)
// 指定版本
go 1.22
// 添加模块
use (
./myapp
./mylib
)标准库
时间日期
时间获取
now := time.Now() //获取当前时间
year := now.Year() //年
month := now.Month() //月
day :=now.Day() //日
hour := now.Hour() //小时
minute := now.Minute() //分钟
second :=now.Second() //秒
timestamp1 := now.Unix() //时间戳
timestamp2 := now.UnixNano() //纳秒时间戳
timeObj := time.Unix(timestamp, 0) // 时间戳转时间,参数一为秒数,参数二为纳秒数
stamp,_:=time.ParseInLocation("2006-01-0215:04:05","2019-01-0813:50:30",time.Local) // 参数一为时间格式模板,参数二为时间,参数三为时区,返回时间的时间戳格式化
now.Format(time.RFC1123) // 使用内置模版,格式为:Mon, 02 Jan 2006 15:04:05 MST
// 2006-01-02 15:04:05:注意这不是一个时间,而是使用2006固定代替年份,01固定代替月份,02固定代替日期。
now.Format("2006-01-02") // 自定义格式模板,格式为:2023-12-25,运算
// time包定义的一个类型,它代表两个时间点之间经过的时间,以纳秒为单位,最多表示292年(用int64存储纳秒值的上限)。
const (
Nanosecond Duration=1
Microsecond =1000 *Nanosecond
Millisecond =1000 *Microsecond
Second = 1000 *Millisecond
Minute =60 * Second
Hour =60 *Minute
)
func (t Time) Add(d Duration) Time // 当前时间添加时间间隔(减少传入负数即可)
func (t Time) Sub(u Time) Duration // 如果结果超出了Duration可以表示的最大值/最小值,将返回最大值/最小值
func (t Time) Equal(u Time) bool // 判断两个时间是否相同,会考虑时区的影响,因此不同时区标准的时间也可以正确比较
func (t Time) Before(u Time) bool // t代表的时间点是否在u之前
func (t Time) After(u Time) bool // t代表的时间点是否在u之后Json转换
编码
只有可导出(首字母大写)的字段才会被编码。默认情况下,JSON中的键名就是Go结构体的字段名。
jsonData, err := json.Marshal(user)
if err != nil {
log.Fatalf("JSON编码失败: %v", err)
}解码
Unmarshal 接受解码对象的指针,JSON的键名会自动匹配Go结构体中可导出的字段名(不区分大小写,但最佳实践是保持一致)
var user User
err := json.Unmarshal([]byte(jsonString), &user) // 序列化 Go 值为紧凑的单行 JSON
err := json.MarshalIndent([]byte(jsonString), "# ", " ") // 序列化 Go 值,参数二为前缀,参数三为缩进
// 注意,第一行是没有prefix的,这是“feature”
{
// "serverPort": 8080,
// "allowedIPs": [
// "127.0.0.1",
// "::1"
// ],
// "debug": false
// }标签
- 重命名键名:
json:"new_name" - 忽略字段:
json:"-" - 如果字段为零值则忽略:
json:",omitempty"
type UserProfile struct {
UserID int `json:"user_id"` // 重命名为 user_id
Password string `json:"-"` // 忽略此字段,不出现在JSON中
Age int `json:"age,omitempty"` // 如果 Age 是 0 (空值),则忽略此字段
}动态Json
有时无法预先定义一个固定的结构体来接收JSON数据
map
bool对应 JSON booleansfloat64对应 JSON numbersstring对应 JSON strings[]interface{}对应 JSON arraysmap[string]interface{}对应 JSON objectsnil对应 JSON null
jsonString := `{
"name": "Eve",
"age": 28,
"is_student": false,
"courses": ["History", "Math"],
"address": {
"city": "New York",
"zip": "10001"
}
}`
var result interface{}
json.Unmarshal([]byte(jsonString), &result)
// 使用类型断言来访问数据
m := result.(map[string]interface{})
address := m["address"].(map[string]interface{})RawMessage
定义一个“外层”结构体,用于解析公共字段,并将不确定的 payload 字段定义为 json.RawMessage 类型。
// Envelope 是外层结构,用于捕获公共信息
type Envelope struct {
EventType string `json:"event_type"`
Timestamp string `json:"timestamp"`
Payload json.RawMessage `json:"payload"` // 关键点!
}
// UserCreatedPayload 是 "user_created" 事件的 payload 结构
type UserCreatedPayload struct {
UserID int `json:"user_id"`
Username string `json:"username"`
Email string `json:"email"`
}
// OrderPlacedPayload 是 "order_placed" 事件的 payload 结构
type OrderPlacedPayload struct {
OrderID string `json:"order_id"`
Amount float64 `json:"amount"`
Currency string `json:"currency"`
}
func processRawMessage(jsonData []byte) {
// 第一次解析:将整个 JSON 解析到 Envelope
// 此时,envelope.EventType 和 envelope.Timestamp 已被正确解析
// 而 envelope.Payload 包含了 payload 对应的原始 JSON 字节
// fmt.Printf("Raw Payload: %s\n", envelope.Payload)
var envelope Envelope
json.Unmarshal(jsonData, &envelope)
// 第二次解析:根据 EventType 将 RawMessage 解析到具体的结构体
switch envelope.EventType {
case "user_created":
var payload UserCreatedPayload
// 将 envelope.Payload (原始JSON字节) 解析到 UserCreatedPayload
json.Unmarshal(envelope.Payload, &payload)
fmt.Printf("Processed User Event: %+v\n", payload)
case "order_placed":
var payload OrderPlacedPayload
// 将 envelope.Payload (原始JSON字节) 解析到 OrderPlacedPayload
json.Unmarshal(envelope.Payload, &payload)
fmt.Printf("Processed Order Event: %+v\n", payload)
}
}流式传输
NDJSON
每一行都是一个 JSON 对象,通过换行符分割,但不是合法的Json。
// New-line Delimited JSON
{"id": 1, "name": "Alice", "score": 95}
{"id": 2, "name": "Bob", "score": 88}
{"id": 3, "name": "Charlie", "score": 100}
type User struct {
ID int `json:"id"`
Name string `json:"name"`
Score int `json:"score"`
}
func main() {
users := []User{
{ID: 1, Name: "Alice", Score: 95},
{ID: 2, Name: "Bob", Score: 88},
{ID: 3, Name: "Charlie", Score: 100},
}
// 在真实场景中,这个 buffer 可能是网络连接 (net.Conn) 或文件 (os.File)
var streamBuffer bytes.Buffer
// 使用 json.Encoder 来写入流,写入后自动添加换行符
encoder := json.NewEncoder(&streamBuffer)
for _, user := range users {
encoder.Encode(user)
}
// 使用 bufio.Scanner 按行读取,非常高效
scanner := bufio.NewScanner(&streamBuffer)
for scanner.Scan() {
line := scanner.Bytes()
var user User
// 使用 json.Unmarshal 解析单行
json.Unmarshal(line, &user)
}
}标准大型 JSON
decoder.Token():读取 JSON 流中的下一个标记 ,包括json.Delim( {}以及[] )、key、value。调用后游标会精确地移动到下一个标记的开始位置go// Delimiter: "{" // String: "name" // String: "Alice" // String: "age" // Number: 30.000000 // String: "is_active" // Bool: true // Delimiter: "}" jsonStr := `{"name": "Alice", "age": 30, "is_active": true}` decoder := json.NewDecoder(strings.NewReader(jsonStr)) for { token, err := decoder.Token() switch v := token.(type) { case json.Delim: fmt.Printf("Delimiter: %q\n", v) // 会打印 '{' 和 '}' case string: fmt.Printf("String: %q\n", v) // 会打印 "name", "Alice", "age" case float64: fmt.Printf("Number: %f\n", v) // 会打印 30.000000 case bool: fmt.Printf("Bool: %t\n", v) // 会打印 true } }decoder.More():判断是否还有更多元素,如果下一个非空白字符不是当前容器的结束符(}或]),它就返回true;否则返回false。游标不会移动。decoder.Decode(v interface{}):读取一个完整的Json值,可以是一个简单的数字、字符串,也可以是一个复杂的对象或数组。解码成功后,游标会移动到刚刚解码的值的末尾。例如,如果它解码了一个对象,游标会移动到该对象的匹配}之后。
// 简单流式处理案例
func main() {
decoder := json.NewDecoder(bytes.NewReader([]byte(jsonData)))
// 1. 读取根对象的开始 '{'
_, _ = decoder.Token()
// 2. 遍历根对象的所有键值对
for decoder.More() {
// 读取键名
keyToken, _ := decoder.Token()
key := keyToken.(string)
// 捕获原始值
var rawValue json.RawMessage
// Decode 会将值完整地读入 rawValue,但不解析它
if err := decoder.Decode(&rawValue); err != nil {
log.Printf("Failed to decode raw value for key '%s': %v", key, err)
continue
}
// 后续处理
}
// 5. 读取根对象的结束 '}'
_, _ = decoder.Token()
}其他
扁平化
使用匿名嵌套结构体,其内部属性会被扁平化,编解码时不会有对应的嵌套层级。
type Person struct {
ID uint
Name string
address
}
type address struct {
Code int
Street string
}
// 输出,嵌套层级将会消失
//{
// "ID": 1,
// "Name": "Bruce",
// "Code": 100,
// "Street": "Main St"
//}
func MarshalPerson() {
p := Person{
ID: 1,
Name: "Bruce",
address: address{
Code: 100,
Street: "Main St",
},
}
output, _ := json.MarshalIndent(p, "", " ")
println(string(output))
}脏数据污染
同一个结构体去反复反序列化不同的 JSON 数据时,一旦某个 JSON 数据的值只包含部分成员字段的,那么未被覆盖到的成员就会残留上一次反序列化的值。
// {ID:1 Name:Bruce}
// {ID:1 Name:Jim}
func main() {
var p Person
// 第一个数据有 ID 字段,且不为 0
str := `{"ID":1,"Name":"Bruce"}`
_ = json.Unmarshal([]byte(str), &p)
fmt.Printf("%+v\n", p)
// 第二个数据没有 ID 字段,再次用 p 反序列化,会保留上次的值
str = `{"Name":"Jim"}`
_ = json.Unmarshal([]byte(str), &p)
// 注意输出的 ID 仍然是 1
fmt.Printf("%+v\n", p)
}指针成员
目的是用于区分“零值”与“未提供”
type Person struct {
Name string
Age *int `json:"age,omitempty"` // 年龄是可选的,使用指针,为nil时忽略该字段
Address *Address `json:"age,omitempty"` // 地址是可选的嵌套结构体,也使用指针,为nil时忽略该字段
}
type Address struct {
City string
Street string
}
// JSON字段缺失或者JSON字段为null,反序列化时对应字段将为nil
// p.Name -> "Alice" 、p.Age -> nil、p.Address -> nil
{
"Name": "Alice"
}
{
"Name": "Alice",
"Age": null,
"Address": null
}
// JSON字段为nil,序列化时将会序列化为null文件操作
函数中name表示相对或者绝对路径。
创建与打开
下方创建与打开操作,需要在defer中调用file.Close()释放资源
os.Open(name string) (*os.File, error): 以只读模式打开一个文件。os.Create(name string) (*os.File, error): 以读写模式创建一个文件。如果文件已存在,会清空;如果不存在,则创建。文件权限默认为0666(所有人可读写)os.OpenFile(name string, flag int, perm FileMode) (*os.File, error)按照指定的模式(flag,标志位的组合,通过|拼接)和权限(perm,通常使用三位八进制表示)打开文件,权限只在创建文件时生效。os.O_RDONLY: 只读os.O_WRONLY: 只写os.O_RDWR: 读写os.O_CREATE: 如果不存在,则创建os.O_APPEND: 追加写入os.O_TRUNC: 打开时清空文件(需与写权限配合)os.O_EXCL: 与O_CREATE一起使用,确保文件是新建的,如果文件已存在则返回错误。
func main() {
// 1. 以只读方式打开一个已存在的文件(只读)
file, err := os.Open("example.txt")
if err != nil {
return
}
defer file.Close()
// 2. 创建或清空一个文件(读写)
newFile, err := os.Create("newfile.txt")
if err != nil {
return
}
defer newFile.Close()
// 3. 以追加模式打开文件(如果不存在则创建)
// 标志组合需合理(如O_RDONLY|O_WRONLY无效)
appendFile, err := os.OpenFile("logfile.log", os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0666)
if err != nil {
fmt.Println("Error opening file for append:", err)
return
}
defer appendFile.Close()
}写入
file.Write(b []byte) (n int, err error): 从文件当前偏移量开始,将字节切片写入文件并移动偏移量,返回实际写入的字节数。file.WriteString(s string) (n int, err error): 与Write相同,但是写入的是一个字符串。(f *File) WriteAt(b []byte, off int64) (n int, err error):从指定偏移处开始写入文件,不改变文件当前的偏移量。os.WriteFile(name string, data []byte, perm os.FileMode) error:一次性写入整个文件,文件不存在则创建,文件存在则完全覆盖,自动关闭文件。
func main() {
// 使用 os.Create 创建一个用于写入的文件
file, err := os.Create("output.txt")
defer file.Close()
// --- 方式1: 直接写入 ---
data := []byte("Hello, Go!\nThis is the first line.\n")
bytesWritten, err := file.Write(data)
// --- 方式2: 使用 WriteString ---
strWritten, err := file.WriteString("This is the second line.\n")
}读取
file.Read(b []byte) (n int, err error): 从文件当前偏移量处开始读取数据到字节切片并移动偏移量,返回实际读取的字节数(可能小于缓冲区大小),读到文件尾时返回io.EOF错误(f *File) ReadAt(b []byte, off int64) (n int, err error):从指定偏移处读取文件,不改变文件当前的偏移量。os.ReadFile(filename string) ([]byte, error): 一次性读取整个文件内容到一个字节切片中,自动打开和关闭文件。
func main() {
filename := "output.txt" // 假设这个文件已存在并有内容
// --- 方式1: 使用 os.ReadFile (最简单,适合小文件) ---
content, err := os.ReadFile(filename)
// --- 方式2: 使用 file.Read (手动循环) ---
file, err := os.Open(filename)
defer file.Close()
// 创建一个缓冲区来存储读取的数据
buf := make([]byte, 32) // 每次最多读取32字节
for {
n, err := file.Read(buf)
if err != nil && err != io.EOF {
fmt.Println("Error reading file:", err)
return
}
if n == 0 { // 读取到文件末尾
break
}
}
}bufio缓冲I/O
Reader:从底层读取器批量读取数据到缓冲区,后续读取直接从缓冲区获取
Writer:将多次小量写入累积到缓冲区,缓冲区满或Flush时批量写入底层
bufio.Reader
bufio.NewReader(rd io.Reader) *bufio.Reader:创建带缓冲的读取器,减少系统调用,默认缓冲区大小4096字节。gofile, _ := os.Open("data.txt") reader := bufio.NewReader(file) // 指定缓冲区大小 bigReader := bufio.NewReaderSize(file, 8192) // 8KB缓冲区(b *Reader) Read(p []byte) (n int, err error):优先从缓冲区读取,不足时从底层读取,返回实际读取字节数,缓冲区无数据且底层返回EOF时返回io.EOF。gobuffer := make([]byte, 1024) n, err := reader.Read(buffer)(b *Reader) ReadByte() (byte, error):读取单个字节,常用于解析二进制格式。gofor { b, err := reader.ReadByte() if err == io.EOF { break } // 处理单个字节 }(b *Reader) ReadLine() (line []byte, isPrefix bool, err error):内部缓冲区默认最大4096字节,行超过缓冲区大小时,isPrefix=true,需多次读取,不保留换行符(\n或\r\n)gofor { line, isPrefix, err := reader.ReadLine() if err == io.EOF { break } if isPrefix { // 行太长,需要继续读取剩余部分 continue } // 处理完整行 }(b *Reader) ReadString(delim byte) (string, error):读取直到遇见指定分隔符。go// 读取直到遇到换行符 line, err := reader.ReadString('\n') if err != nil && err != io.EOF { log.Fatal(err) } // 去掉换行符 line = strings.TrimRight(line, "\r\n")(b *Reader) Peek(n int) ([]byte, error):预览数据但不移动文件偏移量,返回的切片是内部缓冲区的引用。go// 预览前10个字节但不消耗 peekBytes, err := reader.Peek(10) if err == nil && string(peekBytes) == "START" { // 匹配到特定前缀 }
bufio.Writer
bufio.NewWriter(w io.Writer) *bufio.Writer:创建带缓冲的写入器,批量写入减少系统调用,默认缓冲区4096字节,必须调用Flush() 确保数据写入底层gofile, _ := os.Create("output.txt") writer := bufio.NewWriter(file) // 指定缓冲区大小 bigWriter := bufio.NewWriterSize(file, 16384) // 16KB缓冲区 defer writer.Flush() // 重要:确保数据写入(b *Writer) Write(p []byte) (nn int, err error):数据先写入缓冲区,缓冲区满时自动Flush,返回的n总是len(p)(除非出错)。godata := []byte("Hello, World!") n, err := writer.Write(data) // 数据可能还在缓冲区,需要Flush(b *Writer) WriteString(s string) (int, error):同Write,但写入的是字符串到缓冲区(b *Writer) WriteByte(c byte) error:写入单个字节(b *Writer) Flush() error:将缓冲区数据写入底层写入器
bufio.ReaderWriter
bufio.NewReadWriter(r *Reader, w *Writer) *ReadWriter:组合Reader和Writer,方便双向缓冲,读写使用独立的缓冲区gofile, _ := os.OpenFile("data.txt", os.O_RDWR, 0644) reader := bufio.NewReader(file) writer := bufio.NewWriter(file) rw := bufio.NewReadWriter(reader, writer) // 使用同一个结构体进行读写 line, _ := rw.ReadString('\n') rw.WriteString("New line\n") rw.Flush()
filepath
filepath.Join(elem ...string) string:智能拼接路径元素,自动处理路径分隔符go// 跨平台路径拼接 path := filepath.Join("dir", "subdir", "file.txt") // Linux: "dir/subdir/file.txt" // Windows: "dir\subdir\file.txt" // 正确处理多余分隔符和"." path2 := filepath.Join("dir//", "./sub", "..", "file.txt") // 返回: "dir/file.txt"filepath.Clean(path string) string:移除多余分隔符和"."、"..",返回最短等价路径go// 清理路径 clean1 := filepath.Clean("dir/../dir/file.txt") // "dir/file.txt" ,../dir和前方dir是同一个目录,所以去除 clean2 := filepath.Clean("dir//sub/./file.txt") // "dir/sub/file.txt" clean3 := filepath.Clean("/../file.txt") // "/file.txt"(Unix)filepath.Split(path string) (dir, file string):分离目录和文件名部分。godir, file := filepath.Split("/home/user/file.txt") // dir = "/home/user/", file = "file.txt" dir2, file2 := filepath.Split("file.txt") // dir2 = "", file2 = "file.txt"filepath.Ext(path string) string:获取文件扩展名,隐藏文件(如".gitignore")返回空goext := filepath.Ext("document.tar.gz") // ".gz" ext2 := filepath.Ext("file.txt") // ".txt" ext3 := filepath.Ext("noext") // ""filepath.Match(pattern, name string) (matched bool, err error):文件名正则匹配go// 通配符匹配 match, _ := filepath.Match("*.go", "main.go") // true match, _ := filepath.Match("test*.go", "test1.go") // true // 字符类 match, _ := filepath.Match("file[0-9].txt", "file1.txt") // true // 目录匹配 match, _ := filepath.Match("src/*/*.go", "src/pkg/file.go") // truefilepath.Glob(pattern string) (matches []string, err error):根据模式查找匹配的文件go// 当前工作目录下,查找所有Go文件 files, err := filepath.Glob("*.go") // ./test子文件夹里找 `.txt` 文件 files, err := filepath.Glob("test/*.txt") // 在绝对路径 `/home/user/` 里找 `.log` 文件 files, err := filepath.Glob("/home/user/*.log")
目录操作
创建目录
os.Mkdir(name string, perm FileMode) error: 创建单个目录。os.MkdirAll(path string, perm FileMode) error: 递归创建多级目录,如果父目录不存在会一并创建。
读取目录内容
os.ReadDir(dirname string) ([]DirEntry, error): 读取目录内容,返回目录项列表,不递归读取子目录。
删除目录
os.Remove(name string): 删除空目录。os.RemoveAll(path string) error: 递归删除目录及其所有子目录和文件。
其他
os.Stat(filename)\file.Stat():获取文件、目录信息gofileInfo, err := os.Stat("output.txt") // 判断文件是否存在 if os.IsNotExist(err) { return false } // 获取文件信息 fmt.Println("File Name:", fileInfo.Name()) fmt.Println("Size:", fileInfo.Size(), "bytes") fmt.Println("Permissions:", fileInfo.Mode()) fmt.Println("Last Modified:", fileInfo.ModTime()) fmt.Println("Is Directory?", fileInfo.IsDir())os.Rename(oldname, newname string) error:重命名与移动文件go// 基本用法:重命名文件 err := os.Rename("old.txt", "new.txt") // 移动文件到不同目录 err := os.Rename("file.txt", "/tmp/file.txt") // 重命名目录 err := os.Rename("olddir", "newdir")(f *File) Seek(offset int64, whence int) (ret int64, err error):移动文件偏移量位置,支持随机访问。go// offset:偏移量,whence初始位置。 // 移动到文件开头 pos, err := file.Seek(0, io.SeekStart) // 移动到文件末尾(用于追加) pos, err := file.Seek(0, io.SeekEnd) // 相对当前位置移动 pos, err := file.Seek(-100, io.SeekCurrent)(f *File) Truncate(size int64) error:截断/拓展文件,新大小小于原大小:截断;新大小大于原大小:用零填充扩展。go// 截断文件为100字节 err := file.Truncate(100)func Walk(root string, walkFn WalkFunc) error:从root目录开始,深度优先遍历整个文件系统树,对遇到的每一个文件或目录(包括根目录本身)调用一次walkFn回调函数go// WalkFunc 是回调函数的类型定义 type WalkFunc func(path string, info os.FileInfo, err error) error err := filepath.Walk("/tmp/myproject", func(path string, info os.FileInfo, err error) error { if err != nil { …… } // 当 err == nil 时有效。通过 info.IsDir(), info.Name(), info.Size(), info.Mode() 等获取详细信息。 fmt.Printf("找到: %s (目录: %v, 大小: %v)\n", path, info.IsDir(), info.Size()) // 返回 nil:继续正常遍历。 // 返回 filepath.SkipDir,对于文件则提前退出当前所在的这一层目录;对与目录则不进入这个目录 // 返回任何其他 error:立即终止整个 Walk 过程,并将这个错误作为 Walk 的返回值。 return nil })filepath.WalkDir(root string, walkFn WalkFunc) error:与Walk在功能上等价,但WalkDir在性能上通常更优。filepath.Walk:在遍历每个目录时,它会先调用os.Readdir来获取目录下的文件名列表。然后,对于每一个文件/子目录,它都会额外执行一次Lstat系统调用,来获取该文件的详细信息填充一个os.FileInfo结构体。filepath.WalkDir:在遍历目录时,它直接调用底层的ReadDir系统调用。其在一次操作中就能返回目录下所有条目的基本信息, 避免了为每个文件单独调用Lstat
go// WalkDirFunc 是回调函数的类型定义 type WalkDirFunc func(path string, d fs.DirEntry, err error) err := filepath.WalkDir(rootDir, func(path string, d fs.DirEntry, err error) error { if err != nil { return err } // 直接通过 DirEntry 判断类型,无需调用 Info() if d.IsDir() { fmt.Printf("目录: %s\n", path) } else { // 只在需要时获取详情 info, _ := d.Info() fmt.Printf("文件: %s, 大小: %d\n", path, info.Size()) } return nil })
网络编程
TCP
方法
net.Listener:服务端负责监听一个指定的IP地址和端口,等待客户端的连接请求。
func Listen(network, address string) (Listener, error):创建一个监听器。network可选项如下:tcp(自动选择IPv4或IPv6)、tcp4(仅支持IPv4)、tcp6(仅支持IPv6)address是"host:port",如":8080"表示监听本机所有IP的8080端口。
Accept() (Conn, error):阻塞等待,直到一个新的客户端连接进来,然后返回一个代表该连接的Conn对象。
net.Conn:一个具体的通信连接,代表一个双向的数据通道。
Read(b []byte) (n int, err error):从连接中读取数据到字节数组b中。Write(b []byte) (n int, err error):将字节数组b中的数据写入连接。Close() error:关闭连接。RemoteAddr() Addr:获取对端的网络地址。LocalAddr() Addr:获取本地的网络地址。SetDeadline(t time.Time): 设置读写总超时。SetReadDeadline(t time.Time): 设置读超时。SetWriteDeadline(t time.Time): 设置写超时。
net.Dial():客户端连接服务端。
func Dial(network, address string) (Conn, error):向指定的network和address发起连接,成功则返回一个Conn对象。
基本案例
服务端
// handleConnection 处理单个连接的逻辑
func handleConnection(conn net.Conn) {
defer conn.Close() // 确保函数结束时关闭连接
// 设置读写超时,传入未来时间点
conn.SetDeadline(time.Now().Add(30 * time.Second))
// 使用bufio可以方便地按行读取
reader := bufio.NewReader(conn)
for {
// 读取客户端发送的数据
message, err := reader.ReadString('\n') // 直到读到换行符
if err != nil {
// io.EOF 表示连接被对方正常关闭
if err.Error() == "EOF" {
fmt.Println("客户端", conn.RemoteAddr(), "断开连接")
} else {
fmt.Println("读取数据失败:", err)
}
return // 退出处理,关闭连接
}
// 回复客户端
response := "消息已收到: " + message
conn.Write([]byte(response))
}
}
func main() {
listener, _ := net.Listen("tcp", ":8080")
defer listener.Close()
for {
conn, _ := listener.Accept()
go handleConnection(conn)
}
}客户端
func main() {
// 1. 连接到服务器
conn, _ := net.Dial("tcp", "localhost:8080")
defer conn.Close()
// 启动一个goroutine来读取服务器返回的消息
go readServerResponse(conn)
// 主goroutine负责读取用户输入并发送
reader := bufio.NewReader(os.Stdin)
for {
input, _ := reader.ReadString('\n')
input = strings.TrimSpace(input)
if input == "quit" {
break
}
// 发送消息给服务器
_, _ := conn.Write([]byte(input + "\n")) // 加上换行符,因为服务器用ReadString('\n')
}
}
// readServerResponse 持续读取服务器的响应
func readServerResponse(conn net.Conn) {
reader := bufio.NewReader(conn)
for {
response, _ := reader.ReadString('\n')
fmt.Print("服务器回复: " + response)
}
}粘包与半包
- 粘包:发送方发送的多个独立的数据包,而接收方一次性读取到了多个数据包的数据。
- 半包:发送方发送的一个完整数据包,在接收方可能被拆分成了多次才被读完。
接收方或者发送方均可能导致该问题:
- 在发送方时,多个应用层数据包在TCP层面可能被合并为一个TCP段发送,一个应用层数据包也可能被拆分为多个TCP段。
- 在接收方时,处理速度慢,未及时从缓冲区读取数据,或者网络延迟或拥塞导致多个包同时到达。上述原因导致多个包在缓冲区粘连。
解决方案主要如下:
使用特殊分隔符:在每个消息的末尾加上一个特殊的、不会在消息正文中出现的分隔符,接收方直到遇到这个分隔符,才确定读取完一个消息。
消息头 + 消息体:消息头固定长度,携带消息体的长度;而消息体长度不固定,携带实际要传输的数据。
go// 发送方 func sendMessage(conn net.Conn, msg string) error { // 1. 将消息长度写入一个4字节的slice lenBytes := make([]byte, 4) binary.BigEndian.PutUint32(lenBytes, uint32(len(msg))) // 2. 先发送长度 if _, err := conn.Write(lenBytes); err != nil { return err } // 3. 再发送消息体 if _, err := conn.Write([]byte(msg)); err != nil { return err } return nil } // 接收方 func readMessage(conn net.Conn) (string, error) { // 1. 先读取4字节的长度 lenBytes := make([]byte, 4) if _, err := io.ReadFull(conn, lenBytes); err != nil { // io.ReadFull确保读满指定长度 return "", err } msgLen := binary.BigEndian.Uint32(lenBytes) // 2. 再根据长度读取消息体 msgBytes := make([]byte, msgLen) if _, err := io.ReadFull(conn, msgBytes); err != nil { return "", err } return string(msgBytes), nil }
连接池
客户端使用连接池复用连接(服务端在与数据库、其他服务通信时也可以使用连接池)
// RealConnectionPool 真正的连接池
type RealConnectionPool struct {
factory func() (net.Conn, error) // 创建连接的工厂函数
pool chan net.Conn // 存放空闲连接的通道
maxSize int // 最大连接数
current int // 当前连接数
mu sync.Mutex
serverAddr string
}
// NewRealConnectionPool 创建连接池
func NewRealConnectionPool(serverAddr string, maxSize int) *RealConnectionPool {
return &RealConnectionPool{
factory: func() (net.Conn, error) {
return net.Dial("tcp", serverAddr)
},
pool: make(chan net.Conn, maxSize),
maxSize: maxSize,
serverAddr: serverAddr,
}
}
// Get 从池中获取连接
func (p *RealConnectionPool) Get() (net.Conn, error) {
select {
case conn := <-p.pool:
// 从池中获取空闲连接
return conn, nil
default:
// 池中没有空闲连接,创建新连接
p.mu.Lock()
if p.current >= p.maxSize {
p.mu.Unlock()
// 等待连接释放
conn := <-p.pool
return conn, nil
}
p.current++
p.mu.Unlock()
return p.factory()
}
}
// Put 将连接放回池中
func (p *RealConnectionPool) Put(conn net.Conn) {
select {
case p.pool <- conn:
// 成功放回池中
default:
// 池已满,关闭连接
conn.Close()
p.mu.Lock()
p.current--
p.mu.Unlock()
}
}
// Close 关闭连接池
func (p *RealConnectionPool) Close() {
close(p.pool)
for conn := range p.pool {
conn.Close()
}
}
// 使用真正的连接池
func useRealPool() {
pool := NewRealConnectionPool("example.com:80", 10)
defer pool.Close()
// 模拟并发请求
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
// 从池中获取连接
conn, _ := pool.Get()
// 使用连接
conn.Write([]byte(fmt.Sprintf("请求 %d\n", id)))
// 读取响应
buf := make([]byte, 1024)
n, _ := conn.Read(buf)
fmt.Printf("协程 %d: 收到响应: %s\n", id, buf[:n])
// 将连接放回池中
pool.Put(conn)
}(i)
}
wg.Wait()
}UDP
UDP不会出现半包和粘包的现象
- 两个独立的 UDP 数据报不会被操作系统合并成一个
- 而对于UDP 每一条消息都会构建一个UDP数据报,其包含了消息的边界,在读取端读取时:
- 如果你的
buffer足够大,它会完整地读取这个数据报。 - 如果你的
buffer比数据报小,一次读取后剩下的部分会被直接丢弃。
- 如果你的
方法
net.ResolveUDPAddr(network, address string) (*net.UDPAddr, error):将指定地址和端口解析为*net.UDPAddr 对象。
network:"udp"、"udp4"(仅IPv4)或"udp6"(仅IPv6)。address: 地址字符串。如果只写:8080,表示监听本机的所有可用网络接口的 8080 端口。
net.ListenUDP(network string, laddr *net.UDPAddr) (*net.UDPConn, error):服务端用于创建监听对应端口UDP套接字,返回 *net.UDPConn,用于读写操作。
net.DialUDP(network string, laddr, raddr *net.UDPAddr) (*net.UDPConn, error) :客户端用于连接远程服务器的函数。
laddr: 客户端的本地地址,通常设为nil,让系统自动选择。raddr: 服务器的远程地址,必须指定。
net.UDPConn:代表一个 UDP 连接,实现了 Conn 和 PacketConn 接口,用于读写数据。
ReadFromUDP(b []byte) (n int, addr *net.UDPAddr, err error):从连接中读取一个数据报到b中,返回读取的字节数n和发送方的 UDP 地址addr。WriteToUDP(b []byte, addr *net.UDPAddr) (n int, err error):将数据b发送到指定的 UDP 地址addr。Read(b []byte) (n int, err error):从连接中读取数据。- 如果这个
UDPConn是通过DialUDP创建的(客户端),它知道服务端的地址,会从默认的远程地址读取数据。 - 如果这个
UDPConn是通过ListenUDP创建的(服务端),它无法确定读取到的数据是哪一个客户端的连接。
- 如果这个
Write(b []byte) (n int, err error):将数据b写入连接。如果是客户端会直接将数据发送到服务端,如果是服务端会直接抛错,原因同Read。Close() error:关闭连接,释放资源。
基本案例
服务端
func concurrentUDPServer() {
addr, _ := net.ResolveUDPAddr("udp", ":8080")
conn, _ := net.ListenUDP("udp", addr)
defer conn.Close()
for {
buffer := make([]byte, 1024)
n, clientAddr, err := conn.ReadFromUDP(buffer)
if err != nil {
continue
}
// 为每个请求启动一个goroutine处理
go handleUDPRequest(conn, clientAddr, buffer[:n])
}
}
func handleUDPRequest(conn *net.UDPConn, addr *net.UDPAddr, data []byte) {
// 处理逻辑
response := fmt.Sprintf("处理结果: %s", string(data))
conn.WriteToUDP([]byte(response), addr)
}客户端
func main() {
// 1. 解析服务器地址
serverAddr, _ := net.ResolveUDPAddr("udp", ":8080")
// 2. 建立UDP连接
conn, _ := net.DialUDP("udp", nil, serverAddr)
defer conn.Close()
// 3. 发送数据
message := []byte("Hello, UDP Server!")
_, _ = conn.Write(message)
// 4. 设置读取超时
conn.SetReadDeadline(time.Now().Add(5 * time.Second))
// 5. 接收响应
buffer := make([]byte, 1024)
conn.ReadFromUDP(buffer)
}HTTP
快捷请求
// Get 请求
func main() {
// 构建URL参数
params := url.Values{}
params.Add("page", "1")
params.Add("limit", "10")
// 创建URL
apiUrl := "https://api.example.com/data?" + params.Encode()
resp, _ := http.Get(apiUrl)
defer resp.Body.Close() // 必须关闭响应体以释放资源
body, _ := io.ReadAll(resp.Body) // 读取整个响应体内容,响应体是一个流,可以使用流的方式读取。
fmt.Println(resp.Status) // 响应状态码
fmt.Println(string(body)) // 响应内容
}
// Post 请求,JSON格式
func main() {
user := User{
Name: "张三",
Email: "zhangsan@example.com",
}
jsonData, _ := json.Marshal(user) // 编码为JSON
// 发送POST请求
resp, _ := http.Post(
"https://api.example.com/users",
"application/json",
bytes.NewBuffer(jsonData),
)
defer resp.Body.Close()
// 处理响应
body, _ := io.ReadAll(resp.Body)
fmt.Printf("响应: %s\n", body)
}
// POST请求,表单格式
func main() {
// 准备表单数据
formData := url.Values{}
formData.Set("username", "zhangsan")
formData.Set("password", "secret123")
// 发送表单请求
resp, _ := http.PostForm("https://api.example.com/login", formData)
defer resp.Body.Close()
body, _ := io.ReadAll(resp.Body)
fmt.Printf("登录响应: %s\n", body)
}高级客户端配置
func main() {
// 创建自定义HTTP客户端,配置对该客户端发起所有请求均生效,可以配置超时、连接池等
/*
client := &http.Client{
Timeout: 10 * time.Second, // 设置整个请求(包括连接、重定向、读取响应体)的总超时时间
// 所有通过该客户端发送的请求均受到该限制
Transport: &http.Transport{
MaxIdleConns: 100, // 最大空闲连接数
IdleConnTimeout: 90 * time.Second, // 空闲连接超时
TLSHandshakeTimeout: 10 * time.Second, // TLS握手超时
TLSClientConfig: &tls.Config{
InsecureSkipVerify: true, // 跳过证书验证(仅测试环境使用)
},
},
}
*/
client := &http.Client{}
// 设置请求方式、路径、请求体
req, _ := http.NewRequest("GET", "https://api.example.com/data", nil)
// 设置请求头
req.Header.Set("Authorization", "Bearer your-token-here")
req.Header.Set("User-Agent", "MyGoClient/1.0")
// 创建带超时的上下文,精确控制单次请求超时
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
req = req.WithContext(ctx)
// 发送请求
resp, _ := client.Do(req)
defer resp.Body.Close()
// 读取
body, _ := io.ReadAll(resp.Body)
fmt.Println(string(body))
}
// 文件上传,通过表单形式携带文件数据
func main() {
// 打开要上传的本地文件
file, _ := os.Open("example.txt")
defer file.Close()
// 初始化multipart/form-data请求体的缓冲区和写入器
body := &bytes.Buffer{}
writer := multipart.NewWriter(body)
// 创建表单文件字段,并将本地文件的内容复制到文件表单字段中
part, _ := writer.CreateFormFile("file", "example.txt")
_, _ = io.Copy(part, file)
// 向表单中添加普通文本字段
_ = writer.WriteField("description", "这是一个示例文件")
// 关闭multipart写入器,完成表单数据的构建(会写入结束边界符)
writer.Close()
req, _ := http.NewRequest("POST", "https://api.example.com/upload", body)
// 7. 设置请求头的Content-Type为multipart/form-data
req.Header.Set("Content-Type", writer.FormDataContentType())
client := &http.Client{}
resp, _ := client.Do(req)
defer resp.Body.Close()
responseBody, _ := io.ReadAll(resp.Body)
fmt.Printf("上传响应: %s\n", responseBody)
}其他
heap
container/heap实现了堆,但使用前需要实现 heap.Interface 接口,它继承了 sort.Interface,包含以下五个方法:
Len() int:返回堆的元素数量。Less(i, j int) bool:比较索引 i 和 j 的元素优先级。Swap(i, j int):交换 i 和 j 索引处的元素。Push(x any):将 x 添加到堆中。Pop() any:从堆顶移除并返回元素。
type Interface interface {
sort.Interface // Len, Less, Swap
Push(x any) // add x as element Len()
Pop() any // remove and return element Len() - 1
}heap的方法如下
Init(h Interface):初始化堆。Push(h Interface, x any):向堆中添加元素。Pop(h Interface) any:从堆顶移除元素。Fix(h Interface, i int):当元素 i 的值改变后,重新调整堆。Remove(h Interface, i int) any:删除堆中指定索引的元素。
// 步骤1: 定义一个具体类型,并实现 heap.Interface 接口
type IntHeap []int
func (h IntHeap) Len() int { return len(h) }
func (h IntHeap) Less(i, j int) bool { return h[i] < h[j] } // 最小堆
func (h IntHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
// 注意:Push 和 Pop 必须使用指针接收者,因为它们会修改切片的长度
func (h *IntHeap) Push(x any) {
*h = append(*h, x.(int))
}
func (h *IntHeap) Pop() any {
old := *h
n := len(old)
x := old[n-1]
*h = old[0 : n-1]
return x
}
func main() {
// 步骤2: 创建具体类型的实例
h := &IntHeap{2, 1, 5} // 创建一个 IntHeap 实例并初始化
// 使用 heap 包的函数来操作这个实例
heap.Init(h) // 初始化堆,建立堆的性质
heap.Push(h, 3) // 内部会调用IntHeap实现的Push、Len、Less、Swap来向堆中添加元素,并保持堆的性质
for h.Len() > 0 {
// 内部会调用IntHeap实现的Pop、Len、Less、Swap来向堆中添加元素,并保持堆的性质
fmt.Printf("%d ", heap.Pop(h))
}
}list
container/list 实现了双向链表。
Element:链表元素,包含Value any(存储值)和前后指针。List:链表结构,零值即空链表,可以直接使用。New() *List:创建并初始化一个链表。PushFront(v any) *Element:在链表前端插入元素。PushBack(v any) *Element:在链表后端插入元素。InsertBefore(v any, mark *Element) *Element:在指定元素前插入。InsertAfter(v any, mark *Element) *Element:在指定元素后插入。Remove(e *Element) any:删除元素。go// 删除头尾元素 l.Remove(l.Front()) l.Remove(l.Back())Front() *Element/Back() *Element:获取头/尾元素。Len() int:获取链表长度。
Ring
container/ring 实现了循环链表(环形链表), 创建时就固定为 n 个元素,不能动态扩容。适合轮询、固定大小缓存池等场景。
- 负载均衡:将请求依次分配给多个服务器。
- 定时任务调度:按固定顺序轮询执行任务。
- 日志/事件缓存:只保留最近的 N 条日志或事件。
- 滑动窗口统计:如最近 N 秒的访问量统计。
ring 方法如下:
Ring:循环链表节点,每个节点都包含Value any和前后指针。New(n int) *Ring:创建一个长度为 n 的循环链表。Next() *Ring/Prev() *Ring:移动到下一个/上一个节点。Move(n int) *Ring:移动 n 步(正数向前,负数向后)。Link(s *Ring) *Ring:将两个环连接。Unlink(n int) *Ring:从当前节点开始删除 n 个节点。Do(f func(any)):对环中每个元素执行函数 f。
sync.Map
Go 语言内置的 map 类型不是并发安全的,在读取前后需要添加锁。
var myMap = make(map[string]int)
var mu sync.Mutex
func write(key string, value int) {
mu.Lock()
myMap[key] = value
mu.Unlock()
}
func read(key string) (int, bool) {
mu.Lock()
value, ok := myMap[key]
mu.Unlock()
return value, ok
}概述
sync.Map 的核心原理(实际实现比较复杂)是通过读写分离降低锁竞争:内部维护一个原子操作的只读映射(read)和一个需加锁的可写映射(dirty),读操作优先无锁访问 read,未命中时加锁访问 dirty 并记录一次未命中(misses),当 misses 累计到一定阈值时触发 dirty 向 read 的同步更新,适用于读多写少(写多读少的场景,其性能可能不如 map + sync.RWMutex)
- read map:一个只读的 map。它的访问是原子操作,完全无锁。存储的
entry是一个特殊的指针,其有三种状态:- nil - 表示已删除,但key可能仍在dirty map中
- expunged - 特殊标记,表示key已从dirty map中删除
- 指向实际值的指针 - 活跃状态
- dirty map:一个可读写的 map。对它的访问需要加锁。
- misses 计数器:记录从 read map 中读取失败的次数。
方法
Store(key, value interface{}):存储或更新键值对。Load(key interface{}) (value interface{}, ok bool):读取指定键的值。LoadOrStore(key, value interface{}) (actual interface{}, loaded bool):复合操作。读取键的值,若不存在则存储给定值并返回。LoadAndDelete(key interface{}) (value interface{}, loaded bool):删除指定键并返回其之前的值(如果存在)。这是Delete的增强版。Delete(key interface{}):删除指定键。Range(f func(key, value interface{}) bool):遍历所有键值对,并对每个键值对调用函数f。如果f返回false,则停止遍历。Clear():清空所有键值对。
sync.Pool
概述
增加临时对象的重用率,减少 GC 负担,适用于短生命周期、无状态或状态可以轻易重置(socket 长连接或数据库连接池就不适用)
- Pool 池里的元素随时可能释放掉,释放策略完全由 runtime 内部管理。
- sync.Pool 本身的 Get, Put 调用是并发安全的,
sync.New指向的初始化函数会并发调用,需要自己控制; - 当用完一个从 Pool 取出的实例时候,一定要记得调用 Put,通常这个用 defer 完成;
方法
buffer := bufferPool.Get():返回 Pool 已经存在的对象,如果没有,则调用 New 方法初始化。bufferPool.Put(buffer):使用对象之后,调用 Put 方法声明把对象放回池子,此时不要继续使用该对象。
// 创建一个 Pool 实例,配置 New 方法(这个方法是可能被并发调用的,需要注意安全)
bufferpool := &sync.Pool {
New: func() interface {} {
println("Create new instance")
return struct{}{}
}
}